一、集合的常用扩展方法(lambda的方式)
1.Where() 根据条件选择数据
2.Select() 根据数据条件转换成新的数据类型,类似于DTO转换类


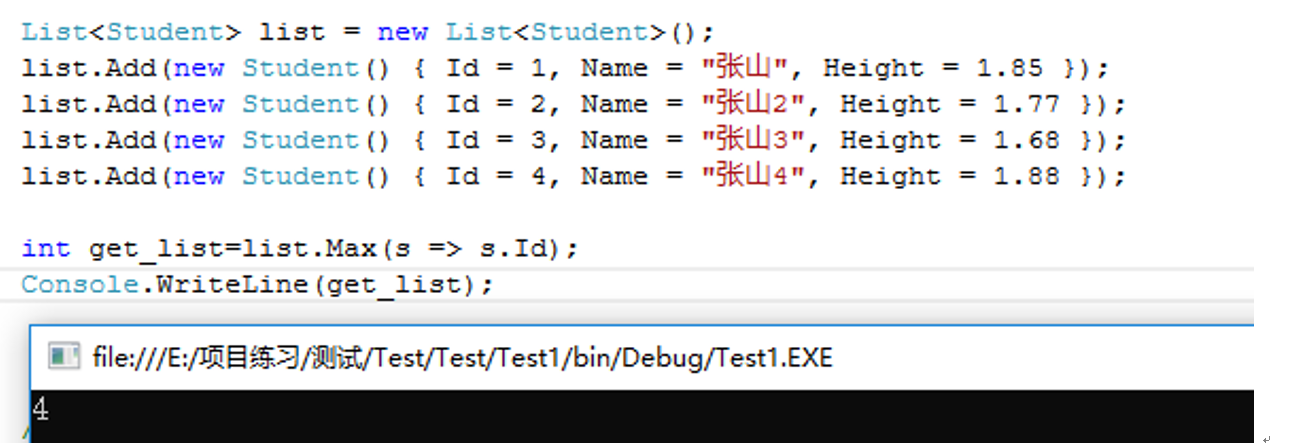
3.Max() 根据条件选择最大值
4.Min() 根据条件选择最小值

5.OrderBy() 根据条件升序排序
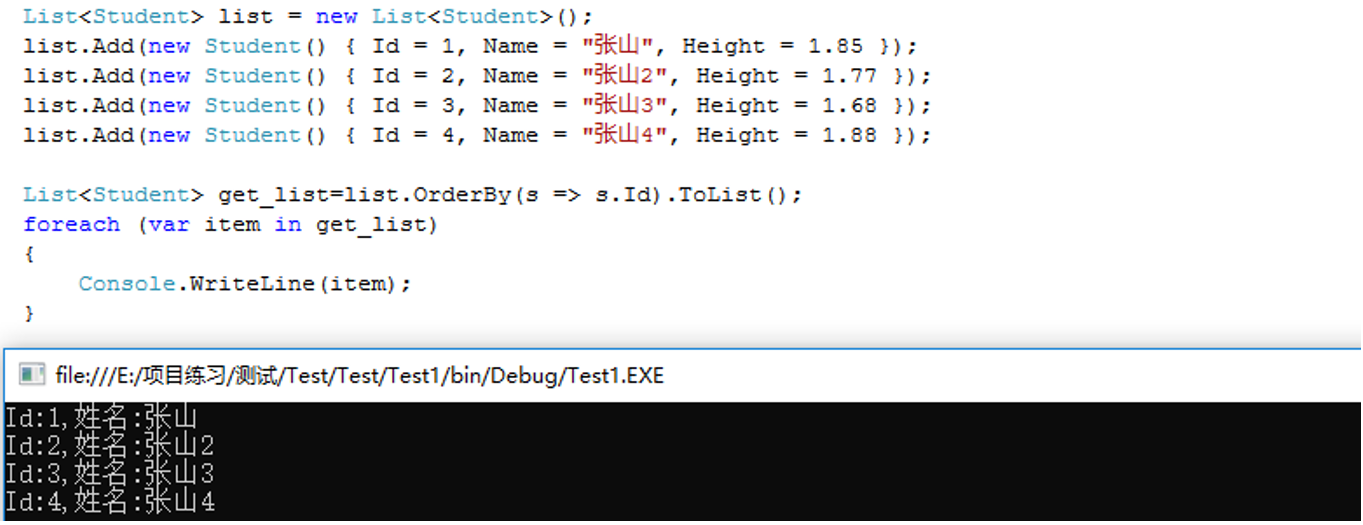
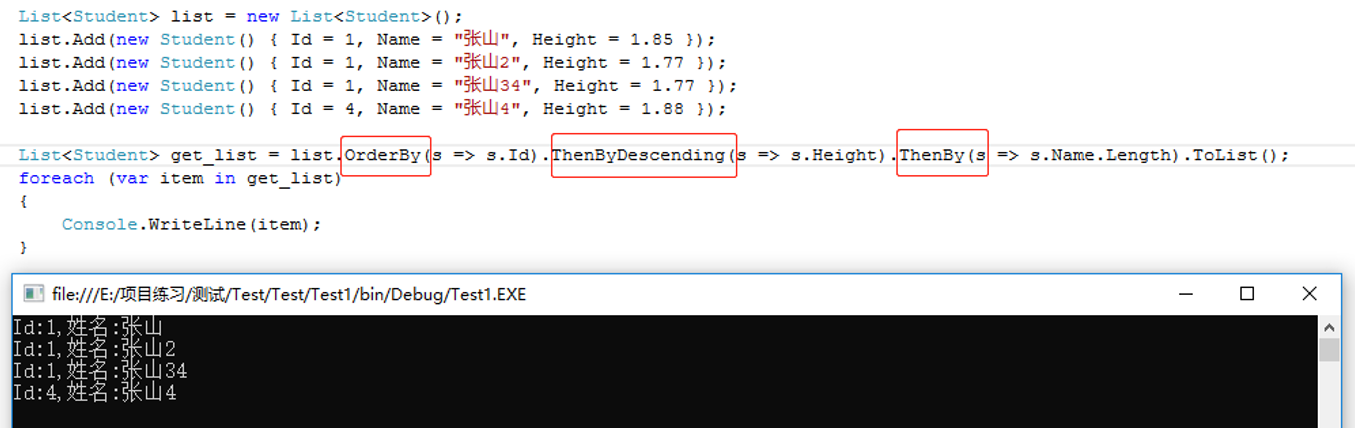
如果升序中Id都为1,那么就根据第二个条件进行升序排序,使用ThenBy
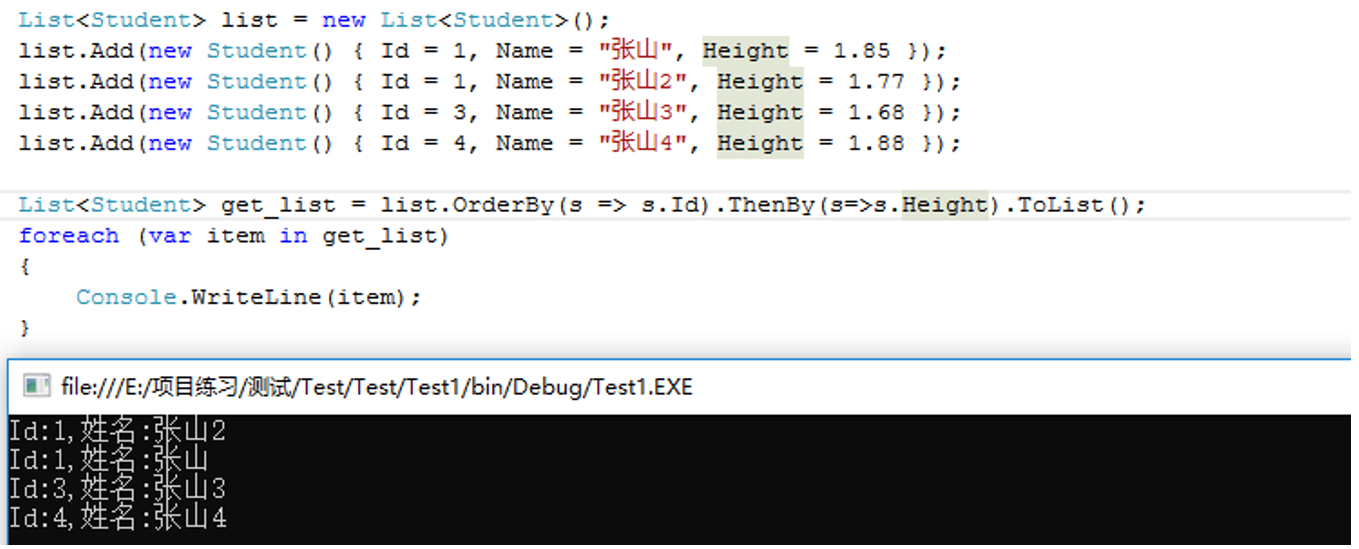
