- 本地缓存:不需要序列化,速度快,缓存的数量与大小受限于本机内存
- 分布式缓存:需要序列化,速度相较于本地缓存较慢,但是理论上缓存的数量与大小无限(因为缓存机器可以不断扩展)
2、本地缓存
- Google guava cache:当下最好用的本地缓存
- Ehcache:spring默认集成的一个缓存,以spring cache的底层缓存实现类形式去操作缓存的话,非常方便,但是欠缺灵活,如果想要灵活使用,还是要单独使用Ehcache
- Oscache:最经典简单的页面缓存
3、分布式缓存
- memcached:分布式缓存的标配
- Redis:新一代的分布式缓存,有替代memcached的趋势
3.1、memcached
- 经典的一致性hash算法
- 基于slab的内存模型有效防止内存碎片的产生(但同时也需要估计好启动参数,否则会浪费很多的内存)
- 集群中机器之间互不通信(相较于Jboss cache等集群中机器之间的相互通信的缓存,速度更快<--因为少了同步更新缓存的开销,且更适合于大型分布式系统中使用)
- 使用方便(这一点是相较于Redis在构建客户端的时候而言的,尽管redis的使用也不困难)
- 很专一(专做缓存,这一点也是相较于Redis而言的)
3.2、Redis
- 可以存储复杂的数据结构(5种)
- strings-->即简单的key-value,就是memcached可以存储的唯一的一种形式,接下来的四种是memcached不能直接存储的四种格式(当然理论上可以先将下面的一些数据结构中的东西封装成对象,然后存入memcached,但是不推荐将大对象存入memcached,因为memcached的单一value的最大存储为1M,可能即使采用了压缩算法也不够,即使够,可能存取的效率也不高,而redis的value最大为1G)
- hashs-->看做hashTable
- lists-->看做LinkedList
- sets-->看做hashSet,事实上底层是一个hashTable
- sorted sets-->底层是一个skipList
- 有两种方式可以对缓存数据进行持久化
- RDB
- AOF
- 事件调度
- 发布订阅等
4、集成缓存
专指spring cache,spring cache自己继承了ehcache作为了缓存的实现类,我们也可以使用guava cache、memcached、redis自己来实现spring cache的底层。当然,spring cache可以根据实现类来将缓存存在本地还是存在远程机器上。
5、页面缓存
在使用jsp的时候,我们会将一些复杂的页面使用Oscache进行页面缓存,使用非常简单,就是几个标签的事儿;但是,现在一般的企业,前台都会使用velocity、freemaker这两种模板引擎,本身速度就已经很快了,页面缓存使用的也就很少了。
总结:
- 在实际生产中,我们通常会使用guava cache做本地缓存+redis做分布式缓存+spring cache就集成缓存(底层使用redis来实现)的形式
- guava cache使用在更快的获取缓存数据,同时缓存的数据量并不大的情况
- spring cache集成缓存是为了简单便捷的去使用缓存(以注解的方式即可),使用redis做其实现类是为了可以存更多的数据在机器上
- redis缓存单独使用是为了弥补spring cache集成缓存的不灵活
- 就我个人而言,如果需要使用分布式缓存,那么首先redis是必选的,因为在实际开发中,我们会缓存各种各样的数据类型,在使用了redis的同时,memcached就完全可以舍弃了,但是现在还有很多公司在同时使用memcached和redis两种缓存。
在本系列接下来的介绍中,会介绍在分布式情况下guava cache、memcached、redis、spring cache的使用与原理。
第二章 Google guava cache源码解析1--构建缓存器
1、guava cache
- 当下最常用最简单的本地缓存
- 线程安全的本地缓存
- 类似于ConcurrentHashMap(或者说成就是一个ConcurrentHashMap,只是在其上多添加了一些功能)
2、使用实例
具体在实际中使用的例子,去查看《第七章 企业项目开发--本地缓存guava cache》,下面只列出测试实例:
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.common.cache.CacheBuilder;
import com.google.common.cache.CacheLoader;
import com.google.common.cache.LoadingCache;
public class Hello{
LoadingCache<String, String> testCache = CacheBuilder.newBuilder()
.expireAfterWrite(20, TimeUnit.MINUTES)// 缓存20分钟
.maximumSize(1000)// 最多缓存1000个对象
.build(new CacheLoader<String, String>() {
public String load(String key) throws Exception {
if(key.equals("hi")){
return null;
}
return key+"-world";
}
});
public static void main(String[] args){
Hello hello = new Hello();
System.out.println(hello.testCache.getIfPresent("hello"));//null
hello.testCache.put("123", "nana");//存放缓存
System.out.println(hello.testCache.getIfPresent("123"));//nana
try {
System.out.println(hello.testCache.get("hello"));//hello-world
} catch (ExecutionException e) {
e.printStackTrace();
}
System.out.println(hello.testCache.getIfPresent("hello"));//hello-world
/***********测试null*************/
System.out.println(hello.testCache.getIfPresent("hi"));//null
try {
System.out.println(hello.testCache.get("hi"));//抛异常
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
在这个方法中,基本已经覆盖了guava cache常用的部分。
- 构造缓存器
- 缓存器的构建没有使用构造器而不是使用了构建器模式,这是在存在多个可选参数的时候,最合适的一种配置参数的方式,具体参看《effective Java(第二版)》第二条建议。
- 常用的三个方法
- get(Object key)
- getIfPresent(Object key)
- put(Object key, Object value)
3、源代码
在阅读源代码之前,强烈建议,先看一下"Java并发包类源码解析"中的《第二章 ConcurrentHashMap源码解析》,链接如下:
http://www.cnblogs.com/java-zhao/p/5113317.html
对于源码部分,由于整个代码的核心类LocalCache有5000多行,所以只介绍上边给出的实例部分的相关源码解析。本节只说一下缓存器的构建,即如下代码部分:
LoadingCache<String, String> testCache = CacheBuilder.newBuilder()
.expireAfterWrite(20, TimeUnit.MINUTES)// 缓存20分钟(时间起点:entry的创建或替换(即修改))
//.expireAfterAccess(10, TimeUnit.MINUTES)//缓存10分钟(时间起点:entry的创建或替换(即修改)或最后一次访问)
.maximumSize(1000)// 最多缓存1000个对象
.build(new CacheLoader<String, String>() {
public String load(String key) throws Exception {
if(key.equals("hi")){
return null;
}
return key+"-world";
}
});
说明:该代码的load()方法会在之后将get(Object key)的时候再说,这里先不说了。
对于这一块儿,由于guava cache这一块儿的代码虽然不难,但是容易看的跑偏,一会儿就不知道跑到哪里去了,所以我下边先给出guava cache的数据结构以及上述代码的执行流程,然后大家带着这个数据结构和执行流程去分析下边的源代码,分析完源代码之后,我在最后还会再将cache的数据结构和构建缓存器的执行流程给出,并会结合我们给出的开头实例代码来套一下整个流程,最后画出初始化构建出来的缓存器(其实,这个缓存器就是上边以及文末给出的cache的数据结构图)。
guava cache的数据结构图:

需要说明的是:
- 每一个Segment中的有效队列(废弃队列不算)的个数最多可能不止一个
- 上图与ConcurrentHashMap及其类似,其中的ReferenceEntry[i]用于存放key-value
- 每一个ReferenceEntry[i]都会存放一个链表,当然采用的也是Entry替换的方式。
- 队列用于实现LRU缓存回收算法
- 多个Segment之间互不打扰,可以并发执行
- 各个Segment的扩容只需要扩自己的就好,与其他Segment无关
- 根据需要设置好初始化容量与并发水平参数,可以有效避免扩容带来的昂贵代价,但是设置的太大了,又会耗费很多内存,要衡量好
后边三条与ConcurrentHashMap一样
guava cache的数据结构的构建流程:
1)构建CacheBuilder实例cacheBuilder
2)cacheBuilder实例指定缓存器LocalCache的初始化参数
3)cacheBuilder实例使用build()方法创建LocalCache实例(简单说成这样,实际上复杂一些)
3.1)首先为各个类变量赋值(通过第二步中cacheBuilder指定的初始化参数以及原本就定义好的一堆常量)
3.2)之后创建Segment数组
3.3)最后初始化每一个Segment[i]
3.3.1)为Segment属性赋值
3.3.2)初始化Segment中的table,即一个ReferenceEntry数组(每一个key-value就是一个ReferenceEntry)
3.3.3)根据之前类变量的赋值情况,创建相应队列,用于LRU缓存回收算法
类结构:(这个不看也罢)
- CacheBuilder:设置LocalCache的相关参数,并创建LocalCache实例
- CacheLoader:有用的部分就是一个load(),用于实现"取缓存-->若不存在,先计算,在缓存-->取缓存"的原子操作
- LocalCache:整个guava cache的核心类,包含了guava cache的数据结构以及基本的缓存的操作方法
- LocalLoadingCache:LocalCache的一个静态内部类,这里的get(K key)是外部调用get(K key)入口
- LoadingCache接口:继承于Cache接口,定义了get(K key)
- Cache接口:定义了getIfPresent(Object key)和put(K key, V value)
- LocalManualCache:LocalCache的一个静态内部类,是LocalLoadingCache的父类,这里的getIfPresent(Object key)和put(K key, V value)也是外部方法的入口
关于上边的这些说明,结合之后的源码进行看就好了。
注:如果在源码中有一些注释与最后的套例子的注释不同的话,以后者为准
3.1、构建CacheBuilder+为LocalCache设置相关参数+创建LocalCache实例
CacheBuilder的一些属性:
private static final int DEFAULT_INITIAL_CAPACITY = 16;//用于计算每个Segment中的hashtable的大小
private static final int DEFAULT_CONCURRENCY_LEVEL = 4;//用于计算有几个Segment
private static final int DEFAULT_EXPIRATION_NANOS = 0;//默认的缓存过期时间
static final int UNSET_INT = -1;
int initialCapacity = UNSET_INT;//用于计算每个Segment中的hashtable的大小
int concurrencyLevel = UNSET_INT;//用于计算有几个Segment
long maximumSize = UNSET_INT;//cache中最多能存放的缓存entry个数
long maximumWeight = UNSET_INT;
Strength keyStrength;//键的引用类型(strong、weak、soft)
Strength valueStrength;//值的引用类型(strong、weak、soft)
long expireAfterWriteNanos = UNSET_INT;//缓存超时时间(起点:缓存被创建或被修改)
long expireAfterAccessNanos = UNSET_INT;//缓存超时时间(起点:缓存被创建或被修改或被访问)
CacheBuilder-->newCacheBuilder():创建一个CacheBuilder实例
/**
* 采用默认的设置(如下)创造一个新的CacheBuilder实例
* 1、strong keys
* 2、strong values
* 3、no automatic eviction of any kind.
