论文原址:https://pdfs.semanticscholar.org/eeb7/c037e6685923c76cafc0a14c5e4b00bcf475.pdf
摘要
本文研究了利用深度神经网络及逆行自动语音识别(ASR)的语音模型,其输入是直接输入窗口形语音波(WSW)。本文首先证明了,网络要实现自动化需要具有于梅尔频谱相类似的特征,(梅尔频谱是啥?参考,https://blog.csdn.net/qq_28006327/article/details/59129110),本文研究了挖掘WSW特征的DNN结构。首先,改进的bottlenect DNN结构用于捕捉时域条件下不易表示的动态谱信息。基于DNNN的WSW内部的冗余信息也被考虑进来。WSW特征的语音模型与基于梅尔频谱相关性特征(MFSC)的语音模型在华尔街语料库数据集上进行比较。结果表明在WSJ语料库得到的基于WSW特征的语音模型要比基于MFSC特征的模型WER增加了3.0%。然而,当结合MFSC特征时,其相比于单独基于MFSC特征的DNNN的最好的模型降了4.1%.
关键词:语音识别,深度神经网络,Bottleneck 特征,波形语音
介绍
一些研究表明,可以通过利用深度神经网络来实现自动的语音识别,其输入为窗型语音波数据(WSW),大部分研究,利用多层网络结构,同时,在不同任务领域上进行评估表明,ASR word error rates(WERs,参考链接:https://zhuanlan.zhihu.com/p/59252804)其基于WSW特征可以合理的近似较为常用的MFSC特征。然而,基于此研究,基于WSW的语音模型仍无法与基于MFSC特征的方法相提并论。基于WSW特征的WERs模型相比MFSC的一般高出15%~20%。本文研究主要针对上述问题,建立了一个有效的网络结构,学习算法用于基于深度神经网络自动的特征分析,使性能超过基于MFSC的语音模型方法。
在自动语音识别领域,基于深度学习方法的语音特征分析本文分三部分说明。第一个是输入为WSW特征的DNN模型的分析。搞清楚这类模型对于表示动态频谱还是静态频谱的表示信息较好,以及其在不同的信噪比源变化中其鲁棒性。实验表明,深度网络可以从WSW特征中学到与MFSC中的梅尔频谱相似的表示特征。这些特征可以用深度全连接网络或者卷积网络结构进行实现。第二部分是针对网络的权重进行分析。表明,在基于华尔街语料库全连接DNN网络的前几层的表示与梅尔频谱特征相类似,但用到的语料库的大小更小。
研究的第二部分为替换网络的结构来解释语音信息无法从窗型语音波中自动学习得到。本文重点研究了基于WSW的DNN对动态超段频谱建模的能力。人类语音识别中的谱变换及语音识别模型中的谱变换二者具有十分重要的地位。特征变化的速率所包含的信息从短时间语义段中得到。该语义段通过对MFSC特征执行傅里叶变换得到的模型谱进行描述。
