官网
https://doc.dpdk.org/dts/test_plans/pvp_vhost_user_reconnect_test_plan.html
DPDK Vhost with virtio-vhost-user support
https://github.com/ndragazis/ndragazis.github.io/blob/master/dpdk-vhost-vvu-demo.md
vhost_user_live_migration_test_plan.rst
https://oss.iol.unh.edu/dpdk/dts/blob/1413f9a3ba21ed1ceaa87f208d502530edcd15d4/test_plans/vhost_user_live_migration_test_plan.rst
DPDK Sample Applications User Guides(35)Vhost示例应用程序
https://blog.csdn.net/qq_42138566/article/details/89443131
基于 CentOS 7.x 的 DPDK Vhost-User 环境搭建
https://blog.csdn.net/DrottningholmEast/article/details/76651505
https://my.oschina.net/u/4359742/blog/3314035
1. Introduction to virtio-networking and vhost-net (总览,适合想了解初步原理)
2. Deep dive into Virtio-networking and vhost-net (深入,适合对技术感兴趣)
3. How vhost-user came into being: Virtio-networking and DPDK (总览)
4. A journey to the vhost-users realm (深入)
5. Achieving network wirespeed in an open standard manner: introducing vDPA (总览)
6. How deep does the vDPA rabbit hole go? (深入)
附加几篇动手文章:
1. Hands on vhost-net: Do. Or do not. There is no try
2. Hands on vhost-user: A warm welcome to DPDK
3. vDPA hands on: The proof is in the pudding
In this post we will set up an environment and run a DPDK based application in a virtual machine. We will go over all steps required to set up a simple virtual switch in the host system which connects to the application in a VM. This includes a description of how to create, install and run a VM and install the application in it. You will learn how to create a simple setup where you sent packets via the application in the guest to a virtual switch in the host system and back. Based on this setup you will learn how to tune settings to achieve optimal performance.
Setting up
For readers interested in playing with DPDK but not in configuring and installing the required setup, we have Ansible playbooks in a Github repository that can be used to automate everything. Let’s start with the basic setup.
Requirements:
-
A computer running a Linux distribution. This guide uses CentOS 7 however the commands should not change significantly for other Linux distros, in particular for Red Hat Enterprise Linux 7.
-
A user with sudo permissions
-
~ 25 GB of free space in your home directory
-
At least 8GB of RAM
To start, we install the packages we are going to need:
sudo yum install qemu-kvm libvirt-daemon-qemu libvirt-daemon-kvm libvirt virt-install libguestfs-tools-c kernel-tools dpdk dpdk-tools
Creating a VM
First, download the latest CentOS-Cloud-Base image from the following website:
user@host $ sudo wget -O /var/lib/libvirt/images/CentOS-7-x86_64-GenericCloud.qcow2 http://cloud.centos.org/centos/7/images/CentOS-7-x86_64-GenericCloud.qcow2
(Note the URL above might change, update it to the latest qcow2 image from https://wiki.centos.org/Download.)
This downloads a preinstalled version of CentOS 7, ready to run in an OpenStack environment. Since we’re not running OpenStack, we have to clean the image. To do that, first we will make a copy of the image so we can reuse it in the future:
user@host $ sudo qemu-img create -f qcow2 -b /var/lib/libvirt/images/CentOS-7-x86_64-GenericCloud.qcow2 /var/lib/libvirt/images//vhuser-test1.qcow2 20G
The libvirt commands to do this can be executed with an unprivileged user (recommended) if we export the following variable:
user@host $ export LIBVIRT_DEFAULT_URI="qemu:///system"
Now, the cleaning command (change the password to your own):
user@host $ sudo virt-sysprep --root-password password:changeme --uninstall cloud-init --selinux-relabel -a /var/lib/libvirt/images/vhuser-test1.qcow2 --network --install "dpdk,dpdk-tools,pciutils"
This command mounts the filesystem and applies some basic configuration automatically so that the image is ready to boot afresh.
We need a network to connect our VM as well. Libvirt handles networks in a similar way it manages VMs, you can define a network using an XML file and start it or stop it through the command line.
