MySQL数据库
数据库概述
数据存储阶段
【1】 人工管理阶段
缺点 : 数据无法共享,不能单独保持,数据存储量有限
【2】 文件管理阶段 (.txt .doc .xls)
优点 : 数据可以长期保存,可以存储大量的数据,使用简单
缺点 : 数据一致性差,数据查找修改不方便,数据冗余度可能比较大
【3】数据库管理阶段
优点 : 数据组织结构化降低了冗余度,提高了增删改查的效率,容易扩展,方便程序调用,做自动化处理
缺点 :需要使用sql 或者 其他特定的语句,相对比较复杂
数据库应用
融机构、游戏网站、购物网站、论坛网站 ... ...

基础概念
数据 : 能够输入到计算机中并被识别处理的信息集合
数据结构 :研究一个数据集合中数据之间关系的
数据库 : 按照数据结构,存储管理数据的仓库。数据库是在数据库管理系统管理和控制下,在一定介质上的数据集合。
数据库管理系统 :管理数据库的软件,用于建立和维护数据库
数据库系统 : 由数据库和数据库管理系统,开发工具等组成的集合
数据库分类和常见数据库
- 关系型数据库和非关系型数据库
关系型: 采用关系模型(二维表)来组织数据结构的数据库
非关系型: 不采用关系模型组织数据结构的数据库
- 开源数据库和非开源数据库
开源:MySQL、SQLite、MongoDB
非开源:Oracle、DB2、SQL_Server
- 常见的关系型数据库
MySQL、Oracle、SQL_Server、DB2 SQLite
认识关系型数据库和MySQL
- 数据库结构 (图库结构)
数据元素 --> 记录 -->数据表 --> 数据库
- 数据库概念解析
数据表 : 存放数据的表格
字段: 每个列,用来表示该列数据的含义
记录: 每个行,表示一组完整的数据

- MySQL特点
- 是开源数据库,使用C和C++编写
- 能够工作在众多不同的平台上
- 提供了用于C、C++、Python、Java、Perl、PHP、Ruby众多语言的API
- 存储结构优良,运行速度快
- 功能全面丰富
- MySQL安装
Ubuntu安装MySQL服务
安装服务端: sudo apt-get install mysql-server
安装客户端: sudo apt-get install mysql-client
配置文件:/etc/mysql
命令集: /usr/bin
数据库存储目录 :/var/lib/mysql
Windows安装MySQL
下载MySQL安装包(windows) https://dev.mysql.com/downloads/mysql/
mysql-installer***5.7.***.msi
安装教程去安装
5.启动和连接MySQL服务
服务端启动
查看MySQL状态: sudo /etc/init.d/mysql status
启动服务:sudo /etc/init.d/mysql start | stop | restart
客户端连接
命令格式
mysql -h主机地址 -u用户名 -p密码
mysql -hlocalhost -uroot -p123456
本地连接可省略 -h 选项: mysql -uroot -p123456
关闭连接
ctrl-D
exit
SQL语句
什么是SQL
结构化查询语言(Structured Query Language),一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。
SQL语句使用特点
- SQL语言基本上独立于数据库本身
- 各种不同的数据库对SQL语言的支持与标准存在着细微的不同
- 每条命令必须以 ; 结尾
- SQL命令关键字不区分字母大小写
MySQL 数据库操作
数据库操作
1.查看已有库
show databases;
2.创建库(指定字符集)
create database 库名 [character set utf8];
e.g. 创建stu数据库,编码为utf8
create database stu character set utf8;
create database stu charset=utf8;
-- 创建数据库时,设置数据库的编码方式
-- CHARACTER SET:指定数据库采用的字符集,utf8不能写成utf-8-- COLLATE:指定数据库字符集的排序规则,utf8的默认排序规则为utf8_general_ci(通过show character set查看)create database dbtest CHARACTER SET utf8 COLLATE utf8_general_ci;3.查看创建库的语句(字符集)
show create database 库名;
e.g. 查看stu创建方法
show create database stu;
4.查看当前所在库
select database();
5.切换库
use 库名;
e.g. 使用stu数据库
use stu;
6.删除库
drop database 库名;
e.g. 删除test数据库
drop database test;
7.库名的命名规则
- 数字、字母、下划线,但不能使用纯数字
- 库名区分字母大小写
- 不能使用特殊字符和mysql关键字
数据表的管理
-
表结构设计初步
【1】 分析存储内容
【2】 确定字段构成
【3】 设计字段类型 -
数据类型支持
数字类型:
整数类型(精确值) - INTEGER,INT,SMALLINT,TINYINT,MEDIUMINT,BIGINT
定点类型(精确值) - DECIMAL
浮点类型(近似值) - FLOAT,DOUBLE
比特值类型 - BIT

对于精度比较高的东西,比如money,用decimal类型提高精度减少误差。列的声明语法是DECIMAL(M,D)。
M是数字的最大位数(精度)。其范围为1~65,M 的默认值是10。
D是小数点右侧数字的数目(标度)。其范围是0~30,但不得超过M。
比如 DECIMAL(6,2)最多存6位数字,小数点后占2位,取值范围-9999.99到9999.99。
比特值类型指0,1值表达2种情况,如真,假
字符串类型:
CHAR和VARCHAR类型
BINARY和VARBINARY类型
BLOB和TEXT类型
ENUM类型和SET类型

- char 和 varchar
char:定长,效率高,一般用于固定长度的表单提交数据存储,默认1字符
varchar:不定长,效率偏低
- text 和blob
text用来存储非二进制文本
blob用来存储二进制字节串
- enum 和 set
enum用来存储给出的一个值
set用来存储给出的值中一个或多个值
- 表的基本操作
创建表(指定字符集)
create table 表名(
字段名 数据类型,
字段名 数据类型,
...