在基于MFSC的语义模型中,谱动态通过利用多个级联的谱向量形式形成的特征向量或将频谱差异系数添加到静态相关性中来捕捉。这样特征表示可以捕捉150毫秒至250毫秒的谱运动。这种特征对于基于WSW的DNN网络即使增大窗型波的时间间隔也很难从音波中学习到。在section2中可以将网络结构结合bottleneck层来对特征进行捕捉,可以对250ms的帧输出进行拼接。
本文第三部分提出即使是基于DNN语音模型也可以达到与基于MFSC特征最好的系统的性能效果,但仍需额外的计算复杂度及冗余。该假设是将一个较为简单的梅尔 filterbank用一个训练好的全连接或者部分链接的深度网络的权重进行了替换。对于全连接DNN。网络的每层超过1,000,000次操作。在第四章考虑了自动训练的filterbank的冗余性。
第二章描述了基于WSW的DNN隐藏层训练权重的分析。第三章描述了连续的bottleneck特征为基于WSW的DNN提供了一个改进的谱动态模型。
基于WSW的DNN的分析
本节分析了在由华尔街语料库得到的WSWs训练的DNN的中间层的表示。首先,描述了DNN的网络结构,然后接下来的实验中用到的语料库,最后是第一层训练权重分析的结果。
语义模型结构及训练:基于WSW的DNN的输入帧是为150ms采样语音波形的一部分。本文中使用宽带为16KHz采样语音的2400个采样段。对于每个分析帧,输入的位置应该提前10ms或者160个样本。对于一个包含三个隐藏层的全连接DNN,每层由1024个节点。节点后通过ReLU进行非线性变换。输出层采用2019个节点的softmax层,每个代表这隐马尔科夫模型中的上下文依赖性(context dependent CD)。
语料库及模型的训练:华尔街语料库用于训练及评估本文中的所有语音模型。包含在一个较高信噪比的环境中报纸阅读话语的记录。WSJ0/WSJ1 SI-284用于训练所有的HMM及DNN语音模型。包含时长80小时的语音及37961个话语,来自284个说话人。Test-Dev93包含515个话语用作validation set,Test-Eval92包含330个话语用于测试,使用对应于20000字的开放词汇语言模型的测试条件用于所有评估。自动语音识别的解码器基于连续密集的HMMs高斯混合(HMM-GMMs)用于对齐语音框中CD HMM状态及MFCC(频率倒谱系数),HMM-GMM自动模型训练及状态上下文聚类到2019个CD状态通过KalDI工具进行实现。这些模型利用MFCC通过LDA及最大似然线性变换(MLLT)变换后的特征进行训练。训练过程中同时用到了训练这适应性训练。ASR解码器将2019个CD状态标签的一个分配到待训练的语音帧上,作为DNN进行交叉训练的监督。
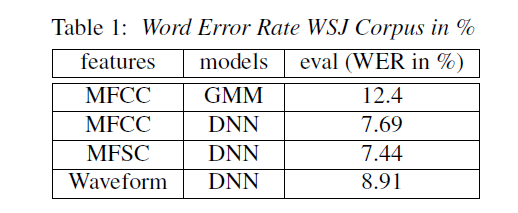
对标准的WSW DNN进行评估:为了评估混合HMM-DNN ASR系统的基本性能,上述描述的网络结构使用多个特征集进行训练,包含带有MFCC的WSW特征以及MFSC特征。HMM-GMM与HMM-DNN系统的比较如下表1所示。通过前两行比较可以发现,HMM-DNN相比HMM-GMM在WER上有较大幅度的降低。与MFCC特征相比,MFSC特征的WER相对减少3%。最下方基于WSW特征在WER上相比MFCC特征增加了15.5%。