For this example, we will use a network called ‘default’ whose definition is shipped inside libvirt for convenience. The following commands define the ‘default’ network, start it and check that it’s running.
user@host $ virsh net-define /usr/share/libvirt/networks/default.xml Network default defined from /usr/share/libvirt/networks/default.xml user@host $ virsh net-start default Network default started user@host $virsh net-list Name State Autostart Persistent -------------------------------------------- default active no yes
Finally, we can use virt-install to create the VM. This command line utility creates the needed definitions for a set of well known operating systems. This will give us the base definitions that we can then customize:
user@host $ virt-install --import --name vhuser-test1 --ram=4096 --vcpus=3
--nographics --accelerate
--network network:default,model=virtio --mac 02:ca:fe:fa:ce:aa
--debug --wait 0 --console pty
--disk /var/lib/libvirt/images/vhuser-test1.qcow2,bus=virtio --os-variant centos7.0
The options used for this command specify the number of vCPUs, the amount of RAM of our VM as well as the disk path and the network we want the VM to be connected to.
Apart from defining the VM according to the options that we specified, the virt-install command should have also started the VM for us so we should be able to list it:
user@host $ virsh list Id Name State ------------------------------ 1 vhuser-test1 running
Voilà! Our VM is running. We need to make some changes to its definition soon. So we will shut it down now:
user@host $ virsh shutdown vhuser-test1
Preparing the host
DPDK helps with optimally allocating and managing memory buffers. On Linux this requires using hugepage support which must be enabled in the running kernel. Using pages of a size bigger than the usual 4K improves performance by using fewer pages and therefore fewer TLB (Translation Lookaside Buffers) lookups. These lookups are required to translate virtual to physical addresses. To allocate hugepages during boot we add the following to the kernel parameters in the bootloader configuration.
user@host $ sudo grubby --args="default_hugepagesz=1G hugepagesz=1G hugepages=6 iommu=pt intel_iommu=on" --update-kernel /boot/<your kernel image file>
Let’s understand what each of the parameters do:
default_hugepagesz=1G: make all created hugepages by default 1G big
hugepagesz=1G: for the hugepages created during startup set the size to 1G as well
hugepages=6: create 6 hugepages (of size 1G) from the start. These should be seen after booting in /proc/meminfo