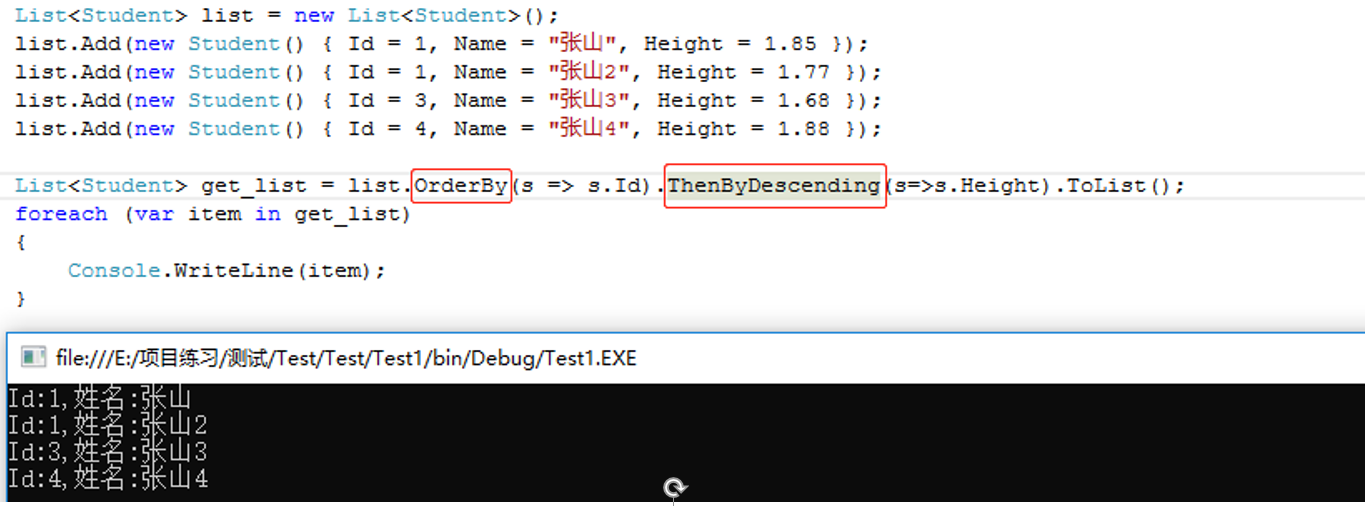
ThenByDescending()紧接着倒序排序
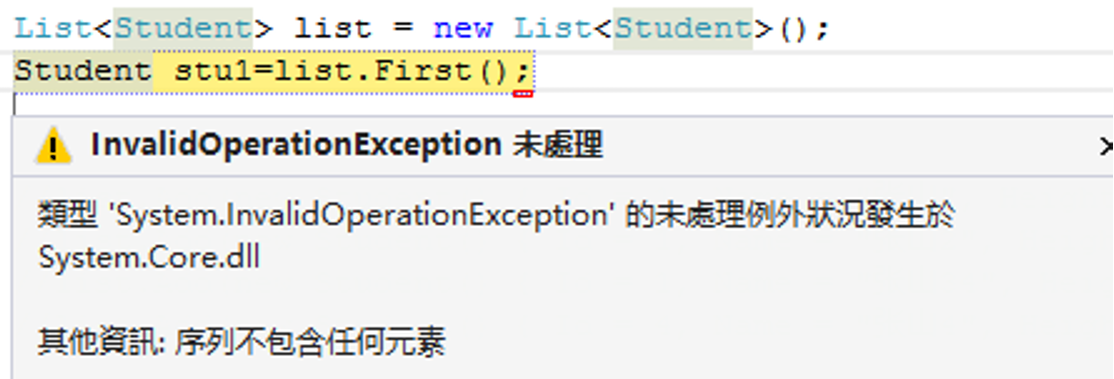
6.First() 获取第一个(如果不存在则报错)
7.FirstOrDefault() 获取第一个,如果不存在则返回null或默认值

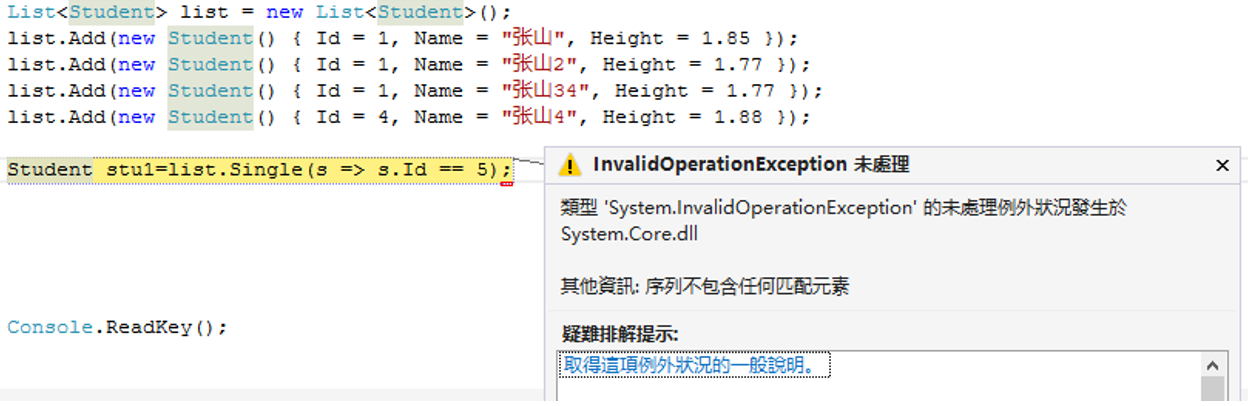
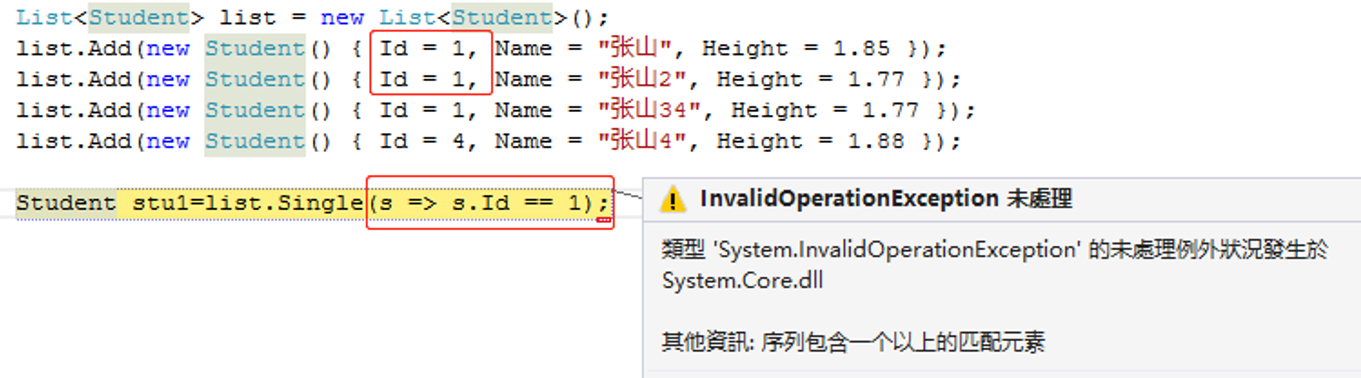
8.Single() 获取唯一一个,如果没有或者多个则报异常
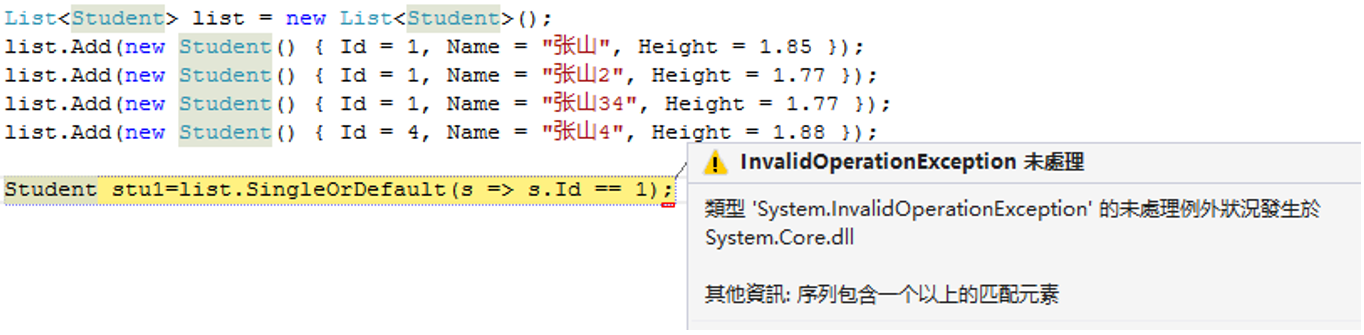