*/
public static CacheBuilder<Object, Object> newBuilder() {
return new CacheBuilder<Object, Object>();//new 一个实例
}
接下来,使用构建器模式指定一些属性值(这里的话,就是超时时间:expireAfterWriteNanos+cache中最多能放置的entry个数:maximumSize),这里的entry指的就是一个缓存(key-value对)
CacheBuilder-->expireAfterWrite(long duration, TimeUnit unit)
/**
* 指明每一个entry(key-value)在缓存中的过期时间
* 1、时间的参考起点:entry的创建或值的修改
* 2、过期的entry也许会被计入缓存个数size(也就是说缓存个数不仅仅只有存活的entry)
* 3、但是过期的entry永远不会被读写
*/
public CacheBuilder<K, V> expireAfterWrite(long duration, TimeUnit unit) {
/*
* 检查之前是否已经设置过缓存超时时间
*/
checkState(expireAfterWriteNanos == UNSET_INT,//正确条件:之前没有设置过缓存超时时间
"expireAfterWrite was already set to %s ns",//不符合正确条件的错误信息
expireAfterWriteNanos);
/*
* 检查设置的超时时间是否大于等于0,当然,通常情况下,我们不会设置缓存为0
*/
checkArgument(duration >= 0, //正确条件
"duration cannot be negative: %s %s",//不符合正确条件的错误信息,下边的是错误信息中的错误参数
duration,
unit);
this.expireAfterWriteNanos = unit.toNanos(duration);//根据输入的时间值与时间单位,将时间值转换为纳秒
return this;
}
注意:
- 设置超时时间,注意时间的起点是entry的创建或替换(修改)
- expireAfterAccess(long duration, TimeUnit unit)方法的时间起点:entry的创建或替换(修改)或被访问
CacheBuilder-->maximumSize(long size)
/**
* 指定cache中最多能存放的entry(key-value)个数maximumSize
* 注意:
* 1、在entry个数还未达到这个指定个数maximumSize的时候,可能就会发生缓存回收
* 上边这种情况发生在cache size接近指定个数maximumSize,
* cache就会回收那些很少会再被用到的缓存(这些缓存会使最近没有被用到或很少用到的),其实说白了就是LRU算法回收缓存
* 2、maximumSize与maximumWeight不能一起使用,其实后者也很少会使用
*/
public CacheBuilder<K, V> maximumSize(long size) {
/* 检查maximumSize是否已经被设置过了 */
checkState(this.maximumSize == UNSET_INT,
"maximum size was already set to %s",
this.maximumSize);
/* 检查maximumWeight是否已经被设置过了(这就是上边说的第二条)*/
checkState(this.maximumWeight == UNSET_INT,
"maximum weight was already set to %s",
this.maximumWeight);
/* 这是与maximumWeight配合的一个属性 */
checkState(this.weigher == null,
"maximum size can not be combined with weigher");
/* 检查设置的maximumSize是不是>=0,通常不会设置为0,否则不会起到缓存作用 */
checkArgument(size >= 0, "maximum size must not be negative");
this.maximumSize = size;
return this;
}
注意:
- 设置整个cache(而非每个Segment)中最多可存放的entry的个数
CacheBuilder-->build(CacheLoader<? super K1, V1> loader)
/**
* 建立一个cache,该缓存器通过使用传入的CacheLoader,
* 既可以获取已给定key的value,也能够自动的计算和获取缓存(这说的就是get(Object key)的三步原子操作)
* 当然,这里是线程安全的,线程安全的运行方式与ConcurrentHashMap一致
*/
public <K1 extends K, V1 extends V> LoadingCache<K1, V1> build(CacheLoader<? super K1, V1> loader) {
checkWeightWithWeigher();
return new LocalCache.LocalLoadingCache<K1, V1>(this, loader);
}
注意:
- 要看懂该方法,需要了解一些泛型方法的使用方式与泛型限界
- 该方法的返回值是一个LoadingCache接口的实现类LocalLoadingCache实例
- 在build方法需要传入一个CacheLoader的实例,实际使用中使用了匿名内部类来实现的,源码的话,就是一个无参构造器,什么也没做,传入CacheLoader实例的意义就是"类结构"部分所说的load()方法
在上边调用build时,整个代码的执行权其实就交给了LocalCache.
3.2、LocalCache
LocalLoadingCahe构造器
static class LocalLoadingCache<K, V> extends LocalManualCache<K, V>
implements LoadingCache<K, V> {
LocalLoadingCache(CacheBuilder<? super K, ? super V> builder,
CacheLoader<? super K, V> loader) {
super(new LocalCache<K, V>(builder, checkNotNull(loader)));
}
说明:在该内部类的无参构造器的调用中,
1)首先要保证传入的CacheLoader实例非空,
2)其次创建了一个LocalCache的实例出来,
3)最后调用父类LocalManualCache的私有构造器将第二步创建出来的LocalCache实例赋给LocalCache的类变量,完成初始化。
这里最重要的就是第二步,下面着重讲第二步:
LocalCache的一些属性
/** 最大容量(2的30次方),即最多可存放2的30次方个entry(key-value) */
static final int MAXIMUM_CAPACITY = 1 << 30;
/** 最多多少个Segment(2的16次方)*/
static final int MAX_SEGMENTS = 1 << 16;
/** 用于选择Segment */
final int segmentMask;
/** 用于选择Segment,尽量将hash打散 */
final int segmentShift;
/** 底层数据结构,就是一个Segment数组,而每一个Segment就是一个hashtable */
final Segment<K, V>[] segments;
/**
* 并发水平,这是一个用于计算Segment个数的一个数,
* Segment个数是一个刚刚大于或等于concurrencyLevel的数
*/
final int concurrencyLevel;
/** 键的引用类型(strong、weak、soft) */
final Strength keyStrength;
/** 值的引用类型(strong、weak、soft) */
final Strength valueStrength;
/** The maximum weight of this map. UNSET_INT if there is no maximum.