在基于华尔街语料库上可以在没有特定设计特征的原生语音样本上定义的语音模型可以使WER降到9%以下。可以通过从分析网络参数中管擦汗到参数估计捕捉的信息来得到一些灵感。在权重矩阵W中,使用一个梅尔频谱形的表示。在基于WSW的DNN的第一层,如下图所示,表明与此权重矩阵相关联的值及根据这些行上的数值计算对数幅度谱可以看出来其近似于带通滤波器的响应。
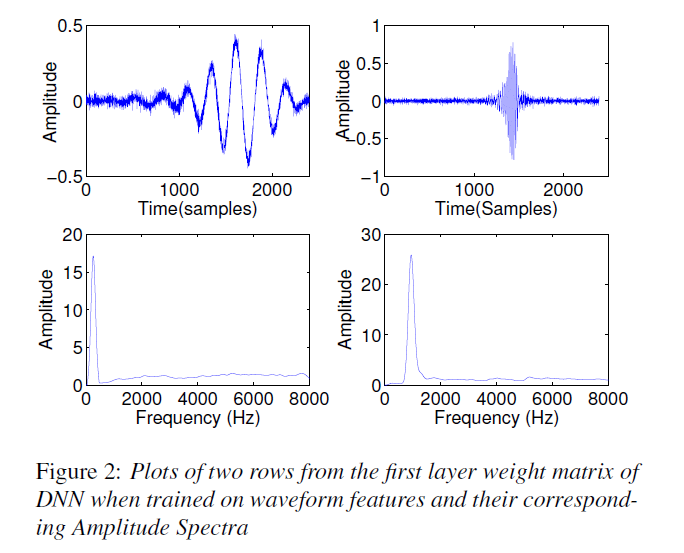
下图1展示了权重矩阵W1024行包含信息的总结。图中的第i行表示权重矩阵W中第i行的平滑对数幅度谱。平滑对数幅度谱通过对w进行padding,并对权重计算其快速傅里叶变换![]()
,然后使用一个高斯核进行平滑处理。权重矩阵W的行数根据平滑后谱中每行的峰值计算得到的频率进行记录。最终对于记录的行数根据![]() 进行描点。由图中可以看出DNN已经学习到了类似于梅尔频谱的特征表示。
进行描点。由图中可以看出DNN已经学习到了类似于梅尔频谱的特征表示。

stacked bottoleneck architecture
本节描述将bottleneck DNN应用到基于WSW的DNN语音模型中。该改进模型可以看作是一种机制,用于连续的将低维的bottleneck frames进行拼接,从而可以对帧间谱动态进行建模。ASR中许多基于BN DNN结构被提出来。其通用的结构形式如下图所示,BN-DNN通过级联一些高维度的非线性隐藏层及低纬度的隐藏层构建。这种设计的最初动因是对非线性空间进行降维处理。
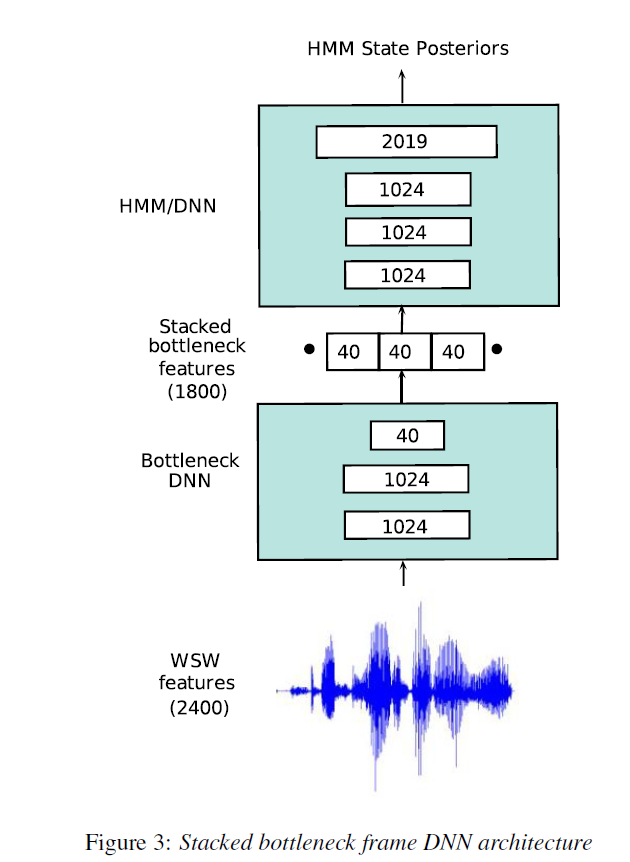
如上图所示,输入维度为2400(包含150ms)及一个40维度的bottleneck。一些BN-DNN通过拼接帧附近的bottleneck层的输出得到的局部谱信息进行增强。当将MFSC特征应用到BN-DNN时,BN只减少了一点WER。bottleneck谱信息的结合对于基于WSW的DNN是一个研究点,这是因为无法通过简单的方法在特征分层次对谱信息进行利用。因此,期望基于WSW 特征的BN-DNN结构可以拼接bottoleneck输出进而对ASR WER产生一个较大的影响。
BN-DNN的结构设计如下:2400个输入节点对应着2400采样WSW,两个1024节点的隐藏层。及一个40个维度的bottleneck层。每层后面跟着一个ReLU。bottleneck层在具有1800个一二阶不同相关性节点向量的15帧进行拼接,表示150ms内频谱的动态变化。在解码过程中,级联的bottleneck输出送到三个1024维度的隐藏层的网络及2019节点的softmax输出层,DNN中softmax的输出对应HMM中上下文的相关状态(CD)。
上图3下半部分显示的BNN-DNN中的DNN层分离出来进行训练,图的上半部分为HMM/DNN。BN-DNN基于CE损失标准进行训练,训练后,将bottleneck层移除,同时将BN层的激活值进行保留作为BN-DNN的输出。