9.SingleOrDefault() 获取唯一一个,如果没有则返回默认值,如果多个则报错
10.Any() 判断集合中是否包含元素,如果有返回true,否则返回false。一般比Count效率高。因为Any()只要查询到数据就返回,Count是统计数据的数量。Any还可以指定条件表达式。

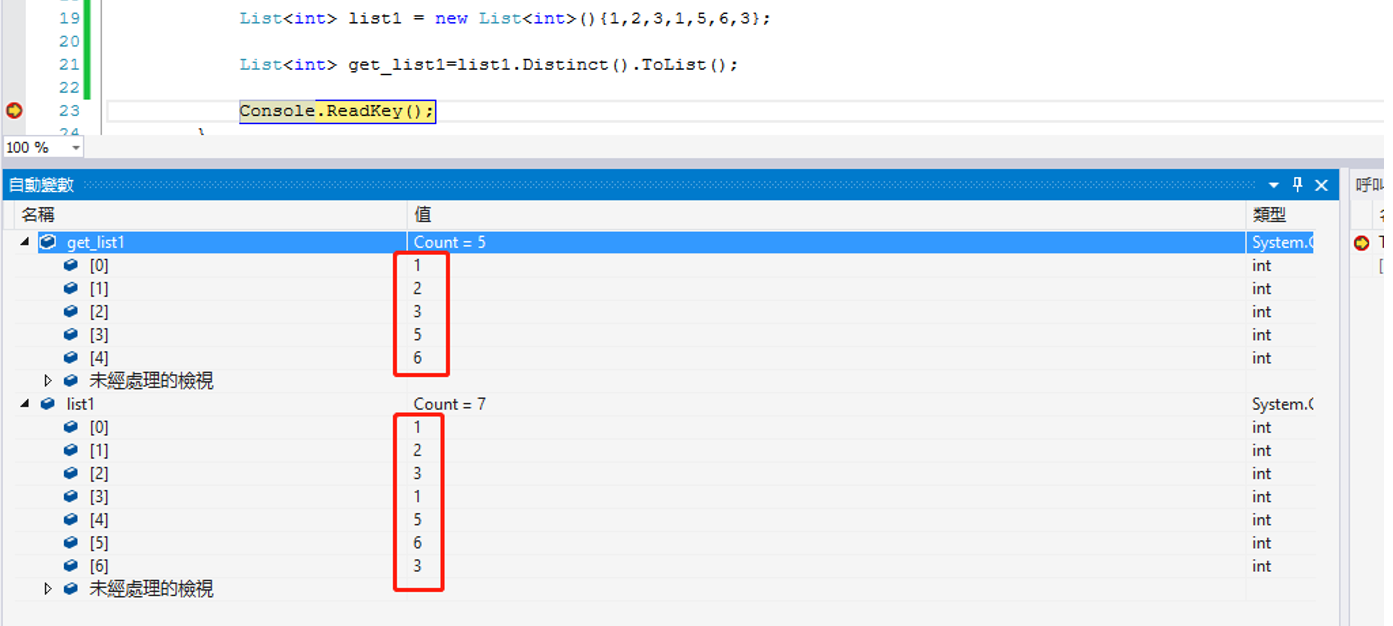
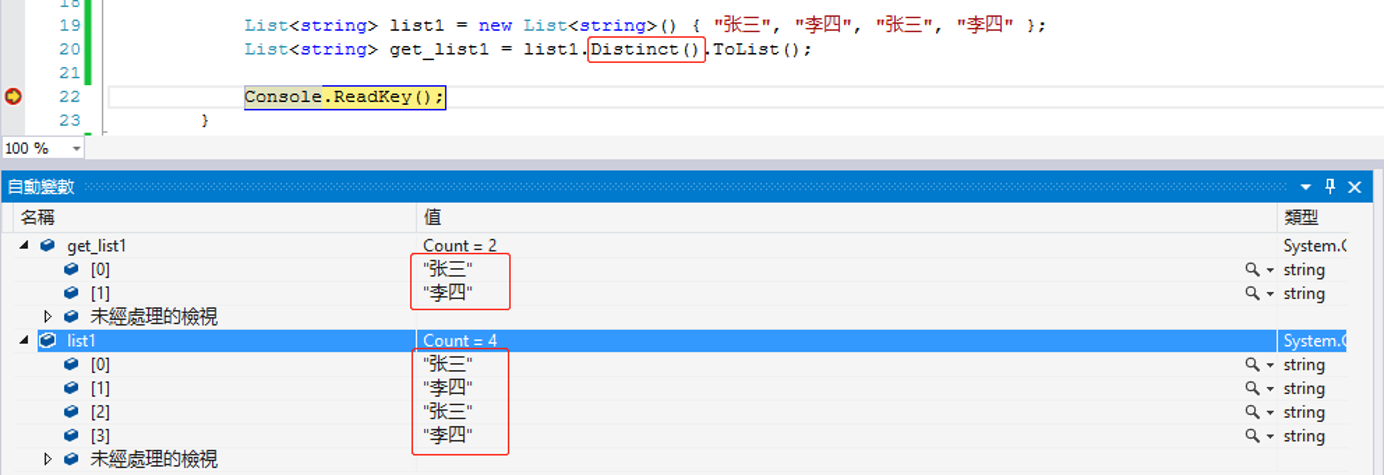
11.Distinct() 去除重复数据
(1)int类型的集合:List<int>。
(2)string类型的集合:List<string>
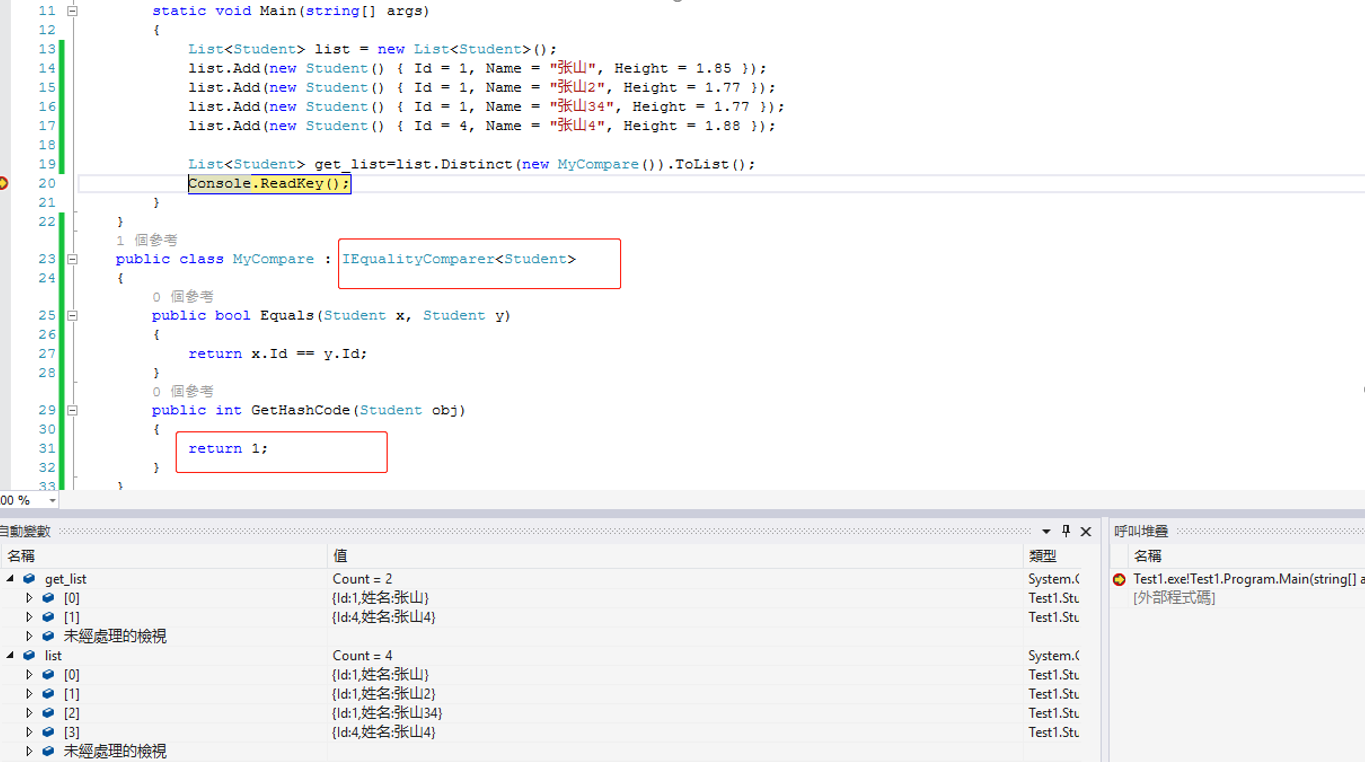
(3)对于自定义类的集合去重复
