接上一篇文章。现在写程序,做项目不是说功能做完就完事了,在平常的开发过程中对于性能的考虑也是极其重要的。
关于ef的那些事,今天就来说说吧。首先必须得知道.net ef在程序中的五种状态变化过程与原理。
主要来说说查询部分的性能优化,在所有查询中,客户端查询出来的数据一般来说是不需要进行跟踪的。也就是说查询只是给用户看,不做其他任何操作。对于基于B/S模式的项目网站开发,应该是无状态的,也就是ef中的游离态(Unchanged)(个人理解)。如果是C/S可能还需要进行其他连接的状态。通俗的说,在开发过程不用去检测某一个属性或者类是否被修改或者删除。
例如:
AsNoTracking:它的作用就是在查询的过程中不被缓存,也就是不被保留,查出来就完事了,这样的状态就变成了Detached游离态
//AsNoTracking:它的性能比ToList快大约4.8倍,不被缓存的数据。 var item=db.Book.AsNoTracking().First(m=>m.Id==1); Console.WriteLine(db.Entry(item).State); //输出Detached(游离态)
去掉AsNoTracking
var item=db.Book.First(m=>m.Id==1); Console.WriteLine(db.Entry(item).State); //输出UnChanged(持久态)
也就是加上AsNoTracking做出来的查询操作,就和数据库断绝了关系(个人理解)这样对性能也是一个极好的优化。
然后来说说在项目中对ef整体框架优化的使用。
C#是一门面向对象的语言无外乎就是封装、继承、多态。。。类可以继承类,同样接口也可以继承接口。面向对象的思想就是每张表都应该有一个父类,只写一遍,其他类继承就好了不用重复去写。
建立一个空白的解决方案,添加一个名为BaseEntity的类,你可以把它看做是所有类的基础类(父类)。

重点来说说这个BaseEntity为什么要作为基础类,它的用意何在。
先看看里面的写了些什么吧!
以前用int或者long作为主键自增长的数据类型,这样后期数据非常庞大的时候可能会无法预估难免可能会出现重复的数据,这个时候对于整个系统来说就无法保障了。
Guid给我做出了一个计算,它是32位的数字加字母的组合,而且是特别长的不会重复的自增数,可以这样去理解。
DateTime就是每条数据的创建时间,IsRemove就是作为数据逻辑删除的标识,也就是说,每个类(表)都会存在这三个字段属性。你可以通过DateTime对没张表进行排序的操作。
using System; namespace Book.Models { public class BaseEntity { public Guid Id { get; set; }=Guid.NewGuid(); //计算32位,字母加数字,特别长的,不重复的,自增数 public DateTime DateTime { get; set; }=DateTime.Now; //每条数据的创建时间 public bool IsRemove { get; set; } //伪删除的标识 } }
创建BookType类
using System.ComponentModel.DataAnnotations; namespace Book.Models { public class BookType:BaseEntity { [StringLength(20)] public string Name { get; set; } } }
创建Book类
using System.ComponentModel.DataAnnotations; namespace Book.Models { public class Book:BaseEntity { [StringLength(50),Required] public string Name { get; set; } public decimal Price { get; set; } } }
这两个类都会继承BaseEntity
在App.Config里面写上你自己的数据库连接字符串

这样的目的就是去生成数据库,只做生成数据库的操作。这里只是在Models层写了一次,在后期加上表示层还有在写一遍!
接下来就是去通过指令迁移到数据库,操作有三步:
- 启动迁移:enable-migrations
- 添加迁移:add-migration '参数'
- 更新数据库:update-database(如果你需要添加或者修改某个字段属性,只需要进行第二步和第三步的操作即可!)
记住默认项目要选择你的Models,如果是多个项目(我这里是只有一个)就必须要把Models设为启动项目,不然迁移指令可能不会起到作用