基于WSW及MFSC特征的BN-DNN WER性能结果如下图所示。将1,3行进行比较,基于MFSC特征对模型增加stacked bottleneck WER并没有发生很大的改变。这是由于1800维的MFSC特征作为BN网络的输入已经被拼接的15帧MFSC 帧图像格式化了。将第2行与第4行进行比较发现。BN-DNN将WSW特征的WER降低了14.2%,已经同最好的基于MFSC的WER很接近了。
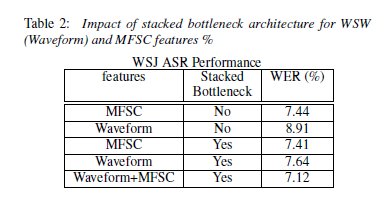
对WSW/MFSC特征结合使用,对于10ms,窗型输入,40维的WSW的BN-DNN与40维的MFSC向量进行拼接。80维的向量与+/-7帧向量进行拼接作为输入传到bottleneck中。上图最后一行显示了结果,相比MFSC特征WER,减少了%4。
基于WSW的DNN训练结构初始化
通过前面对网络第一层度权重矩阵的分析,训练一个基于WSW的全连接DNN可以得到一个具有识别结构的网络。其包含的结构可能对于分类性能很重很。但很难从轶事中观察中进行表征。一种方法是增加一个类似于filter-bank的结构,选择一个与梅尔filter-bank特征分析类似的参数化。本文的工作重点是研究是否可以通过训练一个全连接网络来发现这个结构。确定研究网络的哪个部分来通过连续的迭代来提升网络的性能及效率。根据图1的第一层权重矩阵相邻行显示了大部分情况下中心频率相似,但相位及增益不同的filter的响应。通过观察,是否可以将该层进行隔离,从而可以使DNN更有效训练的结构。
设计了两步过程,根据少量的"basis rows"的延迟及缩放变换来近似权重矩阵第一层的行。在过程的第一步,得到与带通滤波器相关的矩阵行数,该带通滤波器的中心频率接近于梅尔滤波器的中心频率。
其可以作为"basisi rows",用 进行表示。在第二步,将最接近basis rows hi中心频率的滤波器的权重矩阵被看作是basis rows的缩放或者延迟版本。即对于权重矩阵第wj行,
进行表示。在第二步,将最接近basis rows hi中心频率的滤波器的权重矩阵被看作是basis rows的缩放或者延迟版本。即对于权重矩阵第wj行,
其近似
 ,其中,a_i,j 及d_i,j分别代表wj相对于hi(其傅里叶变换于带通滤波器的中心频率最相似)缩放尺度及延迟数值 。
,其中,a_i,j 及d_i,j分别代表wj相对于hi(其傅里叶变换于带通滤波器的中心频率最相似)缩放尺度及延迟数值 。
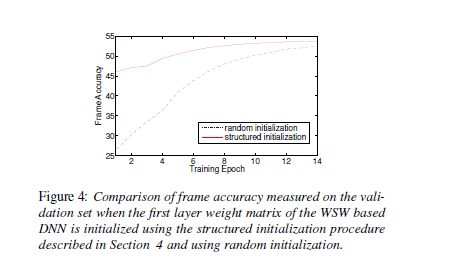
上述形成的具有行形式的第一层权重矩阵用于初始化训练一个新的基于WSW的DNN。下图显示了基于前文初始化得到的每个训练使其的验证集的帧精度(FAC)。与随机初始化的DNN参数得到的FAC进行比较,基于第一层权重矩阵的结构初始化,FAC的精度始终更高。另外,结构初始化使WER进行小幅度的下降。7.64%下降至7.51.同时,还使basis row与第一层权重矩阵的剩余行之间的平均近似误差减小。