@
缓存的重要性是不言而喻的。 使用缓存, 我们可以避免频繁的与数据库进行交互, 尤其是在查询越多、缓存命中率越高的情况下, 使用缓存对性能的提高更明显。
mybatis 也提供了对缓存的支持, 分为一级缓存和二级缓存。 但是在默认的情况下, 只开启一级缓存(一级缓存是对同一个 SqlSession 而言的)。
以下的项目是在mybatis 初步使用(IDEA的Maven项目, 超详细)的基础上进行。
对以下的代码, 你也可以从我的GitHub中获取相应的项目。
1 一级缓存
同一个
SqlSession对象, 在参数和 SQL 完全一样的情况先, 只执行一次 SQL 语句(如果缓存没有过期)
也就是只有在参数和 SQL 完全一样的情况下, 才会有这种情况。
1.1 同一个 SqlSession
@Test
public void oneSqlSession() {
SqlSession sqlSession = null;
try {
sqlSession = sqlSessionFactory.openSession();
StudentMapper studentMapper = sqlSession.getMapper(StudentMapper.class);
// 执行第一次查询
List<Student> students = studentMapper.selectAll();
for (int i = 0; i < students.size(); i++) {
System.out.println(students.get(i));
}
System.out.println("=============开始同一个 Sqlsession 的第二次查询============");
// 同一个 sqlSession 进行第二次查询
List<Student> stus = studentMapper.selectAll();
Assert.assertEquals(students, stus);
for (int i = 0; i < stus.size(); i++) {
System.out.println("stus:" + stus.get(i));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (sqlSession != null) {
sqlSession.close();
}
}
}
在以上的代码中, 进行了两次查询, 使用相同的 SqlSession, 结果如下
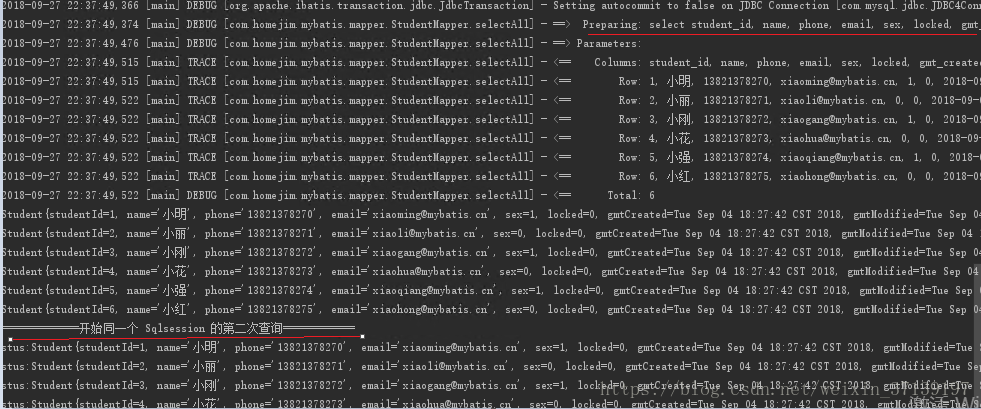
在日志和输出中:
第一次查询发送了 SQL 语句, 后返回了结果;
第二次查询没有发送 SQL 语句, 直接从内存中获取了结果。
而且两次结果输入一致, 同时断言两个对象相同也通过。
1.2 不同的 SqlSession
@Test
public void differSqlSession() {
SqlSession sqlSession = null;
SqlSession sqlSession2 = null;
try {
sqlSession = sqlSessionFactory.openSession();
StudentMapper studentMapper = sqlSession.getMapper(StudentMapper.class);
// 执行第一次查询
List<Student> students = studentMapper.selectAll();
for (int i = 0; i < students.size(); i++) {
System.out.println(students.get(i));
}
System.out.println("=============开始不同 Sqlsession 的第二次查询============");
// 从新创建一个 sqlSession2 进行第二次查询
sqlSession2 = sqlSessionFactory.openSession();
StudentMapper studentMapper2 = sqlSession2.getMapper(StudentMapper.class);
List<Student> stus = studentMapper2.selectAll();
// 不相等
Assert.assertNotEquals(students, stus);
for (int i = 0; i < stus.size(); i++) {