使用Linq中Distinct方法内进行比较的是对象引用,判断的是对象是否引用同一个对象,而不是对象的属性。因此我们使用对象集合使用Distinct方法时要使用重载
Distinct<TSource>(this IEnumerable<TSource> source, IEqualityComparer<TSource> comparer);
要使用这个方法,重写IEqualityComparer接口,再使用Distinct方法:
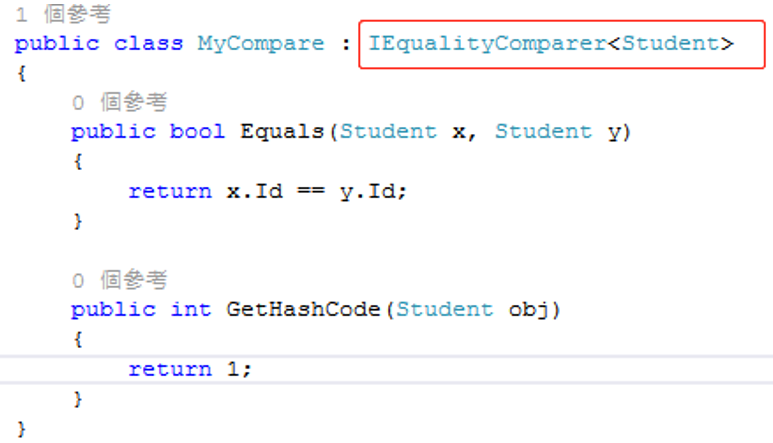
由于直接获取对象的HashCode,用HashCode进行比较的速度比Equals方法更快,因此IEqualityComparer内部会再使用Equals前先使用GetHashCode方法,再两个对象的HashCode都相同时即判断对象相同。