Note that in addition to the hugepage settings we also added two IOMMU related kernel parameters, iommu=pt intel_iommu=on. This will initialize the Intel VT-d and the IOMMU Pass-Through mode that we will need for handling IO in the Linux userspace. As we changed kernel parameters, now is a good time to reboot the host.
After it comes up we can check that our changes to the kernel parameters were effective by running user@host $ cat /proc/cmdline.
Prepare the guest
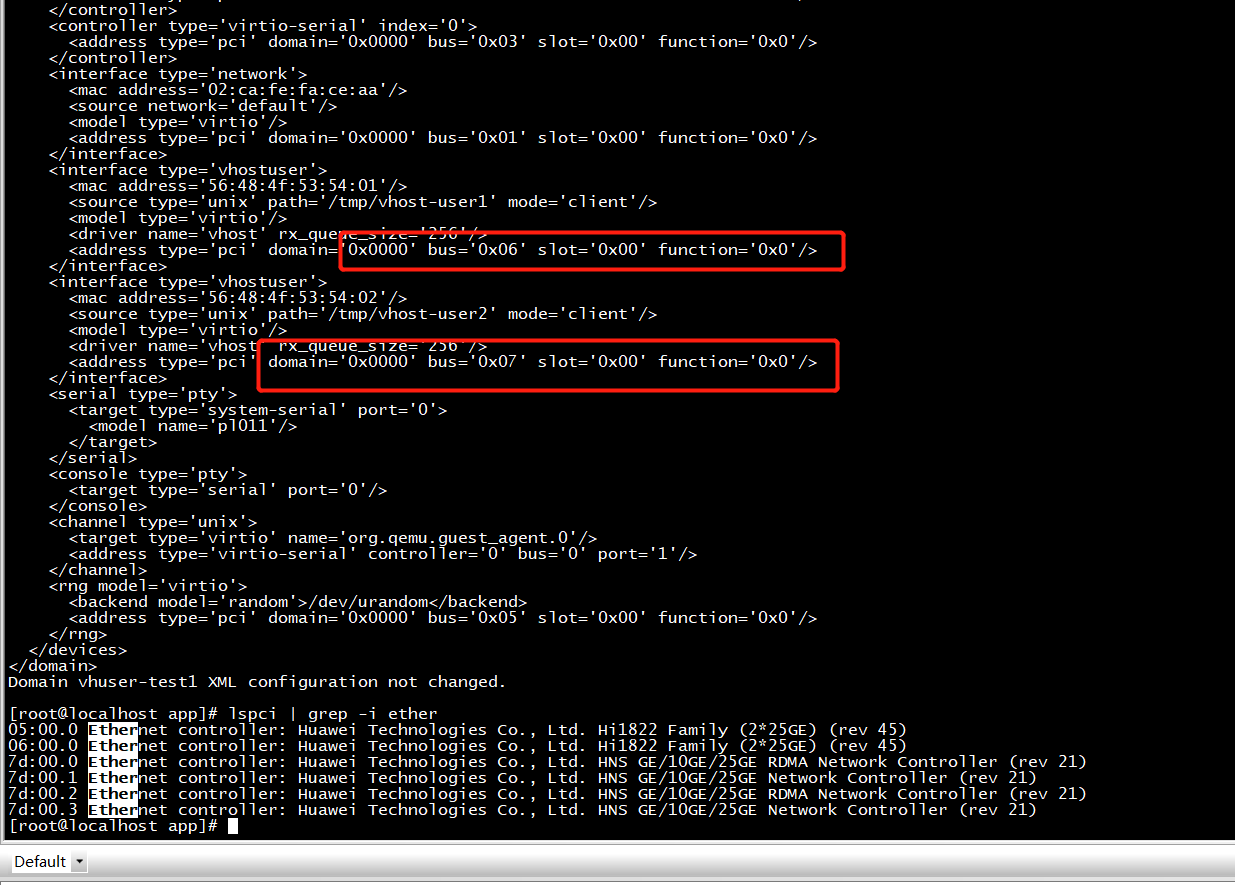
The virt-install command created and started a VM using libvirt. To connect our DPDK based vswitch testpmd to QEMU we need to add the definition of the vhost-user interfaces (backed by UNIX sockets) to the device section of the XML:
user@host $ virsh edit vhuser-test1
<device> section:<interface type='vhostuser'>
<mac address='56:48:4f:53:54:01'/>
<source type='unix' path='/tmp/vhost-user1' mode='client'/>
<model type='virtio'/>
<driver name='vhost' rx_queue_size='256' />
</interface>
<interface type='vhostuser'>
<mac address='56:48:4f:53:54:02'/>
<source type='unix' path='/tmp/vhost-user2' mode='client'/>
<model type='virtio'/>
<driver name='vhost' rx_queue_size='256' />
</interface>
Another difference in the guest config compared to one used for vhost-net is use of hugepages. For that we add the following to the guest definition:
<memoryBacking>
<hugepages>
<page size='1048576' unit='KiB' nodeset='0'/>
</hugepages>
<locked/>
</memoryBacking>
<numatune>
<memory mode='strict' nodeset='0'/>
</numatune>
And so memory can be accessed we need an additional setting in the guest configuration. This is an important setting, without it we won’t see any packets being transmitted:
<cpu mode='host-passthrough' check='none'>
<topology sockets='1' cores='3' threads='1'/>
<numa>
<cell id='0' cpus='0-2' memory='3145728' unit='KiB' memAccess='shared'/>
</numa>
</cpu>
Now we need to start our guest. Because we configured it to connect to the vhost-user UNIX sockets we need to be sure they are available when the guest it started. This is achieved by starting testpmd, which will open the sockets for us:
user@host $ sudo testpmd -l 0,2,3,4,5 --socket-mem=1024 -n 4
--vdev 'net_vhost0,iface=/tmp/vhost-user1'
--vdev 'net_vhost1,iface=/tmp/vhost-user2' --
--portmask=f -i --rxq=1 --txq=1
--nb-cores=4 --forward-mode=io
One last thing, because we connect to the vhost-user unix sockets, we need to make QEMU run as root for this experiment. For this set user = root in /etc/libvirt/qemu.conf. This is required for our special use case but not recommended in general. In fact readers should revert this setting after following this hands-on article by commenting out the user = root setting.