字段名 数据类型
);
- 如果你想设置数字为无符号则加上 unsigned
- 如果你不想字段为 NULL 可以设置字段的属性为 NOT NULL, 在操作数据库时如果输入该字段的数据为NULL ,就会报错。
- DEFAULT 表示设置一个字段的默认值
- AUTO_INCREMENT定义列为自增的属性,一般用于主键,数值会自动加1。
- PRIMARY KEY关键字用于定义列为主键。主键的值不能重复。
e.g. 创建班级表
create table class_1 (id int primary key auto_increment,name varchar(32) not null,age int not null,sex enum('w','m'),score float default 0.0);
e.g. 创建兴趣班表
create table interest (id int primary key auto_increment,name varchar(32) not null,hobby set('sing','dance','draw'),course char not null,price decimal(6,2),comment text);
查看数据表
show tables;
查看已有表的字符集
show create table 表名;
查看表结构
desc 表名;
删除表
drop table 表名;
数据基本操作
插入(insert)
insert into 表名 values(值1),(值2),...;
insert into 表名(字段1,...) values(值1),...;
e.g.
insert into class_1 values (2,'Baron',10,'m',91),(3,'Jame',9,'m',90);
查询(select)
select * from 表名 [where 条件];
select 字段1,字段名2 from 表名 [where 条件];
e.g.
select * from class_1;
select name,age from class_1;
where子句
where子句在sql语句中扮演了重要角色,主要通过一定的运算条件进行数据的筛选
MySQL 主要有以下几种运算符:
算术运算符
比较运算符
逻辑运算符
位运算符
算数运算符
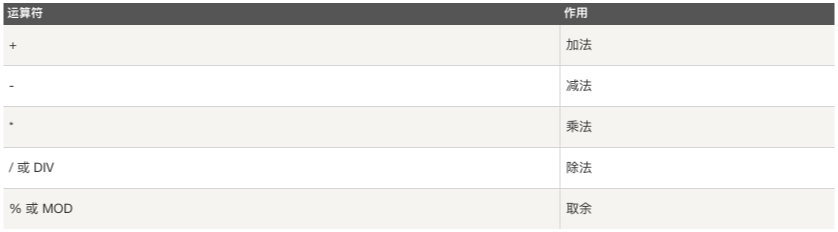
e.g.
select * from class_1 where age % 2 = 0;
比较运算符

e.g.
select * from class_1 where age > 8;
select * from class_1 where between 8 and 10;
select * from class_1 where age in (8,9);
逻辑运算符
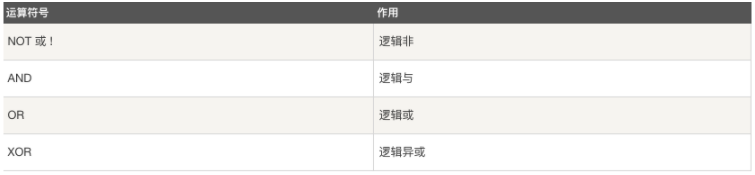
e.g.
select * from class_1 where sex='m' and age>9;
位运算符
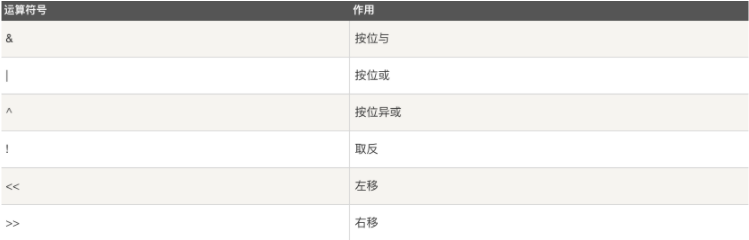

更新表记录(update)
update 表名 set 字段1=值1,字段2=值2,... where 条件;
e.g.