System.out.println("stus:" + stus.get(i));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (sqlSession != null) {
sqlSession.close();
}
if (sqlSession2 != null) {
sqlSession2.close();
}
}
}
在代码中, 分别使用 sqlSession 和 sqlSession2 进行了相同的查询。
其结果如下
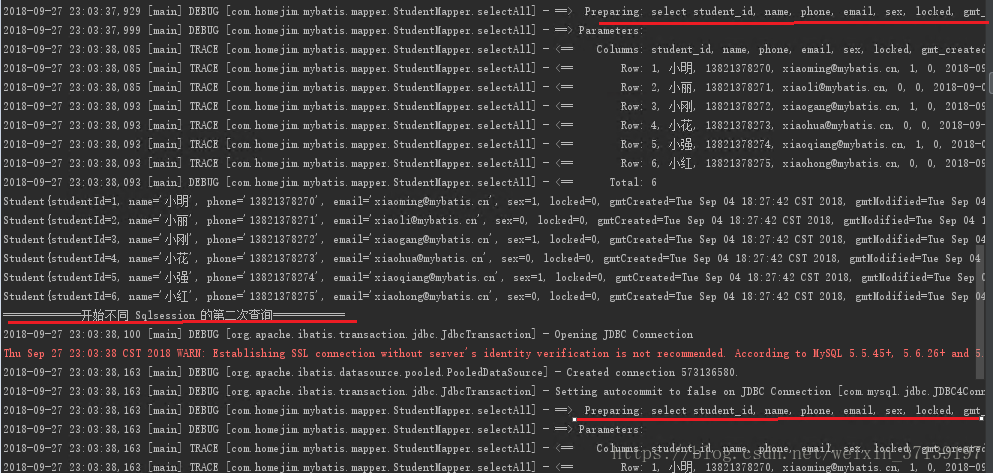
从日志中可以看到两次查询都分别从数据库中取出了数据。 虽然结果相同, 但两个是不同的对象。
1.3 刷新缓存
刷新缓存是清空这个 SqlSession 的所有缓存, 不单单是某个键。
@Test
public void sameSqlSessionNoCache() {
SqlSession sqlSession = null;
try {
sqlSession = sqlSessionFactory.openSession();
StudentMapper studentMapper = sqlSession.getMapper(StudentMapper.class);
// 执行第一次查询
Student student = studentMapper.selectByPrimaryKey(1);
System.out.println("=============开始同一个 Sqlsession 的第二次查询============");
// 同一个 sqlSession 进行第二次查询
Student stu = studentMapper.selectByPrimaryKey(1);
Assert.assertEquals(student, stu);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (sqlSession != null) {
sqlSession.close();
}
}
}
如果是以上, 没什么不同, 结果还是第二个不发 SQL 语句。
在此, 做一些修改, 在 StudentMapper.xml 中, 添加
flushCache="true"
修改后的配置文件如下:
<select id="selectByPrimaryKey" flushCache="true" parameterType="java.lang.Integer" resultMap="BaseResultMap">
select
<include refid="Base_Column_List" />
from student
where student_id=#{id, jdbcType=INTEGER}
</select>
结果如下:
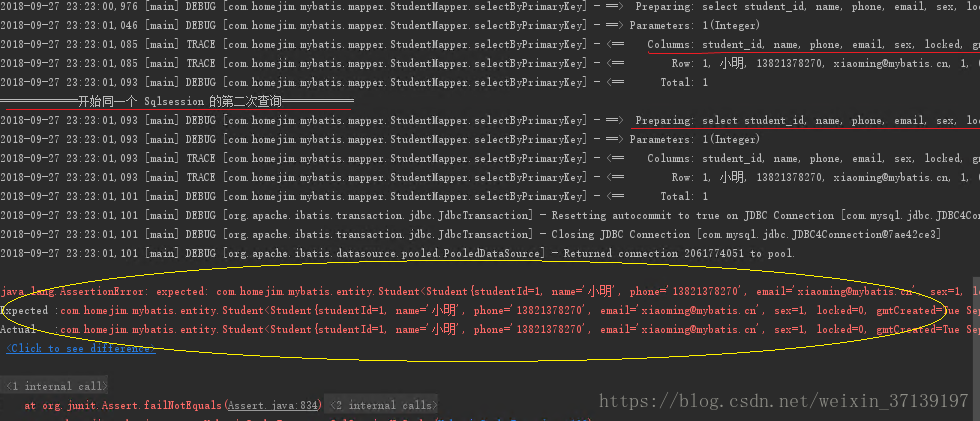
第一次, 第二次都发送了 SQL 语句, 同时, 断言两个对象相同出错。
1.4 总结
-
在同一个
SqlSession中, Mybatis 会把执行的方法和参数通过算法生成缓存的键值, 将键值和结果存放在一个 Map 中, 如果后续的键值一样, 则直接从 Map 中获取数据; -
不同的
SqlSession之间的缓存是相互隔离的; -
用一个
SqlSession, 可以通过配置使得在查询前清空缓存; -
任何的 UPDATE, INSERT, DELETE 语句都会清空缓存。
2 二级缓存
二级缓存存在于 SqlSessionFactory 生命周期中。
2.1 配置二级缓存
2.1.1 全局开关
在 mybatis 中, 二级缓存有全局开关和分开关, 全局开关, 在 mybatis-config.xml 中如下配置:
<settings>
<!--全局地开启或关闭配置文件中的所有映射器已经配置的任何缓存。 -->
<setting name="cacheEnabled" value="true"/>
</settings>
默认是为 true, 即默认开启总开关。
2.1.2 分开关
分开关就是说在 *Mapper.xml 中开启或关闭二级缓存, 默认是不开启的。
2.1.3 entity 实现序列化接口
public class Student implements Serializable {
private static final long serialVersionUID = -4852658907724408209L;
...
