十一、从头到尾彻底解析Hash 表算法
作者:July、wuliming、pkuoliver
出处:http://blog.csdn.net/v_JULY_v。
说明:本文分为三部分内容,
第一部分为一道百度面试题Top K算法的详解;第二部分为关于Hash表算法的详细阐述;第三部分为打造一个最快的Hash表算法。
------------------------------------
第一部分:Top K 算法详解
问题描述
百度面试题:
搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。
假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
必备知识:
什么是哈希表?
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
哈希表的做法其实很简单,就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。
而当使用哈希表进行查询的时候,就是再次使用哈希函数将key转换为对应的数组下标,并定位到该空间获取value,如此一来,就可以充分利用到数组的定位性能进行数据定位(文章第二、三部分,会针对Hash表详细阐述)。
问题解析:
要统计最热门查询,首先就是要统计每个Query出现的次数,然后根据统计结果,找出Top 10。所以我们可以基于这个思路分两步来设计该算法。
即,此问题的解决分为以下俩个步骤:
第一步:Query统计
Query统计有以下俩个方法,可供选择:
1、直接排序法
首先我们最先想到的的算法就是排序了,首先对这个日志里面的所有Query都进行排序,然后再遍历排好序的Query,统计每个Query出现的次数了。
但是题目中有明确要求,那就是内存不能超过1G,一千万条记录,每条记录是255Byte,很显然要占据2.375G内存,这个条件就不满足要求了。
让我们回忆一下数据结构课程上的内容,当数据量比较大而且内存无法装下的时候,我们可以采用外排序的方法来进行排序,这里我们可以采用归并排序,因为归并排序有一个比较好的时间复杂度O(NlgN)。
排完序之后我们再对已经有序的Query文件进行遍历,统计每个Query出现的次数,再次写入文件中。
综合分析一下,排序的时间复杂度是O(NlgN),而遍历的时间复杂度是O(N),因此该算法的总体时间复杂度就是O(N+NlgN)=O(NlgN)。
2、Hash Table法
在第1个方法中,我们采用了排序的办法来统计每个Query出现的次数,时间复杂度是NlgN,那么能不能有更好的方法来存储,而时间复杂度更低呢?
题目中说明了,虽然有一千万个Query,但是由于重复度比较高,因此事实上只有300万的Query,每个Query255Byte,因此我们可以考虑把他们都放进内存中去,而现在只是需要一个合适的数据结构,在这里,Hash Table绝对是我们优先的选择,因为Hash Table的查询速度非常的快,几乎是O(1)的时间复杂度。
那么,我们的算法就有了:维护一个Key为Query字串,Value为该Query出现次数的HashTable,每次读取一个Query,如果该字串不在Table中,那么加入该字串,并且将Value值设为1;如果该字串在Table中,那么将该字串的计数加一即可。最终我们在O(N)的时间复杂度内完成了对该海量数据的处理。
本方法相比算法1:在时间复杂度上提高了一个数量级,为O(N),但不仅仅是时间复杂度上的优化,该方法只需要IO数据文件一次,而算法1的IO次数较多的,因此该算法2比算法1在工程上有更好的可操作性。
第二步:找出Top 10
算法一:普通排序
我想对于排序算法大家都已经不陌生了,这里不在赘述,我们要注意的是排序算法的时间复杂度是NlgN,在本题目中,三百万条记录,用1G内存是可以存下的。
算法二:部分排序
题目要求是求出Top 10,因此我们没有必要对所有的Query都进行排序,我们只需要维护一个10个大小的数组,初始化放入10个Query,按照每个Query的统计次数由大到小排序,然后遍历这300万条记录,每读一条记录就和数组最后一个Query对比,如果小于这个Query,那么继续遍历,否则,将数组中最后一条数据淘汰,加入当前的Query。最后当所有的数据都遍历完毕之后,那么这个数组中的10个Query便是我们要找的Top10了。
不难分析出,这样,算法的最坏时间复杂度是N*K, 其中K是指top多少。
算法三:堆
在算法二中,我们已经将时间复杂度由NlogN优化到NK,不得不说这是一个比较大的改进了,可是有没有更好的办法呢?