update class_1 set age=11 where name='Abby';
删除表记录(delete)
delete from 表名 where 条件;
注意:delete语句后如果不加where条件,所有记录全部清空
e.g.
delete from class_1 where name='Abby';
表字段的操作(alter)
语法 :alter table 表名 执行动作;
* 添加字段(add)
alter table 表名 add 字段名 数据类型;
alter table 表名 add 字段名 数据类型 first;
alter table 表名 add 字段名 数据类型 after 字段名;
* 删除字段(drop)
alter table 表名 drop 字段名;
* 修改数据类型(modify)
alter table 表名 modify 字段名 新数据类型;
* 修改字段名(change)
alter table 表名 change 旧字段名 新字段名 新数据类型;
* 表重命名(rename)
alter table 表名 rename 新表名;
e.g.
alter table interest add date Date after course;
时间类型数据
时间和日期类型:
DATE,DATETIME和TIMESTAMP类型
TIME类型
年份类型YEAR
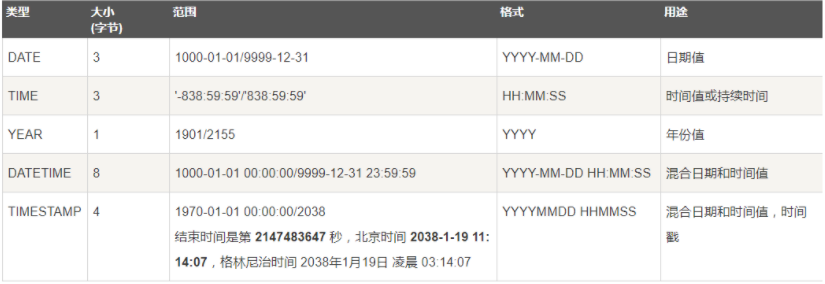
时间格式
date :"YYYY-MM-DD"
time :"HH:MM:SS"
datetime :"YYYY-MM-DD HH:MM:SS"
timestamp :"YYYY-MM-DD HH:MM:SS"
注意
1、datetime :不给值默认返回NULL值
2、timestamp :不给值默认返回系统当前时间
日期时间函数
- now() 返回服务器当前时间
- curdate() 返回当前日期
- curtime() 返回当前时间
- date(date) 返回指定时间的日期
- time(date) 返回指定时间的时间
时间操作
- 查找操作
select * from timelog where Date = "2018-07-02";
select * from timelog where Date>="2018-07-01" and Date<="2018-07-31";
-
日期时间运算
-
语法格式
select * from 表名 where 字段名 运算符 (时间-interval 时间间隔单位);
-
时间间隔单位: 1 day | 2 hour | 1 minute | 2 year | 3 month
-
select * from timelog where shijian > (now()-interval 1 day);
高级查询语句
模糊查询和正则查询
LIKE用于在where子句中进行模糊查询,SQL LIKE 子句中使用百分号 %字符来表示任意字符。
使用 LIKE 子句从数据表中读取数据的通用语法:
SELECT field1, field2,...fieldN
FROM table_name
WHERE field1 LIKE condition1
e.g.
mysql> select * from class_1 where name like 'A%';
mysql中对正则表达式的支持有限,只支持部分正则元字符
SELECT field1, field2,...fieldN
FROM table_name
WHERE field1 REGEXP condition1
e.g.
select * from class_1 where name regexp 'B.+';
排序
ORDER BY 子句来设定你想按哪个字段哪种方式来进行排序,再返回搜索结果。
使用 ORDER BY 子句将查询数据排序后再返回数据:
SELECT field1, field2,...fieldN from table_name1 where field1
ORDER BY field1 [ASC [DESC]]
默认情况ASC表示升序,DESC表示降序
select * from class_1 where sex='m' order by age;
分页
LIMIT 子句用于限制由 SELECT 语句返回的数据数量 或者 UPDATE,DELETE语句的操作数量
带有 LIMIT 子句的 SELECT 语句的基本语法如下:
SELECT column1, column2, columnN
FROM table_name
WHERE field
LIMIT [num]
联合查询
UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中。多个 SELECT 语句会删除重复的数据。
UNION 操作符语法格式:
SELECT expression1, expression2, ... expression_n
FROM tables
[WHERE conditions]
UNION [ALL | DISTINCT]
SELECT expression1, expression2, ... expression_n
FROM tables
[WHERE conditions];
expression1, expression2, ... expression_n: 要检索的列。
tables: 要检索的数据表。
WHERE conditions: 可选, 检索条件。
DISTINCT: 可选,删除结果集中重复的数据。默认情况下 UNION 操作符已经删除了重复数据,所以 DISTINCT 修饰符对结果没啥影响。
ALL: 可选,返回所有结果集,包含重复数据。
要求查询的字段必须相同
select * from class_1 where sex='m' UNION ALL select * from class_1 where age > 9;
多表查询
多个表数据可以联合查询,语法格式如下
select 字段1,字段2... from 表1,表2... [where 条件]
e.g.