而当两个对象HashCode不相同时,Equals方法就会被调用,对要比较的对象进行判断。由于在List集合中两个引用实际上是两个不同的对象,因此HashCode必定不相同,所以要触发Equals方法,只需要改GetHashCode,让它返回相同的常量。
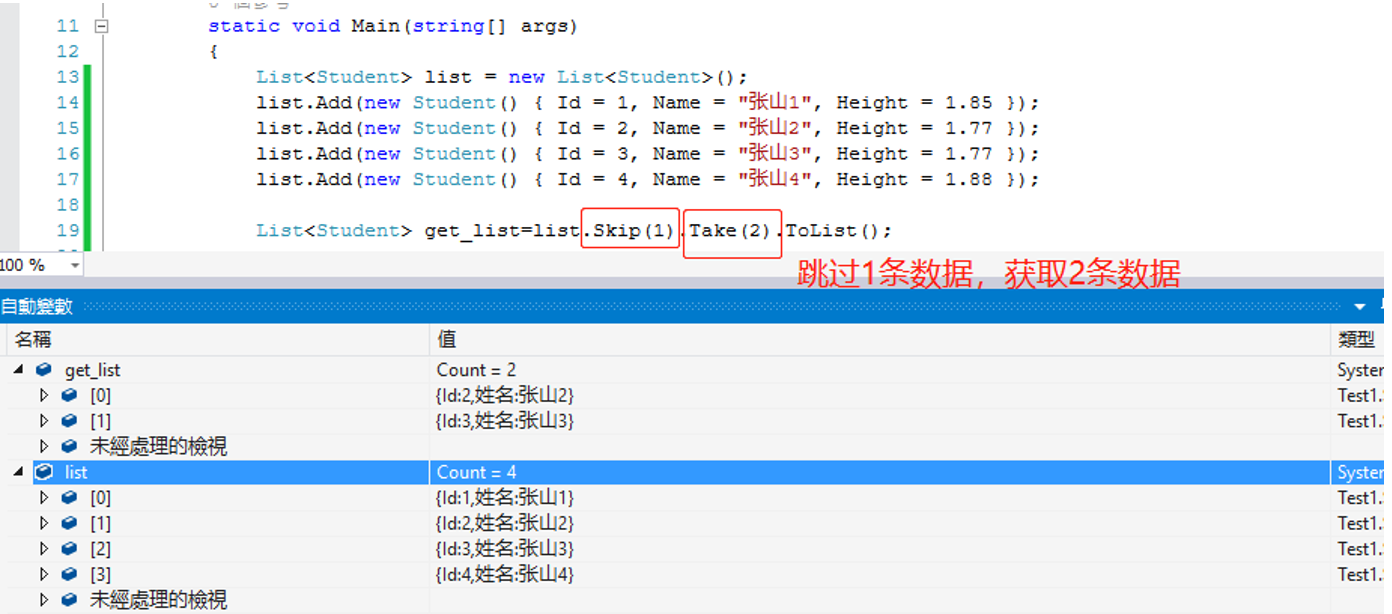
12.Skip(n)跳过前n条数据,Take(m)获取最多m条数据,如果不足m条也不会报错。
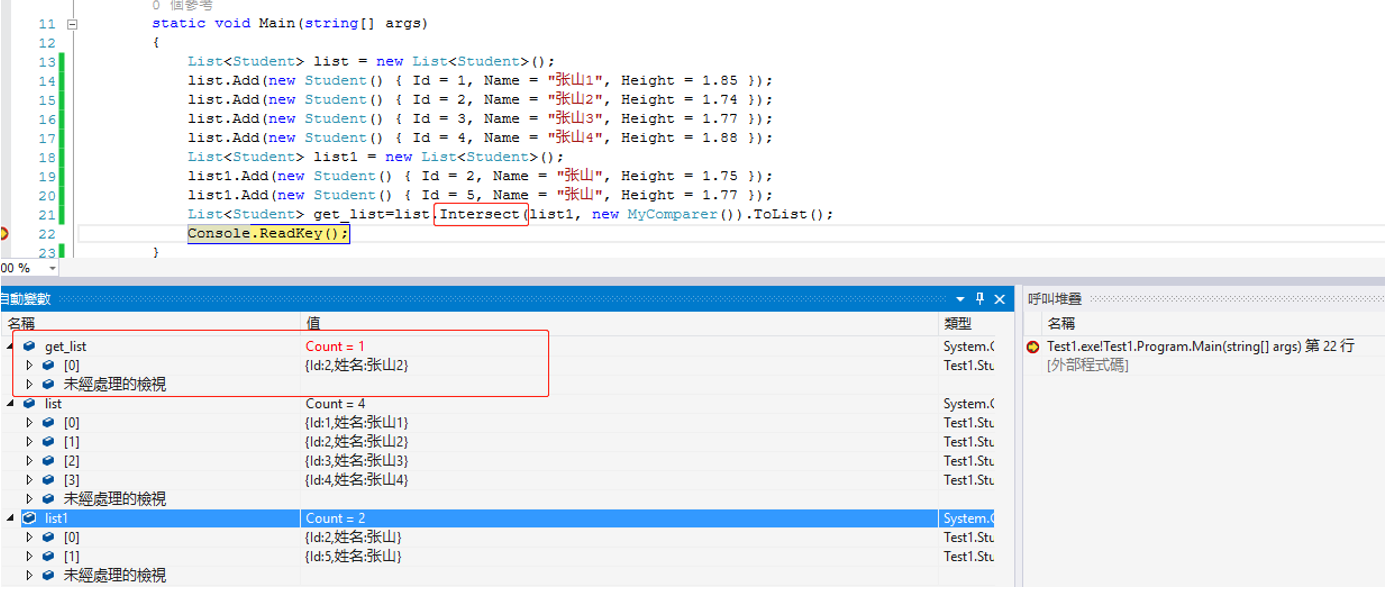
13.Except(item1) 排除当前集合中在item1中存在的数据。