Now we can start the VM with user@host $ virsh start vhuser-test1.
Log in as root. The first thing we do in the guest is to bind the virtio devices to the vfio-pci driver. To be able to do this we need to load the required kernel modules first.
root@guest $ modprobe vfio enable_unsafe_noiommu_mode=1 root@guest $ cat /sys/module/vfio/parameters/enable_unsafe_noiommu_mode root@guest $ modprobe vfio-pci
Let’s find out the PCI addresses of our virtio-net devices first.
root@guest $ dpdk-devbind --status net … Network devices using kernel driver =================================== 0000:01:00.0 'Virtio network device 1041' if=enp1s0 drv=virtio-pci unused= *Active* 0000:0a:00.0 'Virtio network device 1041' if=enp1s1 drv=virtio-pci unused= 0000:0b:00.0 'Virtio network device 1041' if=enp1s2 drv=virtio-pci unused=
In the output of dpdk-devbind look for the virtio-devices in the section that are not marked active. We can use these for our experiment. Note: addresses may be different on the readers system. When we first boot the devices will be automatically bound to the virtio-pci driver. Because we want to use them not with the kernel driver but with the vfio-pci kernel module, we first unbind them from virtio-pci and then bind them to the vfio-pci driver.
root@guests $ dpdk-devbind.py -b vfio-pci 0000:0a:00.0 0000:0b:00.0
Now the guest is prepared to run our DPDK based application. To make this binding permanent we could also use the driverctl utility:
root@guest $ driverctl -v set-override 0000:00:10.0 vfio-pci
Do the same for the second virtio-device with address 0000:00:11.0. Then list all overrides to check it worked:
user@guest $ sudo driverctl list-overrides 0000:00:10.0 vfio-pci 0000:00:11.0 vfio-pci
Generating traffic
We installed and configured everything to finally run networking traffic over our interfaces. Let’s start: In the host we first need to start the testpmd instance which acts as a virtual switch. We will just make it forward all packets it received on interface net_vhost0 to net_vhost1. It needs to be started before we start the VM, because it will try to connect to the unix sockets belonging to the vhost-user devices during initialization and they are created by QEMU.
root@host $ testpmd -l 0,2,3,4,5 --socket-mem=1024 -n 4
--vdev 'net_vhost0,iface=/tmp/vhost-user1'
--vdev 'net_vhost1,iface=/tmp/vhost-user2' --
--portmask=f -i --rxq=1 --txq=1
--nb-cores=4 --forward-mode=io
Now we can launch the VM we prepared previously:
user@host $ virsh start vhuser-test1
Notice how we can see output in the testpmd window which shows the vhost-user messages it received
Once the guest has booted we can start the testpmd instance. This one will initialize the ports and the virtio-net driver that DPDK implements. Among other things this is where the virtio feature negotiation takes place and the set of common features is agreed upon.
Before we start testpmd we make sure that the vfio kernel module is loaded and bind the virtio-net devices to the vfio-pci driver:
root@guest $ dpdk-devbind.py -b vfio-pci 0000:00:10.0 0000:00:11.0
Start testpmd:
root@guest $ testpmd -l 0,1,2 --socket-mem 1024 -n 4
--proc-type auto --file-prefix pg --
--portmask=3 --forward-mode=macswap --port-topology=chained
--disable-rss -i --rxq=1 --txq=1
--rxd=256 --txd=256 --nb-cores=2 --auto-start
Now we can check how many packets our testpmd instances are processing. On the testpmd prompt we enter the command ‘show port stats all’ and see the number of packets forwarded in each direction (RX/TX).