* 如果没有设置,就是-1
*/
final long maxWeight;
final long expireAfterAccessNanos;
final long expireAfterWriteNanos;
/** Factory used to create new entries. */
final EntryFactory entryFactory;
/** 默认的缓存加载器,用于做一些缓存加载操作(其实就是load),实现三步原子操作*/
@Nullable
final CacheLoader<? super K, V> defaultLoader;
/** 默认的缓存加载器,用于做一些缓存加载操作(其实就是load),实现三步原子操作*/
@Nullable
final CacheLoader<? super K, V> defaultLoader;
说明:关于这些属性的含义,看注释+CacheBuilder部分的属性注释+ConcurrentHashMap的属性注释
LocalCache-->LocalCache(CacheBuilder, CacheLoader)
/**
* 创建一个新的、空的map(并且指定策略、初始化容量和并发水平)
*/
LocalCache(CacheBuilder<? super K, ? super V> builder,
@Nullable CacheLoader<? super K, V> loader) {
/*
* 默认并发水平是4,即四个Segment(但要注意concurrencyLevel不一定等于Segment个数)
* Segment个数:一个刚刚大于或等于concurrencyLevel且是2的几次方的一个数
*/
concurrencyLevel = Math
.min(builder.getConcurrencyLevel(), MAX_SEGMENTS);
keyStrength = builder.getKeyStrength();//默认为Strong,即强引用
valueStrength = builder.getValueStrength();//默认为Strong,即强引用
// 缓存超时(时间起点:entry的创建或替换(即修改))
expireAfterWriteNanos = builder.getExpireAfterWriteNanos();
// 缓存超时(时间起点:entry的创建或替换(即修改)或最后一次访问)
expireAfterAccessNanos = builder.getExpireAfterAccessNanos();
//创建entry的工厂
entryFactory = EntryFactory.getFactory(keyStrength,
usesAccessEntries(),
usesWriteEntries());
//默认的缓存加载器
defaultLoader = loader;
// 初始化容量为16,整个cache可以放16个缓存entry
int initialCapacity = Math.min(builder.getInitialCapacity(),
MAXIMUM_CAPACITY);
int segmentShift = 0;
int segmentCount = 1;
//循环条件的&&后边的内容是关于weight的,由于没有设置maxWeight,所以其值为-1-->evictsBySize()返回false
while (segmentCount < concurrencyLevel
&& (!evictsBySize() || segmentCount * 20 <= maxWeight)) {
++segmentShift;
segmentCount <<= 1;//找一个刚刚大于或等于concurrencyLevel的Segment数
}
this.segmentShift = 32 - segmentShift;
segmentMask = segmentCount - 1;
this.segments = newSegmentArray(segmentCount);//创建指定大小的数组
int segmentCapacity = initialCapacity / segmentCount;//计算每一个Segment中的容量的值,刚刚大于等于initialCapacity/segmentCount
if (segmentCapacity * segmentCount < initialCapacity) {
++segmentCapacity;
}
int segmentSize = 1;//每一个Segment的容量
while (segmentSize < segmentCapacity) {
segmentSize <<= 1;//刚刚>=segmentCapacity&&是2的几次方的数
}
if (evictsBySize()) {//由于没有设置maxWeight,所以其值为-1-->evictsBySize()返回false
// Ensure sum of segment max weights = overall max weights
long maxSegmentWeight = maxWeight / segmentCount + 1;
long remainder = maxWeight % segmentCount;
for (int i = 0; i < this.segments.length; ++i) {
if (i == remainder) {
maxSegmentWeight--;
}
this.segments[i] = createSegment(segmentSize,
maxSegmentWeight,
builder.getStatsCounterSupplier().get());
}
} else {
for (int i = 0; i < this.segments.length; ++i) {
this.segments[i] = createSegment(segmentSize,
UNSET_INT,
builder.getStatsCounterSupplier().get());
}
}
}
说明:这里的代码就是整个LocalCache实例的创建过程,非常重要!!!
下面介绍在LocalCache(CacheBuilder, CacheLoader)中调用的一些方法:
- CacheBuilder-->getConcurrencyLevel()
说明:检查是否设置了concurrencyLevel,如果设置了,采用设置的值,如果没有设置,采用默认值16
int getConcurrencyLevel() { return (concurrencyLevel == UNSET_INT) ? //是否设置了concurrencyLevel DEFAULT_CONCURRENCY_LEVEL//如果没有设置,采用默认值16 : concurrencyLevel;//如果设置了,采用设置的值 }
- CacheBuilder-->getKeyStrength()
//获取键key的强度(默认为Strong,还有weak和soft) Strength getKeyStrength() { return MoreObjects.firstNonNull(keyStrength, Strength.STRONG); }说明:获取key的引用类型(强度),默认为Strong(强引用类型),下表列出MoreObjects的方法firstNonNull(@Nullable T first, @Nullable T second)
public static <T> T firstNonNull(@Nullable T first, @Nullable T second) { return first != null ? first : checkNotNull(second); }
- CacheBuilder-->getValueStrength()
Strength getValueStrength() { return MoreObjects.firstNonNull(valueStrength, Strength.STRONG); }说明:获取value的引用类型(强度),默认为Strong(强引用类型)
- CacheBuilder-->getExpireAfterWriteNanos()
long getExpireAfterWriteNanos() { return (expireAfterWriteNanos == UNSET_INT) ? DEFAULT_EXPIRATION_NANOS : expireAfterWriteNanos; }说明:获取超时时间,如果设置了,就是设置值,如果没设置,默认是0
- CacheBuilder-->getInitialCapacity()
int getInitialCapacity() { return (initialCapacity == UNSET_INT) ? DEFAULT_INITIAL_CAPACITY : initialCapacity; }说明:获取初始化容量,如果指定了就是用指定容量,如果没指定,默认为16。值得注意的是,该容量是用于计算每个Segment的容量的,并不一定是每个Segment的容量,其具体使用的方法见LocalCache(CacheBuilder, CacheLoader)
- LocalCache-->evictsBySize()
//这里maxWeight没有设置值,默认为UNSET_INT,即-1 boolean evictsBySize() { return maxWeight >= 0; }说明:这是一个与weight相关的方法,由于我们没有设置weight,所以该方法对我们的程序没有影响。
- EntryFactory-->getFatory()
/** * Masks used to compute indices in the following table. */ static final int ACCESS_MASK = 1; static final int WRITE_MASK = 2; static final int WEAK_MASK = 4; /** * Look-up table for factories. */ static final EntryFactory[] factories = { STRONG, STRONG_ACCESS, STRONG_WRITE, STRONG_ACCESS_WRITE, WEAK, WEAK_ACCESS, WEAK_WRITE, WEAK_ACCESS_WRITE, }; static EntryFactory getFactory(Strength keyStrength, boolean usesAccessQueue, boolean usesWriteQueue) { int flags = ((keyStrength == Strength.WEAK) ? WEAK_MASK : 0)//0 | (usesAccessQueue ? ACCESS_MASK : 0)//0 | (usesWriteQueue ? WRITE_MASK : 0);//WRITE_MASK-->2 return factories[flags];//STRONG_WRITE }说明:EntryFactory是LocalCache的一个内部枚举类,通过上述方法,获取除了相应的EntryFactory,这里选出的是STRONG_WRITE工厂,该工厂代码如下:
STRONG_WRITE { /** * 创建新的Entry */ @Override <K, V> ReferenceEntry<K, V> newEntry(Segment<K, V> segment, K key, int hash, @Nullable ReferenceEntry<K, V> next) { return new StrongWriteEntry<K, V>(key, hash, next); } /** * 将原来的Entry(original)拷贝到当下的Entry(newNext) */ @Override <K, V> ReferenceEntry<K, V> copyEntry(Segment<K, V> segment, ReferenceEntry<K, V> original, ReferenceEntry<K, V> newNext) { ReferenceEntry<K, V> newEntry = super.copyEntry(segment, original, newNext); copyWriteEntry(original, newEntry); return newEntry; } }在该工厂中,指定了创建新entry的方法与复制原有entry为另一个entry的方法。
- LocalCache-->newSegmentArray(int ssize)
/** * 创建一个指定大小的Segment数组 */ @SuppressWarnings("unchecked") final Segment<K, V>[] newSegmentArray(int ssize) { return new Segment[ssize]; }说明:该方法用于创建一个指定大小的Segment数组。关于Segment的介绍后边会说。
-
LocalCache-->createSegment(initialCapacity,maxSegmentWeight,StatsCounter)
Segment<K, V> createSegment(int initialCapacity, long maxSegmentWeight, StatsCounter statsCounter) { return new Segment<K, V>(this, initialCapacity, maxSegmentWeight, statsCounter); }该方法用于为之前创建的Segment数组的每一个元素赋值。
下边列出Segment类的一些属性和方法:
final LocalCache<K, V> map;// 外部类的一个实例 /** 该Segment中已经存在缓存的个数 */ volatile int count; /** * 指定是下边的AtomicReferenceArray<ReferenceEntry<K, V>> table,即扩容也是只扩自己的Segment * The table is expanded when its size exceeds this threshold. (The * value of this field is always {@code (int) (capacity * 0.75)}.) */ int threshold; /** * 每个Segment中的table */ volatile AtomicReferenceArray<ReferenceEntry<K, V>> table; /** * The maximum weight of this segment. UNSET_INT if there is no maximum. */ final long maxSegmentWeight; /** * map中当前元素的一个队列,队列元素根据write time进行排序,每write一个元素就将该元素加在队列尾部 */ @GuardedBy("this") final Queue<ReferenceEntry<K, V>> writeQueue; /** * A queue of elements currently in the map, ordered by access time. * Elements are added to the tail of the queue on access (note that * writes count as accesses). */ @GuardedBy("this") final Queue<ReferenceEntry<K, V>> accessQueue; Segment(LocalCache<K, V> map, int initialCapacity, long maxSegmentWeight, StatsCounter statsCounter) { this.map = map; this.maxSegmentWeight = maxSegmentWeight;//0 this.statsCounter = checkNotNull(statsCounter); initTable(newEntryArray(initialCapacity)); writeQueue = map.usesWriteQueue() ? //过期时间>0 new WriteQueue<K, V>() //WriteQueue : LocalCache.<ReferenceEntry<K, V>> discardingQueue(); accessQueue = map.usesAccessQueue() ? //false new AccessQueue<K, V>() : LocalCache.<ReferenceEntry<K, V>> discardingQueue(); } AtomicReferenceArray<ReferenceEntry<K, V>> newEntryArray(int size) { return new AtomicReferenceArray<ReferenceEntry<K, V>>(size);//new Object[size]; } void initTable(AtomicReferenceArray<ReferenceEntry<K, V>> newTable) { this.threshold = newTable.length() * 3 / 4; // 0.75 if (!map.customWeigher() && this.threshold == maxSegmentWeight) { // prevent spurious expansion before eviction this.threshold++; } this.table = newTable; }Segment的构造器完成了三件事儿:为变量复制 + 初始化Segment的table + 构建相关队列
- initTable(newEntryArray(initialCapacity))源代码在Segment类中已给出:初始化table的步骤简述为:创建一个指定个数的ReferenceEntry数组,计算扩容值。
- 其他队列不说了,这里实际上只用到了WriteQueue,建立该Queue的目的是用于实现LRU缓存回收算法
到目前为止,guava cache的完整的一个数据结构基本上就建立起来了。最后再总结一下。
guava cache的数据结构:
guava cache的数据结构的构建流程:
1)构建CacheBuilder实例cacheBuilder
2)cacheBuilder实例指定缓存器LocalCache的初始化参数
3)cacheBuilder实例使用build()方法创建LocalCache实例(简单说成这样,实际上复杂一些)
3.1)首先为各个类变量赋值(通过第二步中cacheBuilder指定的初始化参数以及原本就定义好的一堆常量)
3.2)之后创建Segment数组
3.3)最后初始化每一个Segment[i]
3.3.1)为Segment属性赋值
3.3.2)初始化Segment中的table,即一个ReferenceEntry数组(每一个key-value就是一个ReferenceEntry)
3.3.3)根据之前类变量的赋值情况,创建相应队列,用于LRU缓存回收算法
这里,我们就用开头给出的代码实例,来看一下,最后构建出来的cache结构是个啥:
显示指定:
expireAfterWriteNanos==20min maximumSize==1000
默认值:
concurrency_level==4(用于计算Segment个数) initial_capcity==16 (用于计算每个Segment容量)
keyStrength==STRONG valueStrength==STRONG
计算出:
entryFactory==STRONG_WRITE
segmentCount==4:Segment个数,一个刚刚大于等于concurrency_level且是2的几次方的一个数
segmentCapacity==initial_capcity/segmentCount==4:用来计算每个Segment能放置的entry个数的一个值,一个刚刚等于initial_capcity/segmentCount或者比initial_capcity/segmentCount大1的数(关键看是否除尽)
segmentSize==4:每个Segment能放置的entry个数,刚刚>=segmentCapacity&&是2的几次方的数
segments==Segment[segmentCount]==Segment[4]
segments[i]:
- 包含一个ReferenceEntry[segmentSize]==ReferenceEntry[4]
- WriteQueue:用于LRU算法的队列
- threshold==newTable.length()*3/4==segmentSize*3/4==3:每个Segment中有了3个Entry(key-value),就会扩容,扩容机制以后在添加Entry的时候再讲
第六章 memcached剖析
注:本篇博客参考于两本书。
- 《memcached全面剖析》,该书籍市面上应该没有,我传到了百度云盘,链接如下:http://pan.baidu.com/s/1qX00Lti
- 《大型网站技术架构:核心原理与案例分析》
前提:
- 本文是基于memcached1.4版本的,之前的版本与该版本在一些地方是不一样的(eg.《memcached全面剖析》的memcached1.2的内存管理方式就与1.4不同)
- 在看本文之前,最好先看一下memcached在实际开发中怎么进行操作的,链接《第八章 企业项目开发--分布式缓存memcached》
1、memcached特征
- 协议简单(文本协议、二进制协议)
- 基于libevent的事件处理,libevent封装了Linux的epoll模型的时间处理功能。
- slab存储模型
- 集群中服务器间互不通信(在大集群的情况下,其性能远超其他同步更新缓存的缓存器,当然小集群下,memcached的性能也十分优秀)
2、memcached访问模型

说明:
Xmemcached的具体使用代码查看"Java企业项目开发实践"系列博客的《第八章 企业项目开发--分布式缓存memcached》,下面的解释会依据该代码进行。
在上图中,memcached客户端假设使用XMemcached
- 服务器列表:在根pom.xml文件中进行了配置
- 路由算法有两种:(可以在程序中指定)
- 一致性hash算法(推荐)
- 简单求余法
- 通信模块:
- 通信协议:TCP协议
- 序列化协议:二进制协议(推荐)、文本协议
- Memcached API(缓存的增删改查):在程序中编写
整个流程:
应用程序(AdminService)调用Memcached API(假设为add操作),向memcached服务器添加缓存,这时候,程序会首先根据配置的路由算法(假设是一致性hash算法)在服务器列表中选出一台服务器(假设是node1),之后该API通过序列化协议序列化对象(当然,这个是可无的,eg.value是一个String),并通过TCP协议将将要存储的key-value对存入相应的服务器。在get时,只要采用的是与add时相同的hash算法,就会选中add时的那一台服务器。
看完这一段,流程明白了。但是有几点疑问:
- 两种路由算法是怎样实现的?为什么使用一致性hash算法
- 缓存到达服务器的时候究竟怎么存储?(slab内存模型)
- 当缓存超过一定的容量后,缓存的自动删除是采用什么策略,怎样删除的?(LRU)
- 两种序列化协议有什么优缺点?