如果是自定义集合,需要同Distinct方法一样实现IEqualityComparer接口
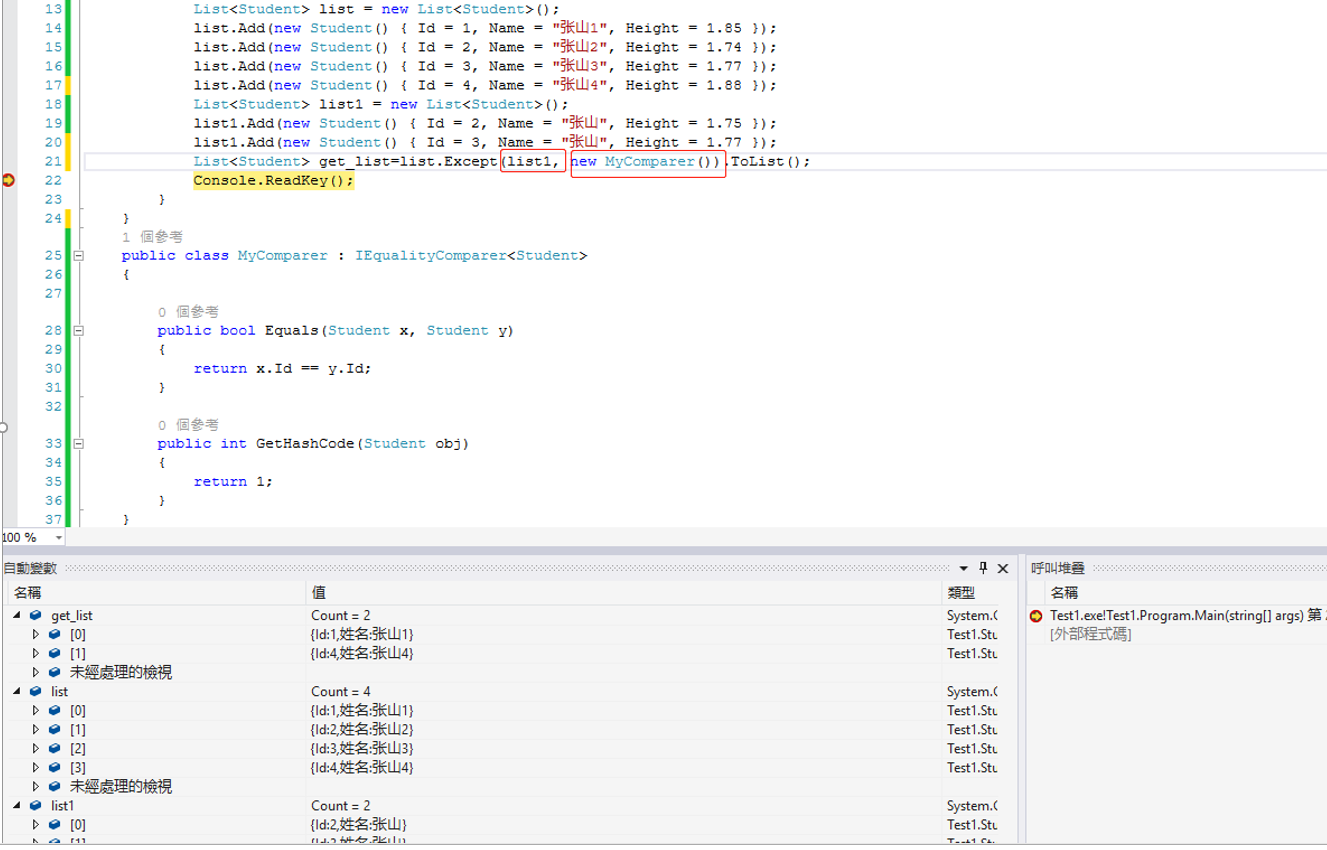
14.Union(item1)把当前集合和item中元素组合(求并集)
自定义集合实现IEqualityComparer
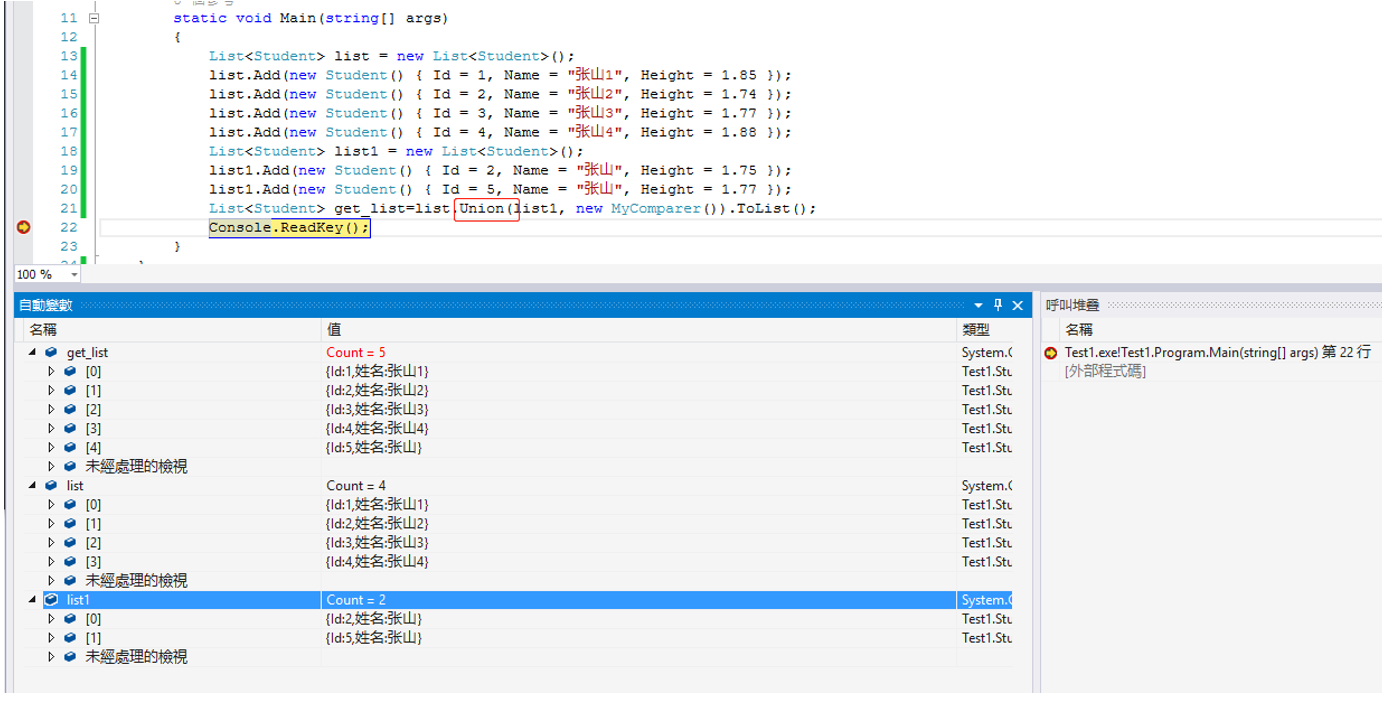
15.Intersect(item1) 把当前集合和item中元素求交集
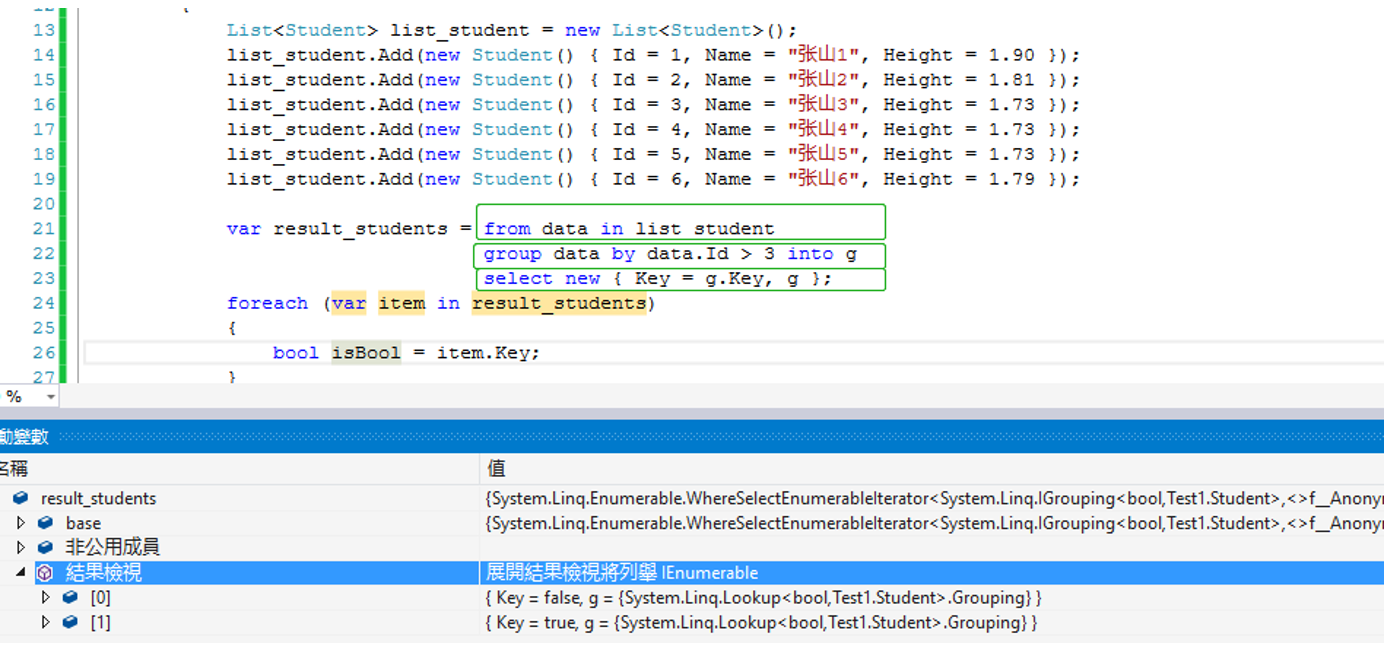
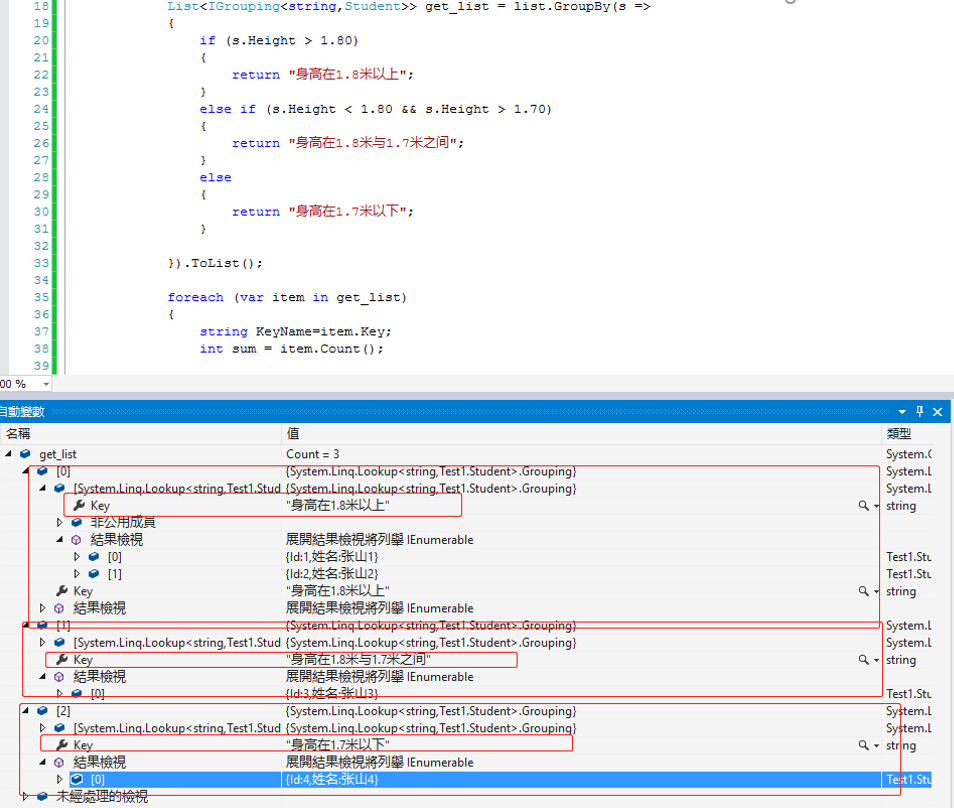
16.GroupBy() 分组(其中Key值是分组返回值)

按照string类型进行返回值
