前面的近似策略是寻找了 energy functional 的近似,该近似导致了 LBP,这使得 message passing 的算法不变。近似使用 I-projection,尽管这个一般说来并不容易得到解,但是给出了 partition function 的下界。这部分我们讨论的第一个策略是尽量保持目标函数不变,而在更新的时候使用近似的消息。
这个想法来自这样一个观察:如果我们用消息的 M-projection,比如离散变量情形,如果假定了近似分布是 factorized,我们根据前面的结论就知道这相当于要求在这些 margin 上近似分布与 message 相同。咋一看 M-projection 似乎使我们得到了更好的算法(因为有解析解了),但是问题是我们在原分布上做 inference,这些边际分布往往是 intractable 或者未知的。但是这里的 trick 就是如何 decompose 原来的 graph,如果我们得到的两个子图仍然具有比较复杂的结构,那么计算 message 就会比较麻烦(因为需要 marginalize 掉一些变量),但是如果我们让这些子图都是简洁的 tree 这种,我们可以直接用 BP 就能快捷的计算出来需要的 margin 了,这意味着这时的近似消息成为了可能!这样我们的基本思路就是沿用 LBP 的框架,将消息替换成为 M-projection 获得的简化版本。
对 message passing 的另一种参数化,即 belief update 而言,对精确的情形我们有 
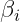





为了能够方便的计算我们的 approximate message,我们将候选的近似分布选择为指数族,事实上指数族的 M-projection 导致了 moment matching 这个要求:以上方法我们首先需要为 belief 获得近似,通过指数族的 sufficient statistics 上的 matching(如果我们能能算,否则 EP 就不能用,如 MRF),我们就可以得到 ,另一方面我们因为 message 也是 exponential family,我们有
EP 有一个问题是对 BN 很多时候可以获得合适的 M-projection,但是更新的策略却往往无视了参数空间的约束,这导致 EP 迭代中可能获得非法参数,某些问题中这可能导致严重的后果。
那么 EP 对应于一个什么样的优化问题呢?从某个角度我们很容易发现,那就是以上更新公式将参数放在一起
这等价于要求两侧的矩 matching,而不是原先的分布是 consistency 的:
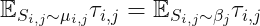
而与前者一样使用的都是近似的 energy functional。我们对这个问题使用 Lagrange multiplier 就可以证明,EP 的消息传递等价于对应的 fixed point equation 的迭代。
正是由于这个方法使用了近似的消息,我们无法保证其收敛性,这也是它与后一种方法(structured variational approximation)的重要区别。这里我们将近似函数族选的足够的简单,使得上面的 inference 非常容易,常见的选择就是让这个部分 factorized 足够厉害,当然这表示近似分布的表述力也会比较有限,然而我们得以可以优化精确的 free energy(也是 I-projection)。
那么这种想法最极端的形式(mean field approximation)就是将近似分布选择为完全独立的情况,此时自由能中 factor 部分成为 
ight) log phi(u_phi)")
这导致了很简洁的更新方式,每次固定其他的更新某一个 
完全独立便于推导,但是其表述能力比较有限,比较自然的想法就是 decompose 的时候不要那么彻底,而是保留些结构(与 EP 在这方面的想法类似)。这时,我们假定有一个我们设定的分解记为 
![psi_j (c_j) propto expleft( mathbb{E}_Q [log ilde{P}_Phi mid c_j] - sum_{k
eq j} mathbb{E}_Q [log psi_k mid c_j]
ight)](http://s0.wp.com/latex.php?zoom=1.5&latex=%5Cpsi_j+%28c_j%29+%5Cpropto+%5Cexp%5Cleft%28+%5Cmathbb%7BE%7D_Q+%5B%5Clog+%5Ctilde%7BP%7D_%5CPhi+%5Cmid+c_j%5D+-+%5Csum_%7Bk+%5Cneq+j%7D+%5Cmathbb%7BE%7D_Q+%5B%5Clog+%5Cpsi_k+%5Cmid+c_j%5D%5Cright%29&bg=ffffff&fg=111111&s=0 "psi_j (c_j) propto expleft( mathbb{E}_Q [log ilde{P}_Phi mid c_j] - sum_{k
eq j} mathbb{E}_Q [log psi_k mid c_j]
ight)")
同样我们可以获得类似的算法和证明收敛性。另外有一些关于简化 MRF 分解的东西后面再仔细看看吧。
另外一种策略是使用 local variational bound。这就是为我们 maximize 的 objective function 找到合理的下界,这样我们通过 optimize 一个更简单的目标函数得以最大化目标函数的下界。常用的 lower bound 就是通过凸函数的 Legendre-Finchel 变换后获得的界(往往是在 local 区域逼近较好)进行优化(调整 variational parameters)。
最后想谈一下与 PRML 在这方面的比较。读书笔记节选的七和八对应于 PRML 中第八章和第十章,很显然 PRML 对 exact inference 讲的比较详细,更侧重于“过程”,PGM 这部分更偏重理论;对于 LBP,PRML 仅仅一带而过。PGM 将几种近似的策略从优化的角度完美的统一了起来,进行了细致的区分,每种算法都可以用 stationary point 处满足的 fixed point equation 获得迭代的算法,这的确是比 PRML 上通过一些具体例子讲的更加理论和清晰。总体感觉来说 PRML 将几种解决问题的思路与一些具体的例子(特别是 machine learning 里面常见的例子)结合的比较清楚,特别是一些连续变量的情形,这方面我觉得需要在看完 PGM 后重新认识一下,推导一下。
——————
And Abimelech took sheep, and oxen, and menservants, and womenservants, and gave them to Abraham, and restored him Sarah his wife.