分析一下,在算法二中,每次比较完成之后,需要的操作复杂度都是K,因为要把元素插入到一个线性表之中,而且采用的是顺序比较。这里我们注意一下,该数组是有序的,一次我们每次查找的时候可以采用二分的方法查找,这样操作的复杂度就降到了logK,可是,随之而来的问题就是数据移动,因为移动数据次数增多了。不过,这个算法还是比算法二有了改进。
基于以上的分析,我们想想,有没有一种既能快速查找,又能快速移动元素的数据结构呢?回答是肯定的,那就是堆。
借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此到这里,我们的算法可以改进为这样,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比。
思想与上述算法二一致,只是算法在算法三,我们采用了最小堆这种数据结构代替数组,把查找目标元素的时间复杂度有O(K)降到了O(logK)。
那么这样,采用堆数据结构,算法三,最终的时间复杂度就降到了N‘logK,和算法二相比,又有了比较大的改进。
总结:
至此,算法就完全结束了,经过上述第一步、先用Hash表统计每个Query出现的次数,O(N);然后第二步、采用堆数据结构找出Top 10,N*O(logK)。所以,我们最终的时间复杂度是:O(N) + N'*O(logK)。(N为1000万,N’为300万)。如果各位有什么更好的算法,欢迎留言评论。第一部分,完。
第二部分、Hash表 算法的详细解析
什么是Hash
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
HASH主要用于信息安全领域中加密算法,它把一些不同长度的信息转化成杂乱的128位的编码,这些编码值叫做HASH值. 也可以说,hash就是找到一种数据内容和数据存放地址之间的映射关系。
数组的特点是:寻址容易,插入和删除困难;而链表的特点是:寻址困难,插入和删除容易。那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表,哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法——拉链法,我们可以理解为“链表的数组”,如图:
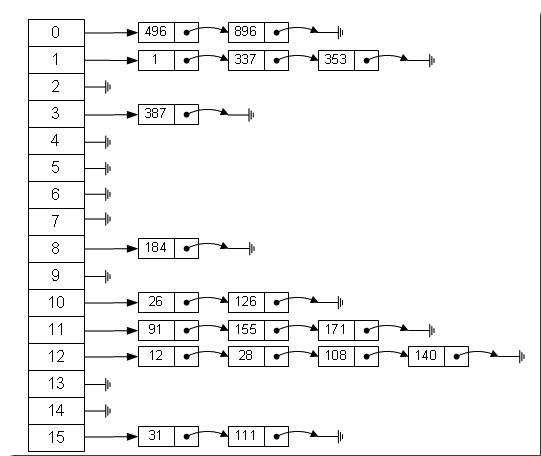
左边很明显是个数组,数组的每个成员包括一个指针,指向一个链表的头,当然这个链表可能为空,也可能元素很多。我们根据元素的一些特征把元素分配到不同的链表中去,也是根据这些特征,找到正确的链表,再从链表中找出这个元素。
元素特征转变为数组下标的方法就是散列法。散列法当然不止一种,下面列出三种比较常用的:
1,除法散列法
最直观的一种,上图使用的就是这种散列法,公式:
index = value % 16
学过汇编的都知道,求模数其实是通过一个除法运算得到的,所以叫“除法散列法”。
2,平方散列法
求index是非常频繁的操作,而乘法的运算要比除法来得省时(对现在的CPU来说,估计我们感觉不出来),所以我们考虑把除法换成乘法和一个位移操作。公式:
index = (value * value) >> 28 (右移,除以2^28。记法:左移变大,是乘。右移变小,是除。)
如果数值分配比较均匀的话这种方法能得到不错的结果,但我上面画的那个图的各个元素的值算出来的index都是0——非常失败。也许你还有个问题,value如果很大,value * value不会溢出吗?答案是会的,但我们这个乘法不关心溢出,因为我们根本不是为了获取相乘结果,而是为了获取index。
3,斐波那契(Fibonacci)散列法
平方散列法的缺点是显而易见的,所以我们能不能找出一个理想的乘数,而不是拿value本身当作乘数呢?答案是肯定的。
1,对于16位整数而言,这个乘数是40503
2,对于32位整数而言,这个乘数是2654435769
3,对于64位整数而言,这个乘数是11400714819323198485
这几个“理想乘数”是如何得出来的呢?这跟一个法则有关,叫黄金分割法则,而描述黄金分割法则的最经典表达式无疑就是著名的斐波那契数列,即如此形式的序列:0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144,233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946,…。另外,斐波那契数列的值和太阳系八大行星的轨道半径的比例出奇吻合。
对我们常见的32位整数而言,公式:
index = (value * 2654435769) >> 28
如果用这种斐波那契散列法的话,那上面的图就变成这样了:
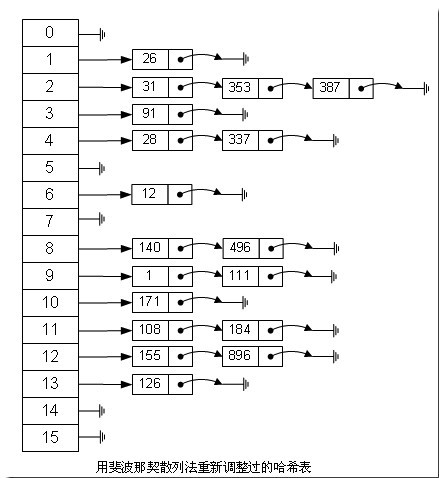
很明显,用斐波那契散列法调整之后要比原来的取摸散列法好很多。
适用范围
快速查找,删除的基本数据结构,通常需要总数据量可以放入内存。
基本原理及要点
hash函数选择,针对字符串,整数,排列,具体相应的hash方法。
碰撞处理,一种是open hashing,也称为拉链法;另一种就是closed hashing,也称开地址法,opened addressing。
扩展
d-left hashing中的d是多个的意思,我们先简化这个问题,看一看2-left hashing。2-left hashing指的是将一个哈希表分成长度相等的两半,分别叫做T1和T2,给T1和T2分别配备一个哈希函数,h1和h2。在存储一个新的key时,同 时用两个哈希函数进行计算,得出两个地址h1[key]和h2[key]。这时需要检查T1中的h1[key]位置和T2中的h2[key]位置,哪一个 位置已经存储的(有碰撞的)key比较多,然后将新key存储在负载少的位置。如果两边一样多,比如两个位置都为空或者都存储了一个key,就把新key 存储在左边的T1子表中,2-left也由此而来。在查找一个key时,必须进行两次hash,同时查找两个位置。
问题实例(海量数据处理)
我们知道hash 表在海量数据处理中有着广泛的应用,下面,请看另一道百度面试题:
题目:海量日志数据,提取出某日访问百度次数最多的那个IP。
方案:IP的数目还是有限的,最多2^32个,所以可以考虑使用hash将ip直接存入内存,然后进行统计。