select class_1.name,class_1.age,class_1.sex,interest.hobby from class_1,interest where class_1.name = interest.name;
数据备份
- 备份命令格式
mysqldump -u用户名 -p 源库名 > ~/***.sql
--all-databases 备份所有库
库名 备份单个库
-B 库1 库2 库3 备份多个库
库名 表1 表2 表3 备份指定库的多张表
- 恢复命令格式
mysql -uroot -p 目标库名 < ***.sql
从所有库备份中恢复某一个库(--one-database)mysql -uroot -p --one-database 目标库名 < all.sql
回顾
1.数据库
存储数据的仓库
MYSQL,Oracle,
2.MYSQL特点
1.关系型数据库
2.跨平台
3.支持多款编程语言(python,java,php,.... ....)
4.基于磁盘存储,数据是以文件的形式保存在 /var/lib/mysql
3.启动服务
1. sudo /etc/init.d/mysql start|stop|restart|status
2. sudo service mysql start|stop|restart|status
客户端链接: Navicat for MySQL
mysql -hIP地址 -u用户名 -p密码 数据库
本地连接可省略 -h
4.基本的SQL命令
1.库管理
1.创建数据库
1.createdatabase 库名 [charset=utf8]2.createdatabase 库名 default charset utf8 collate utf8_general_ci;
2.查看已有数据库
show databases;
3.查看创建库的语句
show createdatabase4.切换库
use 库名
5.删除库
dropdatabase 库名
2.表管理
1.创建表
createtable 表名(
字段名 数据类型 字段说明,
字段名 数据类型 字段说明,
)
2.查看表结构
desc 表名
3.修改表结构
altertable 表名 .... ....
4.删除表
droptable 表名
3.表记录管理
1.增加 -Create1. 向所有列中插入数据
insertinto 表名 values(值1,值2,...),(值1,值2,...)
2. 向部分列中插入数据
insertinto 表名(字段1,字段2,...)
values
(值1,值2,...)
2.查询 - Retrieve
1.select 字段名 from 表名
2.select 字段名 from 表名 where 条件
1. >,<,>=,<=,=,!=2. in,notin3. not , and , or4. between ... and ...
5. 模糊查询 % , _ ,
3.select 字段名 from 表名
where 条件
orderby 字段名 [desc] , 字段名 [desc]4.select 字段名 from 表名
where 条件
orderby 字段
limit offset,num
e.g. 分页
条件:
1.当前要看第多少页
2.每页显示多少条数据
set@current=5,@pageSize=2select id,name,age,email
from users
limit (@current-1)*@pageSize,@pageSize5.联合查询
select 列1,列2,...
from 表名 where 条件
union[ALL|DISTINCT]select 列1,列2,...
from 表名 where 条件
6.正则匹配
select*from 表名 where 字段 regexp '...'3.更新 -Updateupdate 表名 set 字段=值,字段=值
where 条件
4.删除 -Deletedeletefrom 表名
where 条件
5.数据类型
1.数字
int,bigint,tinyint,float,decimal2.字符串
varchar,text,longtext
3.日期和时间
date,datetime====================================================
练习:
1.创建数据库:country,编码为utf8,排序校对:utf8_general_ci;
createdatabase country default charset utf8 collate utf8_general_ci;
use country;
2.创建表 sanguo(id,name,attack,defense,gender,country)
createtable sanguo(
id intprimarykey auto_increment,
name varchar(32) notnull,
attack int,
defense int,
gender char(2),
country varchar(32)
);
3.插入5条记录
诸葛亮,司马懿,貂蝉,张飞,赵云
攻击(attack >100) , 防御(defense <100)
4.查询所有"蜀国"人的信息
select*from sanguo where country='蜀国';
5.将"赵云"的攻击力设置为360,防御力设置为68
update sanguo set attack=360,defense=68where name='赵云';
6.将"吴国"英雄中攻击值为110的英雄的攻击值改为100,防御改为60
update sanguo set attack=100,defense=60where country='吴国'and attack=1107.找出攻击值高于200的蜀国的英雄的名字和攻击力
select name,attack from sanguo
where attack>200and country='蜀国';
8.将蜀国英雄按照攻击力从高到低排序
select*from sanguo where country='蜀国'orderby attack desc;
9.魏蜀两国英雄中名字为三个字的按防御值升序排序
1.select*from sanguo where (country='魏国'or country='蜀国') and name like'___'orderby defense;
2.select*from sanguo where country in ('魏国','蜀国') and name like'___'orderby defense;
10.在蜀国英雄中,查找攻击值前三名且名字不为null的姓名,攻击值和国家
select name,attack,country from sanguo where country='蜀国'and name isnotnullorderby attack desc limit 3;
====================================================1.MYSQL普通查询
1.聚合函数 (聚合查询)
函数名 功能
avg(字段名) 求指定字段的平均值
max(字段名) 求指定字段的最大值
min(字段名) 求指定字段的最小值
sum(字段名) 求指定字段的记录和
count(字段名) 求指定字段的记录的个数
1.聚合函数使用语法
select 聚合函数1,聚合函数2 from 表名
e.g. 1:找出sanguo表中最大的攻击力值是多少
selectmax(attack) from sanguo
e.g. 2:表中共有多少个英雄
selectcount(*) from sanguo;
e.g. 3:找出sanguo表中最低的防御力值是多少
selectmin(defense) from sanguo;
e.g. 4:蜀国英雄中攻击值大于200的英雄的数量
selectcount(attack) from sanguo where country='蜀国'and attack>200;
2.注意
select name,max(attack) from sanguo;
聚合函数在默认情况下是不能与其他列一起做查询的
3.分组查询 + 聚合查询
e.g. 求sanguo表中每个国家的总攻击力是多少
分组:分组列,值相同的数据会被划分到一组
语法:
select 分组列,聚合函数(列)
from 表
where 条件
groupby 分组列,...