3、hash算法
3.1、简单求余法
原理步骤:求得key的整数hash值(对于Java对象而言,直接使用其hashCode()方法就好),再除以服务器台数,获取余数,根据该余数选择服务器。
注意:如果选择的服务器无法连接时,会进行rehash,即:将连接次数添加到键中,重新计算hash值后,再重新连接。当然可以禁止rehash。
优点:
- 简单
- hash分散性好(因为hashCode()的值具有随机性)
缺点:
- 添加或删除服务器的时候,缓存的获取就会出问题了(因为服务器台数变了,求余的时候分母变了,余数也就可能变了),假设在99台memcached服务器中又新添加而一台,则缓存的不命中率是99%,即n/(n+1),n表示原有的服务器。
注意:
- 在XMemcached中仍保留了该算法
- 适用于不需要考虑集群伸缩性的时候(即机器总数不变)
3.2、一致性hash算法
对于绝大部分系统,集群的伸缩性是五个非功能需求中比较重要的一个,也就是说必须克服"简单求余法"的缺点。
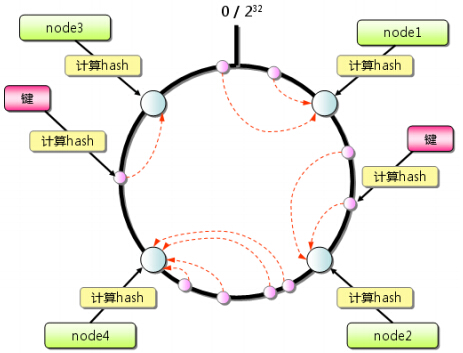
- 原理:先构造一个长度为0~232的整数环(使用二叉树构造),根据节点(memcached服务器)名称的hash值将缓存服务器节点放置在这个hash环上,然后根据需要缓存的数据的key来计算其hash值,然后在hash环上顺时针查找距离这个key的hash值最近的缓存服务器节点,完成key到服务器的hash映射查找。
- 如果超过232还找不到,则存在第一台memcached上(依旧是顺时针)
- 存在的问题:当服务器数量比较少的情况下,有可能造成负载不均衡的情况,为了防止这种情况的发生,使用将物理服务器先虚拟化成多台虚拟服务器,然后将这些虚拟服务器的hash值放在环上,当客户端路由到某台虚拟服务器上时,找到该虚拟服务器所对应的物理服务器即可。
- 一般而言,一台物理服务器虚拟化为150台虚拟服务器最合适,太少会造成负载不均,太多会影响性能
- Memcached采用这样的算法,在我们新加入服务器或集群中的某台服务器宕机时,都不会有太大的影响,只会影响一小段(见下图),确保了集群的可用性与伸缩性

注意:
- hash环是一个二叉树,最后边叶子与最左边相连成环
- 整个缓存的查找过程就是找一个刚刚大于等于查找数的最小值
疑问:(这一点没查到资料)
- 服务器的hash算法是怎样的
- 计算缓存key的hash算法是否要与服务器的一致,还能不能使用原来的hashCode()
思路:hash算法实际上就是"先将字符串转化为整数,然后再将该整数放到相应的服务器上或环上",对于key不用讲,我们可以用crc32将字符串的key转化为整数,之后放在0~232的环上的一点,对于服务器我们可以采用将"ip:port"这个字符串使用crc32转化为整数,之后放在环上(当然这里我们需要将一个实例"ip:port"虚拟化成一堆虚拟节点,每台虚拟节点可以使用"ip:port-i"作为节点名称,其中i是>0的整数,将每台虚拟节点的名称采用crc32算法算出整数放到环上)。
4、slab内存模型
4.1、为什么使用slab内存模型?
在最一开始的内存分配与回收是通过malloc和free来处理的,该方式会产生内存碎片,加重内存管理器的负担,严重缓存操作影响效率。
slab模型的出现就是为了:
- 提高缓存操作效率
- 完全的解决内存碎片问题。
注意:
- 第一个目的:已经实现了(因为直接定位合适的chunk会很快)
- 第二个目的:采用slab机制依旧会产生内存碎片,或者说成是内存浪费
4.2、slab模型原理
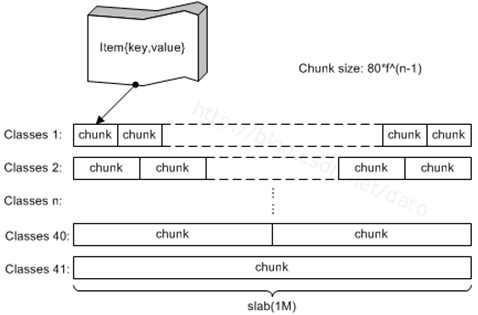
说明:该图摘自一篇博客(图中有标记,但是看不清),但是是很久以前摘的了,忘记了。以后找到了,我会标明出处的。
memcached的内存分配就是下面这一句话:采用分组管理、预分配方式。
4.2.1、分组管理
- 分组方式:Memcached将内存空间分为一组slab,每个slab的大小固定为1M,每个slab里又包含一组chunk,同一个slab里的每个chunk大小相同。根据这些slab中的chunk的大小,将这些slab编号slab class(也就是上图中的Classes i)。
- 存储原理:当来一个要存储的key-value对时,我们查看这个数据的大小,选择最适合的slab class中的空闲chunk放置该对象。
- 最合适的chunk:即该chunk的大小刚刚大于等于所存储数据的大小,而比该chunk小一级的大小刚刚比所要存储的数据小。
以上这种方式会造成内存大量浪费(我认为这也是内存碎片)。
- 减少内存浪费的方式:预估自己的缓存数据的大小,然后在启动Memcached时合理的指定参数-f(增长因子)和-n(chunk最小尺寸)来划分内存大小,根据公式chunk size = 80*f*(n-1)将内存分配为若干个slab class。
疑问:上边这个若干到底是多少?
我们可以根据f,n,以及一个slab最大为1M来确定。(例子,我不举了,自己想想)
4.2.2、预分配
在启动Memcached时通过-m参数为Memcached分配可用内存(假设-m 1024,即分配了1G内存),但是启动的时候不会把这些内存一次全部分配出去,而是默认先分配若干个slab class(数量取决于-f与-n参数),当其中的一个slab class被用完之后,Memcached就会再次申请1M空间,产生一个该slab class。这一块儿结合缓存删除机制中的LRU算法来看。(这一块如果有误,请大神帮忙指出来)
5、缓存删除机制
- memcached不会释放已分配的内存,记录超时后,其存储空间即可重复使用
- memcached内部不会监视缓存是否过期(即memcached不会在过期监视上耗费CPU时间),在get时查看缓存的时间戳,检查缓存是否过期
- memcached会优先使用已超时的缓存的空间,但是当所有空间都没有超时,所有内存都已经分配完了,就删除最近最少使用(LRU)的缓存,将其空间分配给新缓存(注意,假设防止一个100k的数据,而最合适的chunk是112k,假设最合适的chunk全部用完了,这时候就取剩下的内存分配112k chunk的slab,若是剩下的内存页分配完了,不会使用刚刚大于112k的144k chunk,而是会采用LRU算法删除最近最少使用的元素,其实这样的话,就会有一个可能,就是原本112k中的数据还未过期,就有可能被踢出去了,这就是"老数据被踢现象")
注意:第三条与内存分配部分的预分配结合来看。
LRU算法原理:
当某个单元被请求时,维护一个计数器,通过计数器来判断最近最少被使用的元素被踢出去。
6、两种序列化协议
- 文本协议:
- XML、JSON
- key的长度为256字节
- 二进制协议:相较于文本协议
- jdk序列化机制、protobuf
- 不需要文本协议的解析处理,速度更快
- 具有更长的key,理论上最大可使用65536字节长度的key
- 出现在1.4,推荐使用
注意:对于以上两种协议,自己选择吧。
- 二进制协议+JDK的序列化机制,那么由于JDK自己的序列化机制低效,所以在速度上未必会比使用了fastjson的文本协议更快
- 二进制协议+protobuf,速度很快,但是使用起来不太方便
- 文本协议+fastjson
7、部分API
- add:仅当存储空间中不存在相同key的数据时才保存
- replace:替换。即仅当存储空间中存在相同的数据时才保存
- set:add+replace。即无论何时都保存
- delete(key, '阻塞时间(秒)')
- 增1、减1操作,做计数器
- get_multi(key1, key2):一次性非同步的同时(即并发的)获取多个键,比循环调用getKIA数十倍
注意点:
- 对于memcached的监视:可以采用"nagios"
第七章 Xmemcached客户端介绍
提示:有关于XMemcached在实际开发中的具体使用,查看"Java企业项目开发实践"系列博客的《第八章 企业项目开发--分布式缓存memcached》
注意:本文主要参考自https://code.google.com/p/xmemcached/wiki/User_Guide_zh
1、为什么选用Xmemcached客户端
当下常用的三种memcached Java客户端:
- Memcached Client for Java:memcached官方提供,基于Java BIO实现
- SpyMemcached:基于Java NIO
- XMemcached:基于Java NIO,并发性能优于XMemcached,实际上SpyMemcached性能也很高
三者的实验比较结果:
http://xmemcached.googlecode.com/svn/trunk/benchmark/benchmark.html
所以,我们选用XMemcached来实现客户端的编写。
2、XMemcached的主要特性
- 高性能(参照上一部分)
- 支持客户端分布(查看文章开头链接的文章中的代码:根pom.xml+MemcachedUtil类的静态块)
- 允许设置节点权重(XMemcached允许通过设置节点的权重来调节memcached的负载,设置的权重越高,该memcached节点存储的数据将越多,所承受的负载越大)
- 动态增删节点(JMX或zookeeper)
- 客户端连接池
- 默认为1,在开发中直接使用默认值即可
- 若要配置多个连接的连接池,需要保证:数据之间是相互独立的或者全部采用CAS更新来保证原子性。
- 在开发中,发现配置了多个连接后,会发生死锁现象(可能是我的使用方法不对),使用多客户端也是不错的选择,且并发处理的也很好。(具体实现方式查看文章开头链接的文章)
3、使用