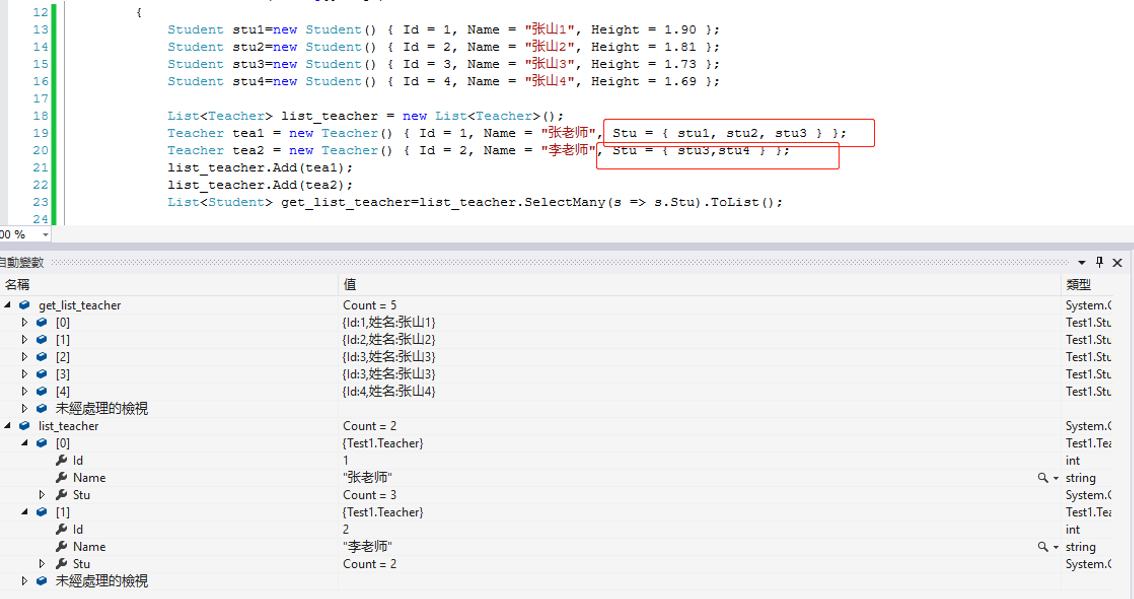
17.SelectMany() 把集合中每个对象的集合属性的值重新拼接为一个新的集合(不能去除重复数据)
18.Join() 联合查询(可以查询两个表某个属性相同的数据)
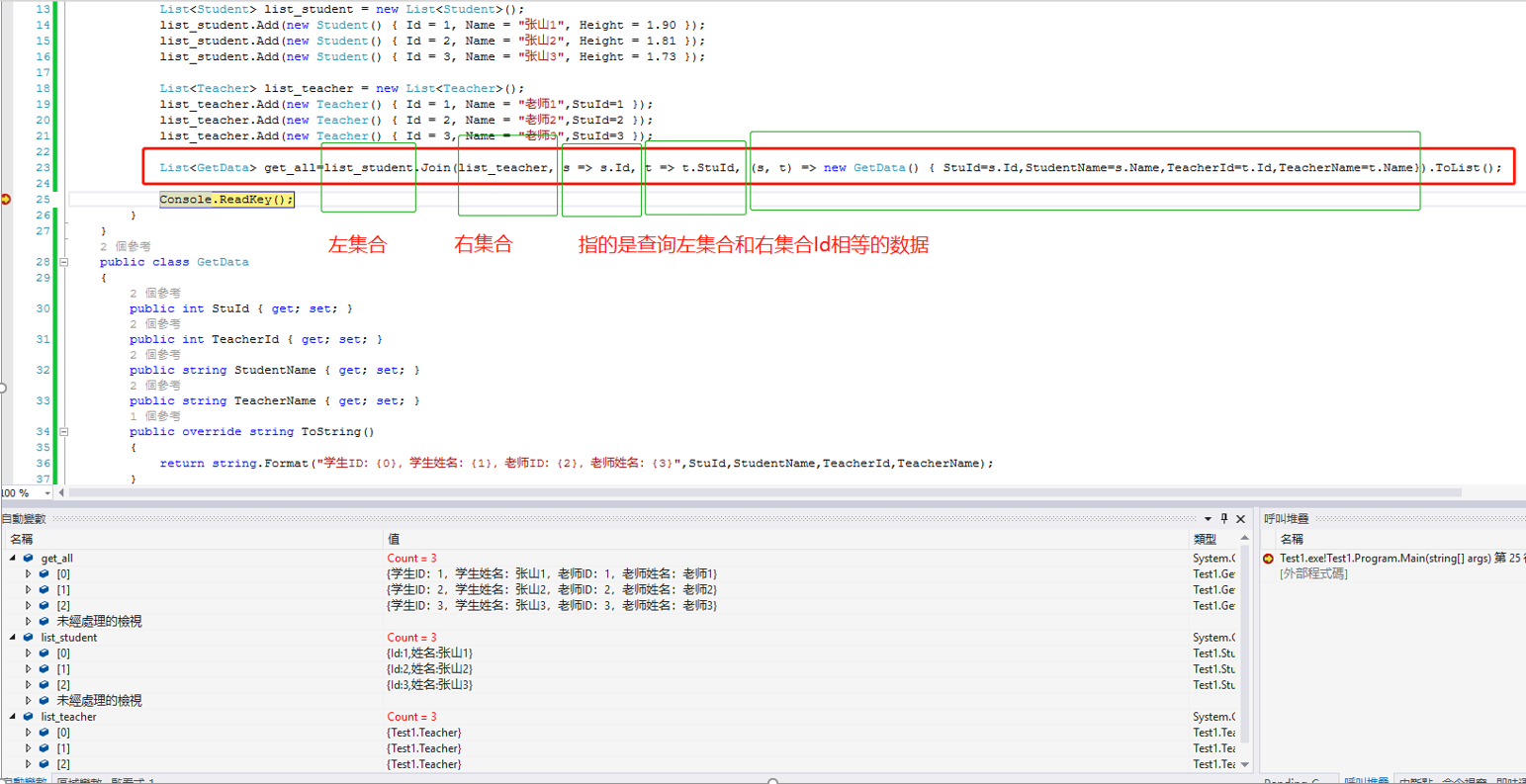
使用扩展方法,本人只找到添加一个条件查询,没有找到添加多个条件查询,但是使用Linq方式的Join可以使用添加多个条件查询。
二、Linq写法
上面介绍的是lambda的方式写的,下面介绍的是Linq的写法。两种方法可以相互替代,没有哪个好哪个坏的区别。在编译器编译的时候,使用Linq的写法最终都被编译成了lambda的方式的写法(通过反编译工具可以看出)