}
2.2 使用二级缓存
@Test
public void secendLevelCacheTest() {
// 获取 SqlSession 对象
SqlSession sqlSession = sqlSessionFactory.openSession();
// 获取 Mapper 对象
StudentMapper studentMapper = sqlSession.getMapper(StudentMapper.class);
// 使用 Mapper 接口的对应方法,查询 id=2 的对象
Student student = studentMapper.selectByPrimaryKey(2);
// 更新对象的名称
student.setName("奶茶");
// 再次使用相同的 SqlSession 查询id=2 的对象
Student student1 = studentMapper.selectByPrimaryKey(2);
Assert.assertEquals("奶茶", student1.getName());
// 同一个 SqlSession , 此时是一级缓存在作用, 两个对象相同
Assert.assertEquals(student, student1);
sqlSession.close();
SqlSession sqlSession1 = sqlSessionFactory.openSession();
StudentMapper studentMapper1 = sqlSession1.getMapper(StudentMapper.class);
Student student2 = studentMapper1.selectByPrimaryKey(2);
Student student3 = studentMapper1.selectByPrimaryKey(2);
// 由于我们配置的 readOnly="true", 因此后续同一个 SqlSession 的对象都不一样
Assert.assertEquals("奶茶", student2.getName());
Assert.assertNotEquals(student3, student2);
sqlSession1.close();
}
结果如下:
2018-09-29 23:14:26,889 [main] DEBUG [org.apache.ibatis.datasource.pooled.PooledDataSource] - Created connection 242282810.
2018-09-29 23:14:26,889 [main] DEBUG [org.apache.ibatis.transaction.jdbc.JdbcTransaction] - Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@e70f13a]
2018-09-29 23:14:26,897 [main] DEBUG [com.homejim.mybatis.mapper.StudentMapper.selectByPrimaryKey] - ==> Preparing: select student_id, name, phone, email, sex, locked, gmt_created, gmt_modified from student where student_id=?
2018-09-29 23:14:26,999 [main] DEBUG [com.homejim.mybatis.mapper.StudentMapper.selectByPrimaryKey] - ==> Parameters: 2(Integer)
2018-09-29 23:14:27,085 [main] TRACE [com.homejim.mybatis.mapper.StudentMapper.selectByPrimaryKey] - <== Columns: student_id, name, phone, email, sex, locked, gmt_created, gmt_modified
2018-09-29 23:14:27,085 [main] TRACE [com.homejim.mybatis.mapper.StudentMapper.selectByPrimaryKey] - <== Row: 2, 小丽, 13821378271, xiaoli@mybatis.cn, 0, 0, 2018-09-04 18:27:42.0, 2018-09-04 18:27:42.0
2018-09-29 23:14:27,093 [main] DEBUG [com.homejim.mybatis.mapper.StudentMapper.selectByPrimaryKey] - <== Total: 1
2018-09-29 23:14:27,093 [main] DEBUG [com.homejim.mybatis.mapper.StudentMapper] - Cache Hit Ratio [com.homejim.mybatis.mapper.StudentMapper]: 0.0
2018-09-29 23:14:27,108 [main] DEBUG [org.apache.ibatis.transaction.jdbc.JdbcTransaction] - Resetting autocommit to true on JDBC Connection [com.mysql.jdbc.JDBC4Connection@e70f13a]
2018-09-29 23:14:27,116 [main] DEBUG [org.apache.ibatis.transaction.jdbc.JdbcTransaction] - Closing JDBC Connection [com.mysql.jdbc.JDBC4Connection@e70f13a]
2018-09-29 23:14:27,116 [main] DEBUG [org.apache.ibatis.datasource.pooled.PooledDataSource] - Returned connection 242282810 to pool.