orderby ...
limit ...
e.g. 求sanguo表中每个国家的总攻击力是多少
select country,sum(attack) from sanguo groupby country;
练习:
1.计算每个国家的总攻击力,平均攻击力,总防御力和平均防御力
select country,sum(attack),avg(attack),sum(defense),avg(defense)
from sanguo
groupby country
2.所有国家的男英雄中,英雄数量最多的前2名国家名称以及英雄数量
select country,count(id)
from sanguo
where gender='M'groupby country
orderbycount(id) desc
limit 24.分组筛选 -having
e.g 查询出平均攻击力大于105的国家名称
作用:分组后做组内筛选,配合着group by 联用
语法:
select xxxx
from xxx
where xxxx
groupby xxx
having 条件
orderby xxx
limit xxx
代码:
select country,count(id) as cnt
from sanguo
where gender='M'
group by country
order by cnt desc
limit 2
e.g 查询出平均攻击力大于105的国家名称
select country,avg(attack) as avAtt
from sanguo
groupby country
having avAtt >1052.distinct函数
作用:去重
语法:
selectdistinct(列) from 表
e.g. 查询 sanguo 表中共有多少个国家
3.查询表记录时做数学运算
运算符:+,-,*,/,%
e.g. 1: 查询时显示攻击力翻倍
select attack *2from sanguo;
e.g. 2: 更新蜀国所有的英雄攻击力 *2update sanguo set attack = attack *2where country ='蜀国'
e.g. 3: 查询攻击力+100之后大于200的英雄的姓名和国家
select name,country
from sanguo
where attack +100>2002.索引
1.什么是索引
对数据库表的一列或多列的值进行排序的一种结构
2.优点
加快数据的检索速度
3.缺点
1.占用物理存储空间
2.对表中数据进行更新时,索引也会动态维护,会降低维护速度
4.索引比对手段
1.查询系统时间
2.执行查询
3.查看系统时间
在 某列 上创建索引
1.查询系统时间
2.执行查询
3.查看系统时间
5.索引的分类
1.主键索引
1.特点:增加主键之后,主键列自动会被增加索引
2.增加主键[索引]1.已有表添加主键
altertable 表名 addprimarykey(id);
2.唯一索引
1.特点
1.可以有多个
2.唯一索引所在的列的值必须唯一
2.实施手段
1.创建表的时候指定唯一性
createtable xxx(
id intprimarykey auto_increment,
phone varchar(20) unique,
)
2.对已有表创建索引
createuniqueindex 索引名 on 表名(字段名);
3.普通索引
1.实施手段
1.创建表同时指定普通索引
createtable 表名(
id xxx xxxx,
country varchar(30) ,
index(country),
index(字段名),
)
2.对已有表增加普通索引
createindex 索引名 on 表名(字段名);
6.取消索引
dropindex 索引名称 on 表名
7.查询索引
show indexfrom 表名
CREATETABLE XXX(
ID XXX,
EMAIL varchar(30) unique
)
1.聚合函数 1.聚合函数 avg() : sum() : max() : min() : count() : count(id) : count(*) : e.g : select count(id) from ... e.g : select name,count(id) from ... (错误) 2.分组 + 聚合 关键字: group by e.g : select country,count(id) from sanguo group by country 3.分组筛选 关键词: having e.g : 按国家分组,将国家人数大于2人的国家名称和人数输出 select country,count(id) as counter from sanguo group by country having counter > 2 2.去重 distinct() 3.索引 1.主键索引 2.唯一索引 1.对已有表创建唯一索引 create unique index 索引名 on 表名(字段) 2.创建表时创建唯一索引 create table xxxx( 字段 数据类型, 字段 数据类型, unique(字段), ) 3.普通索引 1.对已有表创建普通索引 create index 索引名 on 表名(字段) 2.创建表时创建唯一索引 create table xxxx( 字段 数据类型, 字段 数据类型, index(字段), ) 4.查看索引 show index from 表名 5.删除索引 drop index 索引名 on 表名 ======================================================= 需求: 1.老师信息:老师姓名,老师年龄,性别,爱好 2.课程信息:课程名称,课时 3.学员信息:学员姓名,学员年龄,性别,毕业院校,班级,专业 4.考试信息:某位学员的某一门课考了多少分 1.表关系 1.外键 - Foreign Key 作用:约束当前表的某列值必须取自于另一张表的主键列值 外键所在的列称之为"外键列" 外键所在的表称之为"外键表"或"子表" 被外键列所引用的表称之为"主表"或"主键表" 2.语法 1.创建表的同时指定外键 create table Course( id int primary key auto_increment, cname varchar(20) ) create table Teacher( id int primary key auto_increment, tname varchar(20), course int , constraint fk_course_teacher foreign key(course_id) /*规则:外键名:fk_course_teacher,第一个外键首写,第二个主键名,第三个外键名*/