具体的实际使用查看文章头部的链接。
3.1、常用类介绍
说明:
- XMemcachedClientBuilder:XMemcachedClient的构建器,通过该构建器可以配置一系列参数,常用的参数有:
- hash算法:setSessionLocator
- 简单求余法(默认):ArrayMemcachedSessionLocator
- 一致性hash:KetamaMemcachedSessionLocator(true)
- 注意:这里我配置了一个true,该参数cwNginxUpstreamConsistent用于兼容nginx-upstream-consistent,如果系统用了nginx,最好配成true
- 序列化协议:setCommandFactory
- 文本协议(默认):TextCommandFactory,实现了memcached的自定义文本协议
- 二进制协议:BinaryCommandFactory,减少了文本解析的步骤,有一些方法仅支持二进制协议
- 序列化转化器:setTranscoder(下面是序列化转换器SerializingTranscoder的一些配置参数)
- 压缩边界值:setCompressionThreshold,默认为16k,实际使用中根据自己的数据大小来指定,我们指定为1M
- 压缩算法:setCompressionMode,默认为GZIP,还有一种是ZIP,使用默认值就会
- 池数量:setConnectionPoolSize,默认为1,实际中采用多客户端的方式可以代替多连接
- failure模式:setFailureMode(true):设置为true后,当一个memcached节点down掉后,发往该节点的请求将发往备份机,若没有备份机,直接抛出异常,而不会像之前那样,把请求打向下一个节点
- standby:主从配置
/* * 下面这样是配置主从 * 其中localhost:11211是主1,localhost:11212是他的从 * host2:11211是主2,host2:11212是他的从 * * 注意:使用主从配置的前提是builder.setFailureMode(true) */ MemcachedClientBuilder builder = new XMemcachedClientBuilder(AddrUtil.getAddressMap("localhost:11211,localhost:11212 host2:11211,host2:11212")); builder.setFailureMode(true);//设置failure模式
- hash算法:setSessionLocator
其中,两种hash算法的实现与比较、两种序列化的实现与比较、池化的注意点查看《第六章 memcached剖析》
- XMemcachedCient:所有缓存的具体操作(add/set/replace/remove/get等)都在这里
- SanitizeKeys:当选用URL当key时,MemcachedClient会自动将URL encode后再存储,该参数默认是关闭的,若要开启,如下:
client.setSanitizeKeys(true);//URL做key
3.2、注意点
- 多服务器之间必须用空格隔开,用逗号不行。原因参看XMemcached转换多服务器字符串的AddrUtil.getAddress(String s)方法源代码:
/** 2 * 该方法用于将传入的"host1:port1 host2:port2 ..." 3 * 这些众多的服务器转换为一个InetSocketAddress集合 4 */ 5 public static List<InetSocketAddress> getAddresses(String s) { 6 if (s == null) { 7 throw new NullPointerException("Null host list"); 8 } 9 if (s.trim().equals("")) { 10 throw new IllegalArgumentException("No hosts in list: ``" + s 11 + "''"); 12 } 13 s = s.trim(); 14 ArrayList<InetSocketAddress> addrs = new ArrayList<InetSocketAddress>(); 15 16 for (String hoststuff : s.split(" ")) {//这里就是多服务器为什么要用空格隔开的理由 17 int finalColon = hoststuff.lastIndexOf(':'); 18 if (finalColon < 1) { 19 throw new IllegalArgumentException("Invalid server ``" 20 + hoststuff + "'' in list: " + s); 21 22 } 23 String hostPart = hoststuff.substring(0, finalColon).trim(); 24 String portNum = hoststuff.substring(finalColon + 1).trim(); 25 26 addrs 27 .add(new InetSocketAddress(hostPart, Integer 28 .parseInt(portNum))); 29 } 30 assert !addrs.isEmpty() : "No addrs found"; 31 return addrs; 32 } - 缓存过期参数设置:在API的使用中,有一个缓存过期参数的设置:缓存单位是s,缓存时间最长为1个月(此时参数设为0),所以一定要注意这个时间的设置
- 等待超时时间:XMemcached是基于Java NIO(yanf4j框架)的,客户端与服务端的通讯本身是异步的,所以MemcachedClient向memcached服务器发送一个请求后,不知道什么时候memcached服务器才能把应答返回,所以在一些需要返回应答的API中我们可以指定超时时间,客户端在这个时间内会一直等待应答,若超出这个时间,就认为操作失败了,抛出TimeoutException,当然若在这些需要返回应答的API中没有指定等待超时时间,则默认的等待超时时间是5秒。
/** * Default operation timeout,if the operation is not returned in 5 * second,throw TimeoutException. */ public static final long DEFAULT_OP_TIMEOUT = 5000L; - 更新缓存过期参数:XMemcached1.3.6之前,若要更新缓存超时时间,需要先缓存缓存,再设置缓存(get-set),两次操作+反序列化/序列化+网络传输,造成开销很大。1.3.6之后,
public boolean touch(final String key, int exp)
速度极快。若希望获取缓存并更新缓存过期时间,该方法应该是只有二进制协议支持。
public <T> T getAndTouch(final String key, int newExp)
- 增加缓存:
- add:key若已存在,添加缓存失败
- replace:key若不存在,更换缓存失败
- set:key不管存在不存在,都成功
- 缓存缓存所有的key:没有好方法。getKeyIterator接口将会在1.6.x以后取消
- 命名空间:1.4.2之后,可以将一组缓存项放到同一个命名空间下,如果有这样的需求,我们直接使用redis去做了
第八章 Redis数据库结构与读写原理
注:本文主要参考自《Redis设计与实现》
1、数据库结构

每一个redis服务器内部的数据结构都是一个redisDb[],该数组的大小可以在redis.conf中配置("database 16",默认为16),而我们所有的缓存操作(set/hset/get等)都是在redisDb[]中的一个redisDb(库)上进行操作,这个redisDb默认是redisDb[0]。
注意:
- 可以通过"select 1"来选择接下来的操作在redisDb[1]上进行操作
- 在实际使用中,我们只在redisDb[0]上操作,因为
- redis没有获取当前是在哪一个redisDb上操作的函数,所以很容易才select多次之后,我们就不知道在哪一个库上了,而且既然是只在redisDb[0]上进行操作,那么"database"就可以设置为1了,
- 该参数设置为1后,不仅可以将原有的其他redisDb所占的内存给了redisDb[0],在的"定期删除"策略中,我们也只扫描一个redisDb就可以了。
"定期删除"见 第九章 Redis过期策略
2、读写原理
在每一个redisDb中都以一个dict(字典)用于存储"key-value"。
例子:
假设在redis中执行了如下四条命令并且没有执行任何的select,即默认选择在redisDb[0]上操作
set msg "hello nana"
rpush mylist "a" "b" "c"
hset book name "lover"
hset book author "nana"
则存储结构如下:

3、读写时所进行的维护工作
在读取一个key(读写操作都需要读取key)后,
- 服务器更新缓存命中次数与不命中次数
- 更新该key的最后一次使用时间
- 检测该key是否过期(详细见 第九章 Redis过期策略)
- 写计数器+1,用于持久化
第九章 Redis过期策略
注:本文主要参考自《Redis设计与实现》
1、设置过期时间