建议:需要join等复杂用法的时候Linq更易懂,一般的时候lambda方式的写法更清晰、紧凑。同时这两种写法可以混合书写。
必须是:from 变量 in 集合,并且是select xxx结尾
1.Where(s=>s.Id>2)写法:

2.Select(s=>new GetData(){Id=s.Id,Name=s.Name})写法:

3.OrderBy(s=>s.Id). ThenBy(s=>s.Name.Length);写法

4.Join联合查询(两个集合的条件判断相等不能使用”==”,而是使用equals)
一个条件的联合查询
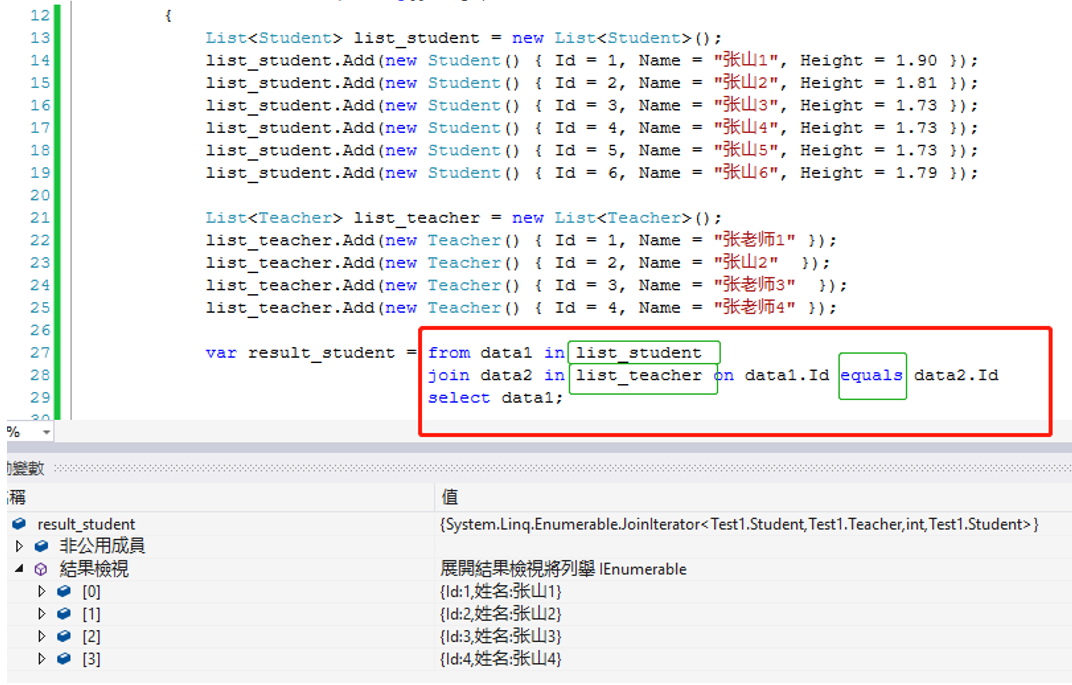
多个条件查询

5.group by 分组