An example:
testpmd> show port stats all ######################## NIC statistics for port 0 ######################## RX-packets: 75525952 RX-missed: 0 RX-bytes: 4833660928 RX-errors: 0 RX-nombuf: 0 TX-packets: 75525984 TX-errors: 0 TX-bytes: 4833662976 Throughput (since last show) Rx-pps: 4684120 Tx-pps: 4684120 ######################################################################### ######################## NIC statistics for port 1 ######################## RX-packets: 75525984 RX-missed: 0 RX-bytes: 4833662976 RX-errors: 0 RX-nombuf: 0 TX-packets: 75526016 TX-errors: 0 TX-bytes: 4833665024 Throughput (since last show) Rx-pps: 4681229 Tx-pps: 4681229 #########################################################################
There are different forwarding modes in testpmd. In this example we used --forward-mode=macswap, which swaps the destination and source MAC address. Other forwarding modes like ‘io’ don’t touch packets at all and will give much higher, but also even more unrealistic numbers. Another forwarding mode is ‘noisy’. It can be fine-tuned to simulate packet buffering and memory lookups.
Extra: Optimizing the configuration for maximum throughput and low latency
So far we mostly stayed with the default settings. This helped to keep the tutorial simple and easy to follow. But for those readers interested in tuning all components for the best performance we will explain what is needed to achieve this.
Optimizing host settings
We start with optimizing our host system.
There are a few settings we need to do in the host system to achieve optimal performance. Note that you don’t necessarily have to do all these manual steps. With tuned you get a set of available tuned profiles that you can choose from. Applying the cpu-partitioning profile of tuned will take care of all the steps we will execute manually here.
Before we start explaining the tunings in detail, this is how you use the tuned cpu-partition profile and don’t have to bother with all the details:
user@host $ sudo dnf install tuned-profiles-cpu-partitioning
Then edit /etc/tuned/cpu-partitioning-variables.conf and set isol_cpus and no_balance_cores both to 2-7.
Now we can apply the tuned profile with the tuned-adm command:
user@host $ sudo tuned-adm profile cpu-partitioning
Rebooting to apply the changes is necessary because we add kernel parameters.
For those readers who want to know more details of what the cpu-partitioning profile does, let’s do these steps manually. If you’re not interested in this you can just skip to the next section.
Let’s assume we have eight cores in the system and we want to isolate six of them on the same NUMA node. We use two cores to run the guest virtual CPUs and the remaining four to run the data path of the application.
The most basic change is done even outside of Linux in the BIOS settings of the system. There we have to disable turbo-boost and hyper-threads. If the BIOS is for some reason not accessible, disable hyperthreads with this command:
cat /sys/devices/system/cpu/cpu*[0-9]/topology/thread_siblings_list
| sort | uniq
| awk -F, '{system("echo 0 > /sys/devices/system/cpu/cpu"$2"/online")}'
After that we attach the following to the kernel command line:
intel_pstate=disable isolcpus=2-7 rcu_nocbs=2-7 nohz_full=2-7
What these parameters mean is:
intel_pstate=disable: avoid switching power states
Do this by running:
user@host $ grubby --args "intel_pstate=disable mce=ignore_ce isolcpus=2-7 rcu_nocbs=2-7 nohz_full=2-7" --update-kernel /boot/<your kernel image file>
Non-maskable interrupts can reduce performance because they steal valuable cycles where the core could handle packets instead, so we disable them with:
user@host $ echo 0 > /proc/sys/kernel/nmi_watchdog
To a similar effect we exclude the cores we want to isolate from the writeback cpu mask:
user@host $ echo ffffff03 > /sys/bus/workqueue/devices/writeback/cpumask
Optimizing guest settings
Similar to what we did in the host we also change the kernel parameters for the guest. Again by using grubby we add the following parameters to the configuration:
default_hugepagesz=1G hugepagesz=1G hugepages=1 intel_iommu=on iommu=pt isolcpus=1,2 rcu_nocbs=1,2 nohz_full=1,2
The meaning of the first three parameters are known from the host configuration. The others are:
intel_iommu=on: Make use of the IOMMU.
iommu=pt: Operate IOMMU in pass-through mode. More about what this means later.
isolcpus=1,2: Ask kernel to isolate these cores.
rcu_nocbs=1,2: Don’t do RCU callbacks on the cpu, offload it to other threads to avoid RCU callbacks as softirqs.
nohz_full=1,2: Avoid scheduling clock ticks.