- expire key time(以秒为单位)--这是最常用的方式
- setex(String key, int seconds, String value)--字符串独有的方式
具体的使用方式:查看"java企业项目开发实践"的第九章 企业项目开发--分布式缓存Redis(1)和第十章 企业项目开发--分布式缓存Redis(2)
注意:
- 除了字符串自己独有设置过期时间的方法外,其他方法都需要依靠expire方法来设置时间
- 如果没有设置时间,那缓存就是永不过期
- 如果设置了过期时间,之后又想让缓存永不过期,使用persist key
2、三种过期策略
- 定时删除
- 含义:在设置key的过期时间的同时,为该key创建一个定时器,让定时器在key的过期时间来临时,对key进行删除
- 优点:保证内存被尽快释放
- 缺点:
- 若过期key很多,删除这些key会占用很多的CPU时间,在CPU时间紧张的情况下,CPU不能把所有的时间用来做要紧的事儿,还需要去花时间删除这些key
- 定时器的创建耗时,若为每一个设置过期时间的key创建一个定时器(将会有大量的定时器产生),性能影响严重
- 没人用
- 惰性删除
- 含义:key过期的时候不删除,每次从数据库获取key的时候去检查是否过期,若过期,则删除,返回null。
- 优点:删除操作只发生在从数据库取出key的时候发生,而且只删除当前key,所以对CPU时间的占用是比较少的,而且此时的删除是已经到了非做不可的地步(如果此时还不删除的话,我们就会获取到了已经过期的key了)
- 缺点:若大量的key在超出超时时间后,很久一段时间内,都没有被获取过,那么可能发生内存泄露(无用的垃圾占用了大量的内存)
- 定期删除
- 含义:每隔一段时间执行一次删除过期key操作
- 优点:
- 通过限制删除操作的时长和频率,来减少删除操作对CPU时间的占用--处理"定时删除"的缺点
- 定期删除过期key--处理"惰性删除"的缺点
- 缺点
- 在内存友好方面,不如"定时删除"
- 在CPU时间友好方面,不如"惰性删除"
- 难点
- 合理设置删除操作的执行时长(每次删除执行多长时间)和执行频率(每隔多长时间做一次删除)(这个要根据服务器运行情况来定了)
注意:
- 上边所说的数据库指的是内存数据库,默认情况下每一台redis服务器有16个数据库(关于数据库的设置,看下边代码),默认使用0号数据库,所有的操作都是对0号数据库的操作,关于redis数据库的存储结构,查看 第八章 Redis数据库结构与读写原理
 View Code
View Code - memcached只是用了惰性删除,而redis同时使用了惰性删除与定期删除,这也是二者的一个不同点(可以看做是redis优于memcached的一点)
- 对于惰性删除而言,并不是只有获取key的时候才会检查key是否过期,在某些设置key的方法上也会检查(eg.setnx key2 value2:该方法类似于memcached的add方法,如果设置的key2已经存在,那么该方法返回false,什么都不做;如果设置的key2不存在,那么该方法设置缓存key2-value2。假设调用此方法的时候,发现redis中已经存在了key2,但是该key2已经过期了,如果此时不执行删除操作的话,setnx方法将会直接返回false,也就是说此时并没有重新设置key2-value2成功,所以对于一定要在setnx执行之前,对key2进行过期检查)
3、Redis采用的过期策略
惰性删除+定期删除
- 惰性删除流程
- 在进行get或setnx等操作时,先检查key是否过期,
- 若过期,删除key,然后执行相应操作;
- 若没过期,直接执行相应操作
- 定期删除流程(简单而言,对指定个数个库的每一个库随机删除小于等于指定个数个过期key)
- 遍历每个数据库(就是redis.conf中配置的"database"数量,默认为16)
- 检查当前库中的指定个数个key(默认是每个库检查20个key,注意相当于该循环执行20次,循环体时下边的描述)
- 如果当前库中没有一个key设置了过期时间,直接执行下一个库的遍历
- 随机获取一个设置了过期时间的key,检查该key是否过期,如果过期,删除key
- 判断定期删除操作是否已经达到指定时长,若已经达到,直接退出定期删除。
- 检查当前库中的指定个数个key(默认是每个库检查20个key,注意相当于该循环执行20次,循环体时下边的描述)
- 遍历每个数据库(就是redis.conf中配置的"database"数量,默认为16)
注意:
- 对于定期删除,在程序中有一个全局变量current_db来记录下一个将要遍历的库,假设有16个库,我们这一次定期删除遍历了10个,那此时的current_db就是11,下一次定期删除就从第11个库开始遍历,假设current_db等于15了,那么之后遍历就再从0号库开始(此时current_db==0)
- 由于在实际中并没有操作过定期删除的时长和频率,所以这两个值的设置方式作为疑问?
4、RDB对过期key的处理
过期key对RDB没有任何影响
- 从内存数据库持久化数据到RDB文件
- 持久化key之前,会检查是否过期,过期的key不进入RDB文件
- 从RDB文件恢复数据到内存数据库
- 数据载入数据库之前,会对key先进行过期检查,如果过期,不导入数据库(主库情况)
5、AOF对过期key的处理
过期key对AOF没有任何影响
- 从内存数据库持久化数据到AOF文件:
- 当key过期后,还没有被删除,此时进行执行持久化操作(该key是不会进入aof文件的,因为没有发生修改命令)
- 当key过期后,在发生删除操作时,程序会向aof文件追加一条del命令(在将来的以aof文件恢复数据的时候该过期的键就会被删掉)
- AOF重写
- 重写时,会先判断key是否过期,已过期的key不会重写到aof文件
第十章 Redis持久化--RDB+AOF
注:本文主要参考自《Redis设计与实现》
1、Redis两种持久化方式
- RDB
- 执行机制:快照,直接将databases中的key-value的二进制形式存储在了rdb文件中
- 优点:性能较高(因为是快照,且执行频率比aof低,而且rdb文件中直接存储的是key-values的二进制形式,对于恢复数据也快)
- 缺点:在save配置条件之间若发生宕机,此间的数据会丢失
- AOF
- 执行机制:将对数据的每一条修改命令追加到aof文件
- 优点:数据不容易丢失
- 缺点:性能较低(每一条修改操作都要追加到aof文件,执行频率较RDB要高,而且aof文件中存储的是命令,对于恢复数据来讲需要逐行执行命令,所以恢复慢)
2、RDB
实际中使用的配置(在redis.conf)

#发生以下三种的任何一种都会将数据库的缓存内容写入到rdb文件中去(写入的方式是bgsave) #若将下述的三条命令都注释掉,则禁止使用rdb save 900 1 #900s后至少有一个key发生了变化 save 300 10 #300s后至少有10个key发生了变化 save 60 10000 #60s后至少有10000个key发生了变化 #当后台RDB进程导出快照(一部分的key-value)到rdb文件这个过程出错时(即最后一次的后台保存失败时), #redis主进程是否还接受向数据库写数据 #该种方式会让用户知道在数据持久化到硬盘时出错了(相当于一种监控); #如果安装了很好的redis持久化监控,可设置为"no" stop-writes-on-bgsave-error yes #使用LZF压缩字符串,然后写到rdb文件中去 #如果希望RDB进程节省一点CPU时间,设置为no,但是可能最后的rdb文件会很大 rdbcompression yes #在redis重启后,从rdb文件向内存写数据之前,是否先检测该rdb文件是否损坏(根据rdb文件中的校验和check_sum) rdbchecksum yes #设置rdb文件名 dbfilename dump.rdb #设置rdb文件的存储目录 dir ./
说明:
- 具体每一项配置的详细说明看注释
注意:
- 对于save命令而言,配置了该命令,后台是以bgsave来执行的
- bgsave:Redis主进程进行数据读写操作,RDB子进程进行数据的持久化操作,在进行持久化操作时,不阻塞主进程的读写操作
- 以上三条save命令只要发生任一条,bgsave命令都会发生,这就有两个问题,假设60s内有10000个key发生了改变(写入、删除、更新),那么是否会立即进行持久化呢?在这次持久化之后,假设又过了240s,而在此期间没有任何的key的改变操作,此时是否要发生一次持久化(因为满足300s发生了10个key的改变,这里是改变了10000个key)?
- 不会立即进行持久化:redis默认每隔100ms使用serverCron函数检查一次save配置的条件是否满足,满足则进行bgsave,这样的话,如果在100ms内,我已经满足了bgsave的条件,那么我真正执行bgsave的时候也要等到serverCron执行过来的时候
- 不会再发生持久化:redis有两个参数dirty(记录上一次bgsave之后的key的修改数,上边的在240s内例子就是0)和lastsave(上一次成功执行bgsave命令的时间),配置中的每一个save配置的修改数指的就是dirty,而每一个时间段就是以lastsave为起点计算的。
- 注释掉所有的save命令,RDB将不起作用
- rdbcompression yes:配置成这样是不是每一个字符串在存储到rdb文件中时,都要进行一次压缩操作?
- 不是:设置为yes之后,只有当字符串的长度大于等于21个字节时,才会进行压缩
- rdbchecksum yes:这个校验和存储在哪里?为什么通过比对校验和可以判断文件是否损坏?