references Course(id) ) 语法: createtable xxx( 字段 类型, .... , constraint 外键名 foreignkey(字段) references 主键表(主键列) ) 2.对已有表增加外键 altertable 表名 addconstraint 外键名 foreignkey(字段) references 主键表(主键)
示例代码:
alter table student add constraint fk_major_student foreign key(major_id)references major(id);
3.删除外键 altertable 表名 dropforeignkey 外键名
alter table score drop foreign key fk_student_score
4.查看外键名 show createtable 表名 3.级联操作 1.语法 altertable 表名 addconstraint 外键名 foreignkey(字段) references 主键表(主键) ondelete 级联操作 onupdate 级联操作
代码:为score表中的stu_id增加外键,引用自student主键id,并设置级联操作
altertable score addconstraint fk_student_score foreign key(stu_id) references student(id) on delete cascade on update cascade
2.级联操作取值 1.cascade 数据级联删除、更新 2.restrict(默认) 子表中有关联数据,那么主表中就不允许做删除、更新 3.setnull 主表删除数据时子表中的相关数据会设置为null
注级联操作:主表删除,子表关联的记录全部删除。
4.表连接查询
1.交叉连接 - 笛卡尔积
e.g 查询teacher和course表中所有的数据
select*from teacher,course;
2.内连接
在关联的两张表中,把满足条件的数据筛选出来
语法:
select 字段,... ...
from 表1
innerjoin 表2
on 条件
innerjoin 表3
on 条件:一般子表的外键=主表的主键
示例:查询学员的姓名,年龄,所在班级名称,专业名称,并筛选出1902的学员
select s.name,s.age,c.classname,m.m_name
from student as s
inner join classinfo as c on s.class_id = c.id
inner join major as m on s.major_id = m.id
where c.classname='1902';
练习:
1.查询学员的姓名,年龄,所在班级名称,专业名称
2.查询学员的姓名,毕业院校,所在班级,考试科目,考试成绩
-- 1.查询学员的姓名,年龄,所在班级名称,专业名称,并筛选出1902的学员
/*select s.name,s.age,c.classname,m.m_name
from student as s
inner join classinfo as c on s.class_id = c.id
inner join major as m on s.major_id = m.id
where c.classname='1902';*/
-- 2.查询学员的姓名,毕业院校,所在班级,考试科目,考试成绩
select s.name,s.school,c.classname,cou.cname,sc.score
from student as s
inner join classinfo as c on s.class_id = c.id
inner join score as sc on s.id = sc.stu_id 一般子表的外键=主表的主键
inner join course as cou on sc.course_id = cou.id;


-- 单行注释 /* 多行注释 */ -- 创建course表:id,cname,cduration /*create table course( id int primary key auto_increment, cname varchar(30) not null, cduration int not null );*/ -- 向course表中插入测试数据 /*insert into course(cname,cduration) values ('Python基础',20),('Python高级',15), ('WEB基础',9),('Python Web',15), ('爬虫',10),('数据分析&人工智能',20);*/ -- 创建teacher表:id,name,age,gender,hobby,course_id -- course_id是外键,引用自course表的主键id /*create table teacher( id int primary key auto_increment, name varchar(30) not null, age int not null, gender varchar(2) not null, hobby varchar(50) not null, course_id int , -- 外键约束 constraint fk_course_teacher foreign key(course_id) references course(id) );*/ -- 向teacher表中插入测试数据 /*insert into teacher values (null,'齐天大圣',28,'M','大保健',1), (null,'吕泽Maria',30,'M','拍片',2), (null,'赵萌萌',18,'F','看帅哥',3);*/ -- 创建major表 : id,m_name /*create table major( id int primary key auto_increment, m_name varchar(30) not null );*/ -- 向major表中插入数据 /*insert into major(m_name) values('AID'),('UID'),('JSD'),('WEB');*/ -- 创建student表:id,name,age,gender,school,class_id,major_id /*create table student( id int primary key auto_increment, name varchar(30) not null, age int not null, gender char(2) not null, school varchar(100) not null, class_id int not null, major_id int not null )*/ -- 更新student表,增加外键关系在major_id上,引用自major表的主键id /*alter table student add constraint fk_major_student foreign key(major_id) references major(id);*/ -- 创建classinfo表:id,classname,status /*create table classinfo( id int primary key auto_increment, classname varchar(20) not null, status tinyint );*/ -- 修改student表结构,增加外键在class_id,引用自classinfo表的主键id /*alter table student add constraint fk_classinfo_student foreign key(class_id) references classinfo(id);*/ -- 创建score表:id,stu_id,course_id,score /*create table score( id int primary key auto_increment, stu_id int not null, course_id int not null, score int not null, constraint fk_student_score foreign key(stu_id) references student(id), constraint fk_course_score foreign key(course_id) references course(id) )*/ -- 向classinfo,student,score 表中插入测试数据 /*insert into classinfo values (null,'1901',0), (null,'1902',1), (null,'1903',1), (null,'1904',1), (null,'1905',1); insert into student(name,age,gender,school,class_id,major_id) values ('张三',30,'M','哈佛大学',2,1), ('李四',25,'M','剑桥大学',3,1), ('王二麻子',19,'F','五道口技术学院',2,1), ('王五',28,'M','麻省理工学院',2,1);*/ /*insert into score(stu_id,course_id,score) values (1,1,98),(1,2,85),(1,3,96), (2,1,69),(2,2,89),(2,4,65), (3,2,76),(3,3,88),(3,4,75);*/ -- 删除score表中的fk_student_score外键 -- alter table score drop foreign key fk_student_score -- 为score表中的stu_id增加外键,引用自student主键id,并设置级联操作 /*alter table score add constraint fk_student_score foreign key(stu_id) references student(id) on delete cascade on update cascade*/ -- 使用内连接查询teacher和course表中的数据(姓名,年龄,课程名称,课时) /*select t.name,t.age,c.cname,c.cduration from teacher as t inner join course as c on t.course_id = c.id*/ -- 1.查询学员的姓名,年龄,所在班级名称,专业名称,并筛选出1902的学员 /*select s.name,s.age,c.classname,m.m_name from student as s inner join classinfo as c on s.class_id = c.id inner join major as m on s.major_id = m.id where c.classname='1902';*/ -- 2.查询学员的姓名,毕业院校,所在班级,考试科目,考试成绩 select s.name,s.school,c.classname,cou.cname,sc.score from student as s inner join classinfo as c on s.class_id = c.id inner join score as sc on s.id = sc.stu_id inner join course as cou on sc.course_id = cou.id;
1.外键
1.创建表设置外键
create table xxxx(
xxx xxxx,
constraint 外键名 foreign key(字段)
references 主表(主键)
on delete cascade|restrict|set null
on update cascade|restrict|set null
)
2.修改表增加外键
alter table xxx
add constraint 外键名
foreign key(字段)
references 主表(主键)
on delete cascade|restrict|set null
on update cascade|restrict|set null
3.查看外键
show create table xxxx
4.删除外键
alter table xxxx
drop foreign key 外键名
2.连接查询
1.交叉连接
select * from A,B where A.bid=B.id
2.内连接
连接两张表,将满足条件的数据筛选出来
select * from A
inner join B
on A.bid = B.id
=======================================================
1.连接查询
1.外连接
1.左外连接
1.作用
1.左表中所有的数据都会查询出来(即便不满足条件)
2.将右表中满足关联条件的数据查询出来
3.关联不上的数据关联字段将以null作为填充
2.语法
select 字段
from A left join B
on 关联条件
2.右外连接
1.作用
1.右表中所有的数据都会查询出来
2.将左表中满足关联条件的数据查询出来
3.关联不上的数据关联字段将以null作为填充
2.语法
select 字段
from A right join B
on 关联条件
3.完整外连接
1.作用
将两张表的数据做关联查询,关联得上的则正常显示
关联不上的,则以null值填充
2.语法
select * from
A full join B
on 关联条件
2.子查询
1.什么是子查询
将一个查询的结果作为外侧操作的一个条件出现