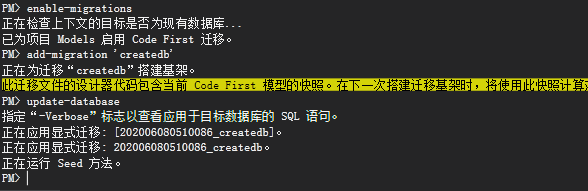
这样就表示你的数据库迁移的工作已经完成了,你可以在数据库进行查看
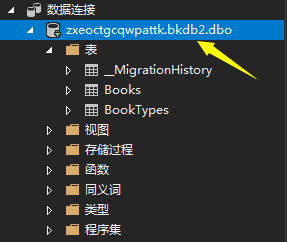
接下来的工作就是准备分层的工作,什么是分层?怎么分?好处是什么?
我的理解:听某一个大佬说,代码是一层一层写的不是一行一行写的。个人觉得拿捏了。原谅我没去百度。。。
一直觉得对于面向对象的思想,一直觉得自己才疏学浅,学的只是皮毛,真是非常的惭愧。
刚好借这个机会来通过分层一起来学习学习。三层,在之前的学习中对于三层也只是找到表示层(UI)、业务逻辑层(BLL)、数据访问层(DAL)。
个人觉得,这样确实是解耦了,但是,并没有将业务逻辑层的“业务逻辑”这一词的功能发挥到极致,就只是简单的从UI层get一下BLL层,BLL层简单的get一下DAL层。。。(个人觉得并没有解什么耦。。。来自菜鸟的思考)
那我们可不可以封一个接口层,通过面向对象的继承来去调整一下呢?
首先得明确接口是可以继承接口的!
创建一个数据接口层IDAL,结构如下:引用Models层
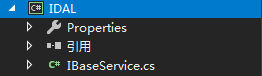
为什么写这个接口呢?原因很简单,就是将增删改查等操作进行一个封装,并且这不是普通的增删改查,看代码:
你可以把它看做是增删改查的基础接口,这个接口是一个泛型(比如你的商品表,用户表等等...),它必须得基础BaseEntity,并且这个T必须继承与BaseEntity,也就是必须是BaseEntity的派生类。
关于IQueryable的好处注释以写!
这四个方法就是增删改查,就算你有几百张表,应该也只要写一次增删改查的操作就ok(也是来自菜鸟理解)
using System; using System.Linq; using Book.Models; namespace IDAL { //接口封装增删改查的方法它,是个泛型,并且要给一个约束,这个T必须是BaseEntity的派生类也就是子类,别的不行 public interface IBaseService<T> where T:BaseEntity { void Add(T t); void Edit(T t); void Remove(Guid id); T GetOne(Guid id); //查询某一个对象 //IQueryable得到的是一个集合,它不会立刻给你去生成Sql语句,直到你需要拿到指定的某个结果后,再去给你生成Sql语句,比如根据条件,分页,排序等操作获得的集合数据 IQueryable<T> GetAll(); } }
既然有了接口,那么肯定是要实现这个接口才能调用里面的增删改查的四个方法吧!既然如此,那么就再写一个DAL类库,去实现这个接口层。
结构如下:引用EF以及Models和IDAL层,并且写一个BaseService类去实现IBaseService接口里面的方法
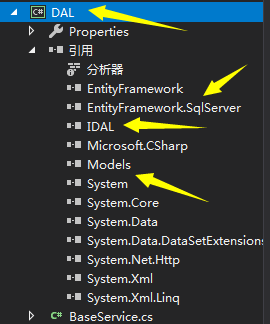
BaseService代码如下:
using IDAL; using System; using System.Linq; using Book.Models; namespace DAL { public class BaseService<T> : IBaseService<T> where T:BaseEntity //指明这个T是谁,就是继承BaseEntity的类 { public void Add(T t) { throw new NotImplementedException(); } public void Edit(T t) { throw new NotImplementedException(); } public IQueryable<T> GetAll() { throw new NotImplementedException(); } public T GetOne(Guid id) { throw new NotImplementedException(); } public void Remove(Guid id) { throw new NotImplementedException(); } } }
前面的 IBaseService<T>就是你实现的是哪个接口,后面的Where就是告诉这个接口要实现的T(泛型已经指定了是继承BaseEntity的派生类)是谁。。。
可能这里的Where作用还需要去理解一下,个人理解就是约束、条件之类的作用。
怎么写方法?代码如下:
using IDAL; using System; using System.Data.Entity; using System.Linq; using Book.Models; namespace DAL { public class BaseService<T> : IBaseService<T> where T:BaseEntity,new() //指明这个T是谁,就是继承BaseEntity的类 { private BookContext _db=new BookContext(); public void Add(T t) { //db.Books.Add(t); _db.Set<T>().Add(t); //Set<>就是返回一个DbSet实例,为什么是T ,作用就是动态的访问,无论是Book还是BookTypes,你给我什么我就用T接就好了 _db.SaveChanges(); } public void Edit(T t) { _db.Entry(t).State = EntityState.Modified; //直接通过主题去作修改 _db.SaveChanges(); } public IQueryable<T> GetAll() { return _db.Set<T>().Where(m => !m.IsRemove).AsNoTracking(); //脱离持久态,变为游离态,并且过滤掉了已被删除的数据 } public T GetOne(Guid id) { return GetAll().First(m => m.Id == id); //直接通过GetAll在通过id查到你想要的数据 } public void Remove(Guid id) { var t=new T() { Id = id }; //这里是伪删除,T不能直接new,也是给个约束条件 new()即可,代表它有构造函数 _db.Entry(t).State = EntityState.Unchanged; //也是根据状态去删除 t.IsRemove = true; _db.SaveChanges(); } } }
这些增删改查方法写完后,就要去继承了。原理实际上和BaseEntity差不多
既然增删改查的方法都写好了,那么怎么去才能调用到它呢?这个时候为什么还需要去写IBook和IBookType呢?。首先我们在之前是写了IBaseService这个接口并且写了对应的增删改查方法,但是具体的实现是在DAL层所有,这两个接口只需要继承对应的IBaseService就好了,具体实现也是在DAL层,至于DAL层怎么去写,请看下面的内容。
这个时候泛型 T就其作用了,我们可以去写对应的接口继承IBaseService就好了。。
代码如下:
IBookService:
namespace IDAL { public interface IBook:IBaseService<Book.Models.Book> { } }
IBookTypeService:
using Book.Models; namespace IDAL { public interface IBookTypeService:IBaseService<BookType> { } }
DAL层结构:
为什么还要继承BaseService?首先BaseService具体实现了继承IBaseService的方法,所以,我们只需要继承一下就可以调用到BaseService的增删改查的方法了!
BookService代码:
using Book.Models; using IDAL; namespace DAL { public class BookService:BaseService<Book.Models.Book>, IBookService { } }
BookTypeService代码:
using Book.Models; using IDAL; namespace DAL { public class BookTypeService:BaseService<BookType>,IBookTypeService { } }
以上操作完成后,我们只需要实例化DAL层的Service方法就可以调用在UI层增删改查了。
写到这里只是最最基础的底层,如果还要完善需要进一步的改善改善。。。
如果有错误的地方请提出来,本人也是学生,大家都是抱着学习的心态去记录和巩固自己的知识点。。。。。