- 校验和(check_sum)存储在RDB文件的最后八个字节中(详细的RDB文件结构,查看《Redis这基于实现》"第10章 RDB持久化"),简单的RDB文件结构如下:

- RDB文件开头的前五个字节"REDIS"是判断一个文件是不是RDB文件的标准(类似于class文件中的"魔数")
- 接下来的4个字节:RDB文件版本号(db_version)
- databases(注意是复数):这里存放各个库redisDb中存储的key-value信息(是整个数据持久化和恢复的核心)
- EOF(1个字节):RDB文件正文的结束
- check_sum(8个字节):检验和,该值是根据前边四部分值算出来的,在持久化的时候将该值算出来并写入rdb文件的末尾;在根据rdb文件恢复数据的时候,再根据rdb文件中的前边四部分值计算出一个校验和,然后与当前rdb文件中的check_sum(即后八个字节)的内容进行比对,如果一样,说明没损坏,如果不一样,说明前四部分有数据损坏(即该文件损坏)
- 校验和(check_sum)存储在RDB文件的最后八个字节中(详细的RDB文件结构,查看《Redis这基于实现》"第10章 RDB持久化"),简单的RDB文件结构如下:
- 在Redis服务器启动时,redis会自动检测是否有rdb文件(前提是没有aof的时候),如果有,则根据rdb文件恢复数据,此时在恢复数据完成之前,会阻塞客户端对redis的读写操作
3、AOF
实际中使用的配置(在redis.conf)
# 是否打开aof日志功能(appendonly yes) appendonly no # aof文件的存放路径与文件名称 # appendfilename appendonly.aof #每一个命令,都立即同步到aof文件中去(很安全,但是速度慢,因为每一个命令都会进行一次磁盘操作) # appendfsync always #每秒将数据写一次到aof文件 appendfsync everysec #将写入工作交给操作系统,由操作系统来判断缓冲区大小,统一写到aof文件(速度快,但是同步频率低,容易丢数据) # appendfsync no # 在RDB持久化数据的时候,此时的aof操作是否停止,若为yes则停止 # 在停止的这段时间内,执行的命令会写入内存队列,等RDB持久化完成后,统一将这些命令写入aof文件 # 该参数的配置是考虑到RDB持久化执行的频率低,但是执行的时间长,而AOF执行的频率高,执行的时间短, # 若同时执行两个子进程(RDB子进程、AOF子进程)效率会低(两个子进程都是磁盘读写) # 但是若改为yes可能造成的后果是,由于RDB持久化执行时间长,在这段时间内有很多命令写入了内存队列, # 最后导致队列放不下,这样AOF写入到AOF文件中的命令可能就少了很多 # 在恢复数据的时候,根据aof文件恢复就会丢很多数据 # 所以,选择no就好 no-appendfsync-on-rewrite no # AOF重写:把内存中的数据逆化成命令,然后将这些命令重新写入aof文件 # 重写的目的:假设在我们在内存中对同一个key进行了100次操作,最后该key的value是100, # 那么在aof中就会存在100条命令日志,这样的话,有两个缺点: # 1)AOF文件过大,占据硬盘空间 2)根据AOF文件恢复数据极慢(需要执行100条命令) # 如果我们将内存中的该key逆化成"set key 100",然后写入aof文件, # 那么aof文件的大小会大幅度减少,而且根据aof文件恢复数据很快(只需要执行1条命令) # 注意:下边两个约束都要满足的条件下,才会发生aof重写; # 假设没有第二个,那么在aof的前期,只要稍微添加一些数据,就发生aof重写 # 当aof的增长的百分比是原来的100%(即是原来大小的2倍,例如原来是100m,下一次重写是当aof文件是200m的时候),AOF重写 auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb #AOF重写仅发生在当aof文件大于64m时
说明:
- 具体每一项配置的详细说明看注释
注意:
- 每一个客户端命令在执行时都会直接将命令写入AOF缓冲区
- appendfsync always:每一个命令进入缓冲区后,都会立即再从缓冲区追加到AOF文件中
- appendfsync everysec:每一秒后将缓冲区中的所有命令追加到AOF文件中
- appendfsync no:每一个命令进入缓冲区后,由操作系统来判断什么时候(主要是缓冲区快满的时候)将缓冲区中的所有命令追加到AOF文件中
- aof重写需要满足配置文件中的两个条件
- aof重写采用后台子进程执行
- aof的重写会进行大量的写入操作,如果用单线程来做这个事儿,就会长时间阻塞主进程(redis是单线程),这个时候客户端的读写就会失效
- 采用aof后台重写进程造成的问题:
- 如果在后台进程重写期间,有新的命令对数据库进行了读写,新的aof文件就与数据库的存储内容不同了。(注意:在后台进程重写期间,对数据库的读写操作还会进入aof缓冲区,还是会执行aof文件的命令写入,但需要注意的是,虽然这个期间所有的命令还是写入aof文件了,但是这个aof文件会被重写后的新的aof文件所替换,新的aof文件可没有这些命令,那么如果在下次重写发生之前发生宕机,采用aof恢复数据库的时候,那就丢失了很多命令了)
- 解决方案:设置一个aof重写缓冲区,仅仅用于在后台进程重写期间,将发生的数据库读写命令写入到重写缓冲区中(当然,此时的服务器进程除了将发生的数据库读写命令写入到重写缓冲区中,还会写入到aof缓冲区,来保证正常的aof操作),之后当重写子进程完成重写后,向服务器主进程发送一个信号,此时服务器主进程将aof重写缓冲区中的命令追加到新的aof文件中去,用新的aof文件替换掉旧的aof文件。
- 注意:
- 在后台进程重写期间,将发生的数据库读写命令写入到重写缓冲区中时,为什么还要将这些命令写入到aof缓冲区(因为这些命令会写入旧的aof文件)?
- 如果能百分之百保证在最后的主进程用新的aof文件替换了旧的aof文件(就是在这之前不宕机),那么写入到aof缓冲区没用(因为会被覆盖),但是如果在这之前宕机,那么我们的aof文件还是旧的aof文件,这时候命令写入到aof缓冲区就可以保证该aof文件尽可能多的保存命令,将来用于恢复数据库最多丢失的也就是1s的数据。(appendfsync everysec)
- 在"服务器主进程将aof重写缓冲区中的命令追加到新的aof文件中去"这段操作期间,如果有新的客户端读写命令,都将被阻塞(因为是主进程在做上述操作)。这也是整个aof重写过程中唯一被阻塞的部分。
- 在后台进程重写期间,将发生的数据库读写命令写入到重写缓冲区中时,为什么还要将这些命令写入到aof缓冲区(因为这些命令会写入旧的aof文件)?
总结:
- 如果既配置了RDB,又配置了AOF,则在进行数据持久化的时候,都会进行,但是在根据文件恢复数据的时候,以AOF文件为准,RDB文件作废
- 需要注意:数据的恢复是阻塞操作(此间所到来的任何客户端读写请求都失效)
- bgsave和bgrewriteaof(后台aof重写)这两个命令不可以同时发生
- 如果bgsave在执行,此间到来的bgrewriteaof在bgsave执行之后,再执行
- 如果bgrewriteaof在执行,此间到来的bgsave丢弃
- RDB和AOF可以同时配置,但是最后还原数据库的时候是以aof文件来还原的
第十二章 redis-cluster搭建(redis-3.2.5)
redis集群技术
- redis2.x使用客户端分片技术
- redis3.x使用cluster集群技术
一、环境
- os:centos7
- ip:10.211.55.4
- redis:3.2.5
- gem-redis:3.2.2
二、搭建集群
1、本机下载redis-3.2.5.tar.gz
- redis官网:https://redis.io/download
2、从本机拷贝到10.211.55.4
- scp redis-3.2.5.tar.gz root@10.211.55.4:/opt/
3、进入10.211.55.4,解压安装
- tar -zxf /opt/redis-3.2.5.tar.gz
- cd /opt/redis-3.2.5/
- make && make install
4、创建文件夹
- mkdir /data/cluster -p
- cd /data/cluster/
- mkdir 7000 7001 7002 7003 7004 7005
5、拷贝修改配置文件
- cp /opt/redis-3.2.5/redis.conf /data/cluster/7000/
- vi /data/cluster/7000/redis.conf
- bind 10.211.55.4
- port 7004
- daemonize yes
- cluster-enabled yes
- cluster-config-file nodes.conf
- cluster-node-timeout 15000
- 拷贝该redis.conf到7001~7005,并且修改端口号
6、启动6个redis实例
- cd /data/cluster/7000
- redis-server redis.conf
其他类似。
7、安装ruby依赖
- yum install ruby rubygems -y
8、本机下载安装gem-redis
- 下载:https://rubygems.org/gems/redis/versions/3.2.2
- 将gem-redis拷贝到10.211.55.4
- scp redis-3.2.2.gem root@10.211.55.4:/opt/
- 安装:gem install -l /opt/redis-3.2.2.gem
9、将集群管理程序复制到/usr/local/bin/
- cp /opt/redis-3.2.5/src/redis-trib.rb /usr/local/bin/redis-trib
10、创建集群
- redis-trib create --replicas 1 10.211.55.4:7000 10.211.55.4:7001 10.211.55.4:7002 10.211.55.4:7003 10.211.55.4:7004 10.211.55.4:7005
- --replicas 1:为集群中的每个主节点创建一个从节点
- 集群正常工作至少需要3个主节点:以上是三主三从
11、测试
使用rdm进行连接测试即可。