2.语法
select .... from 表名 where 条件=(select ... )
select .... from (查询)
练习:
1.查询考过"齐天大圣"老师所教课程的学员的信息
2.查询在score表中有成绩的学员的信息
3.查询"Python基础"课程并且分数在80分以上的
学员的姓名和毕业院校
4.查询和"张三"相同班级以及相同专业的同学的信息
3.E-R模型
1.什么E-R模型
Entity - Relationship 模型 (实体-关系模型)
在数据库设计阶段一定会使用到
以图形的方式展示数据库中的表以及表关系
2.概念
1.实体 - Entity
表示数据库中的一个表
图形表示:矩形框
2.属性
表示某实体中的某一特性,即表的字段
图形表示:椭圆形
讲解链接https://blog.csdn.net/ill__world/article/details/85872034
3.关系 - Relationship
表示实体与实体之间的关联关系
1.一对一关系(1:1)
A表中的一条记录只能关联到B表中的一条记录上
B表中的一条记录只能关联到A表中的一条记录上
在数据库中的实现手段
在任意的一张表中增加:
1.外键,并引用自另一张表主键
2.唯一索引/约束
2.一对多关系(1:M)
A表中的一条记录能够关联到B表中的多条记录
B表中的一条记录只能关联到A表中的一条记录
在数据库中的实现手段
在"多"表中增加:
1.外键,引用"一"表的主键
3.多对多关系(M:N)
A表中的一条记录能够关联到B表中的多条记录
B表中的一条记录能够关联到A表中的多条记录
在数据库中的实现手段
靠第三张关联表,来实现多对多
1.创建第三张表
2.一个主键,俩外键
外键分别引用自关联的两张表的主键
4.SQL语句优化
1.索引:经常select,where,order by 的字段应该建立索引
2.单条查询语句最后添加 LIMIT 1 , 停止全表扫描
3.where子句中尽量不使用 != ,否则放弃索引全表扫描
4.尽量避免null值判断,否则放弃索引全表扫描
5.尽量避免 or 连接条件,否则放弃索引全表扫描
6.模糊查询尽量避免使用前置%,否则全表扫描
7.尽量避免使用in 和 not in,否则全表扫描
8.尽量避免使用 select * ,使用具体字段代替 *,不要返回用不到的任何字段
select * from A inner join B
on A.bid = B.id
Navicat for MySQL
Power Designer - 数据库建模
Microsoft Visio - ER图
-- 1.左外连接:左表:teacher,右表:course,关联条件:teacher.course_id=course.id /*select * from teacher left join course on teacher.course_id = course.id*/ -- 2.左外连接:左表:course,右表:teacher,关联条件:teacher.course_id=course.id /*select * from course left join teacher on teacher.course_id = course.id;*/ -- 3.右外链接,左表:course,右表:teacher,关联条件:teacher.course_id = course.id /*select * from course right join teacher on teacher.course_id = course.id;*/ -- 4.完整外连接(有误) /*select * from course full join teacher on full.id = teacher.course_id*/ -- 5.查看没有参加过考试的同学的信息 /*select * from student left join score on student.id = score.stu_id where score.score is null;*/ -- 6.子查询-查询student表中比'李四'年龄大的学员的信息 /*select * from student where age > (select age from student where name='李四');*/ -- 1.查询考过"齐天大圣"老师所教课程的学员的信息 -- 1.1 查询"齐天大圣"老师所教授的课程的ID -- select course_id from teacher where name='齐天大圣'; -- 1.2 从score表中查询出course_id的值为 "1" 的stu_id的值 /*select stu_id from score where course_id=( select course_id from teacher where name='齐天大圣' );*/ -- 1.3 从student表中查询出id在以上查询结果中出现过的学员的信息 select * from student where id in ( select stu_id from score where course_id=( select course_id from teacher where name='齐天大圣' ) ); -- 2.查询在score表中有成绩的学员的信息 -- 3.查询"Python基础"课程并且分数在80分以上的学员的姓名和毕业院校 -- 4.查询和"张三"相同班级以及相同专业的同学的信息
Python操作MySQL数据库
pymysql安装
sudo pip3 install pymysql
pymysql使用流程
- 建立数据库连接(db = pymysql.connect(...))
- 创建游标对象(c = db.cursor())
- 游标方法: c.execute("insert ....")
- 提交到数据库 : db.commit()
- 关闭游标对象 :c.close()
- 断开数据库连接 :db.close()
常用函数
db = pymysql.connect(参数列表)
host :主机地址,本地 localhost
port :端口号,默认3306
user :用户名
password :密码
database :库
charset :编码方式,推荐使用 utf8
数据库连接对象(db)的方法
db.commit() 提交到数据库执行
db.rollback() 回滚
cur = db.cursor() 返回游标对象,用于执行具体SQL命令
db.close() 关闭连接
游标对象(cur)的方法
cur.execute(sql命令,[列表]) 执行SQL命令
cur.close() 关闭游标对象
cur.fetchone() 获取查询结果集的第一条数据 (1,100001,"河北省")
cur.fetchmany(n) 获取n条 ((记录1),(记录2))
cur.fetchall() 获取所有记录