2018-09-29 23:14:27,124 [main] DEBUG [com.homejim.mybatis.mapper.StudentMapper] - Cache Hit Ratio [com.homejim.mybatis.mapper.StudentMapper]: 0.3333333333333333
2018-09-29 23:14:27,124 [main] DEBUG [com.homejim.mybatis.mapper.StudentMapper] - Cache Hit Ratio [com.homejim.mybatis.mapper.StudentMapper]: 0.5
以上结果, 分几个过程解释:
第一阶段:
- 在第一个
SqlSession中, 查询出student对象, 此时发送了 SQL 语句; student更改了name属性;SqlSession再次查询出student1对象, 此时不发送 SQL 语句, 日志中打印了 「Cache Hit Ratio」, 代表二级缓存使用了, 但是没有命中。 因为一级缓存先作用了。- 由于是一级缓存, 因此, 此时两个对象是相同的。
- 调用了
sqlSession.close(), 此时将数据序列化并保持到二级缓存中。
第二阶段:
- 新创建一个
sqlSession.close()对象; - 查询出
student2对象,直接从二级缓存中拿了数据, 因此没有发送 SQL 语句, 此时查了 3 个对象,但只有一个命中, 因此 命中率 1/3=0.333333; - 查询出
student3对象,直接从二级缓存中拿了数据, 因此没有发送 SQL 语句, 此时查了 4 个对象,但只有一个命中, 因此 命中率 2/4=0.5; - 由于
readOnly="true", 因此student2和student3都是反序列化得到的, 为不同的实例。
2.3 配置详解
查看 dtd 文件, 可以看到如下约束:
<!ELEMENT cache (property*)>
<!ATTLIST cache
type CDATA #IMPLIED
eviction CDATA #IMPLIED
flushInterval CDATA #IMPLIED
size CDATA #IMPLIED
readOnly CDATA #IMPLIED
blocking CDATA #IMPLIED
>
从中可以看出:
cache中可以出现任意多个property子元素;cache有一些可选的属性type,eviction,flushInterval,size,readOnly,blocking.
2.3.1 type
type 用于指定缓存的实现类型, 默认是PERPETUAL, 对应的是 mybatis 本身的缓存实现类 org.apache.ibatis.cache.impl.PerpetualCache。
后续如果我们要实现自己的缓存或者使用第三方的缓存, 都需要更改此处。
2.3.2 eviction
eviction 对应的是回收策略, 默认为 LRU。
-
LRU: 最近最少使用, 移除最长时间不被使用的对象。
-
FIFO: 先进先出, 按对象进入缓存的顺序来移除对象。
-
SOFT: 软引用, 移除基于垃圾回收器状态和软引用规则的对象。
-
WEAK: 弱引用, 移除基于垃圾回收器状态和弱引用规则的对象。
2.3.3 flushInterval
flushInterval 对应刷新间隔, 单位毫秒, 默认值不设置, 即没有刷新间隔, 缓存仅仅在刷新语句时刷新。
如果设定了之后, 到了对应时间会过期, 再次查询需要从数据库中取数据。
2.3.4 size
size 对应为引用的数量,即最多的缓存对象数据, 默认为 1024。
2.3.5 readOnly
readOnly 为只读属性, 默认为 false
-
false: 可读写, 在创建对象时, 会通过反序列化得到缓存对象的拷贝。 因此在速度上会相对慢一点, 但重在安全。
-
true: 只读, 只读的缓存会给所有调用者返回缓存对象的相同实例。 因此性能很好, 但如果修改了对象, 有可能会导致程序出问题。
2.3.6 blocking
blocking 为阻塞, 默认值为 false。 当指定为 true 时将采用 BlockingCache 进行封装。
使用 BlockingCache 会在查询缓存时锁住对应的 Key,如果缓存命中了则会释放对应的锁,否则会在查询数据库以后再释放锁,这样可以阻止并发情况下多个线程同时查询数据。
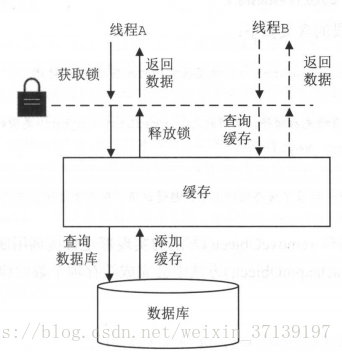
2.4 注意事项
-
由于在更新时会刷新缓存, 因此需要注意使用场合:查询频率很高, 更新频率很低时使用, 即经常使用 select, 相对较少使用delete, insert, update。
-
缓存是以 namespace 为单位的,不同 namespace 下的操作互不影响。但刷新缓存是刷新整个 namespace 的缓存, 也就是你 update 了一个, 则整个缓存都刷新了。
-
最好在 「只有单表操作」 的表的 namespace 使用缓存, 而且对该表的操作都在这个 namespace 中。 否则可能会出现数据不一致的情况。
一起学 mybatis
你想不想来学习 mybatis? 学习其使用和源码呢?那么, 在博客园关注我吧!!
我自己打算把这个源码系列更新完毕, 同时会更新相应的注释。快去 star 吧!!