And because we want the same for guest cores handling the packets that we want for the cores in the host we do the same steps and disable NMIs, exclude the cores from block device writeback flusher threads and from IRQs, we do this:
user@guest $ echo 0 > /proc/sys/kernel/nmi_watchdog user@guest $ echo 1 > /sys/bus/workqueue/devices/writeback/cpumask user@guest $ clear_mask=0x6 #Isolate CPU1 and CPU2 from IRQs for i in /proc/irq/*/smp_affinity do echo "obase=16;$(( 0x$(cat $i) & ~$clear_mask ))" | bc > $i done
Pinning virtual CPUs to physical cores in the host will make sure the vcpus are not scheduled to different cores.
<cputune>
<vcpupin vcpu='0' cpuset='1'/>
<vcpupin vcpu='1' cpuset='6'/>
<vcpupin vcpu='2' cpuset='7'/>
<emulatorpin cpuset='0'/>
</cputune>
Analyzing the performance
After going through all the performance tuning steps, let’s run our testpmd instances again to see how the number of packets per second changed.
testpmd> show port stats all ######################## NIC statistics for port 0 ######################## RX-packets: 24828768 RX-missed: 0 RX-bytes: 1589041152 RX-errors: 0 RX-nombuf: 0 TX-packets: 24828800 TX-errors: 0 TX-bytes: 1589043200 Throughput (since last show) Rx-pps: 5207755 Tx-pps: 5207755 ######################################################################## ######################## NIC statistics for port 1 ######################## RX-packets: 24852096 RX-missed: 0 RX-bytes: 1590534144 RX-errors: 0 RX-nombuf: 0 TX-packets: 24852128 TX-errors: 0 TX-bytes: 1590536192 Throughput (since last show) Rx-pps: 5207927 Tx-pps: 5207927 ########################################################################
Compared to the numbers of the not tuned setup the numbers of packet per second increased roughly by 12%. This is a very simple setup and we have no other workloads running on host and guest. In a more complex scenario the performance improvement might be even more significant.
After building a simple setup before, in this section we concentrated on tuning the performance of the individual components. The key here is to deconfigure and disable everything that distracts cores (physical or virtual) from doing what they are supposed to do: handling packets.
We did this manually in what seems like a complicated set of commands so we can learn what is behind it all. But the truth is: all this can be achieved by installing and using tuned and the tuned-profiles-cpu-partition package and a simple one-line configuration file change. Even more, the single biggest impact is achieved by pinning the vCPUs to host cores.
Ansible scripts available
Setting this environment up and running is the first and fundamental step in order to understand, debug and test this architecture. In order to make it as quick and easy as possible, Red Hat’s virtio-net team has developed a set of Ansible scripts for everyone to use.
Just follow the instructions in the README and Ansible should take care of the rest.
Conclusion
We have set up and configured a host system to run DPDK based application and created a virtual machine that is connected to it via vhost-user interfaces. Inside the VM we ran testpmd, also built on DPDK, and used it to generate, send and receive packets in a loop between the testpmd vswitch instance in the host and the instance in the VM. The setup we looked at is a very simple one. A next step for the interested reader could be deploying and using OVS-DPDK, which is OpenVSwitch built against DPDK. It’s a far more advanced virtual switch used in production scenarios.
This is the last post on the "Virtio-networking and DPDK" topic, which started with "how vhost-user came into being," and was followed by "journey to the vhost-users realm."
Prior posts / Resources
- Introducing virtio-networking: Combining virtualization and networking for modern IT
- Introduction to virtio-networking and vhost-net
- Deep dive into Virtio-networking and vhost-net
- Hands on vhost-net: Do. Or do not. There is no try
- How vhost-user came into being: Virtio-networking and DPDK
- A journey to the vhost-users realm
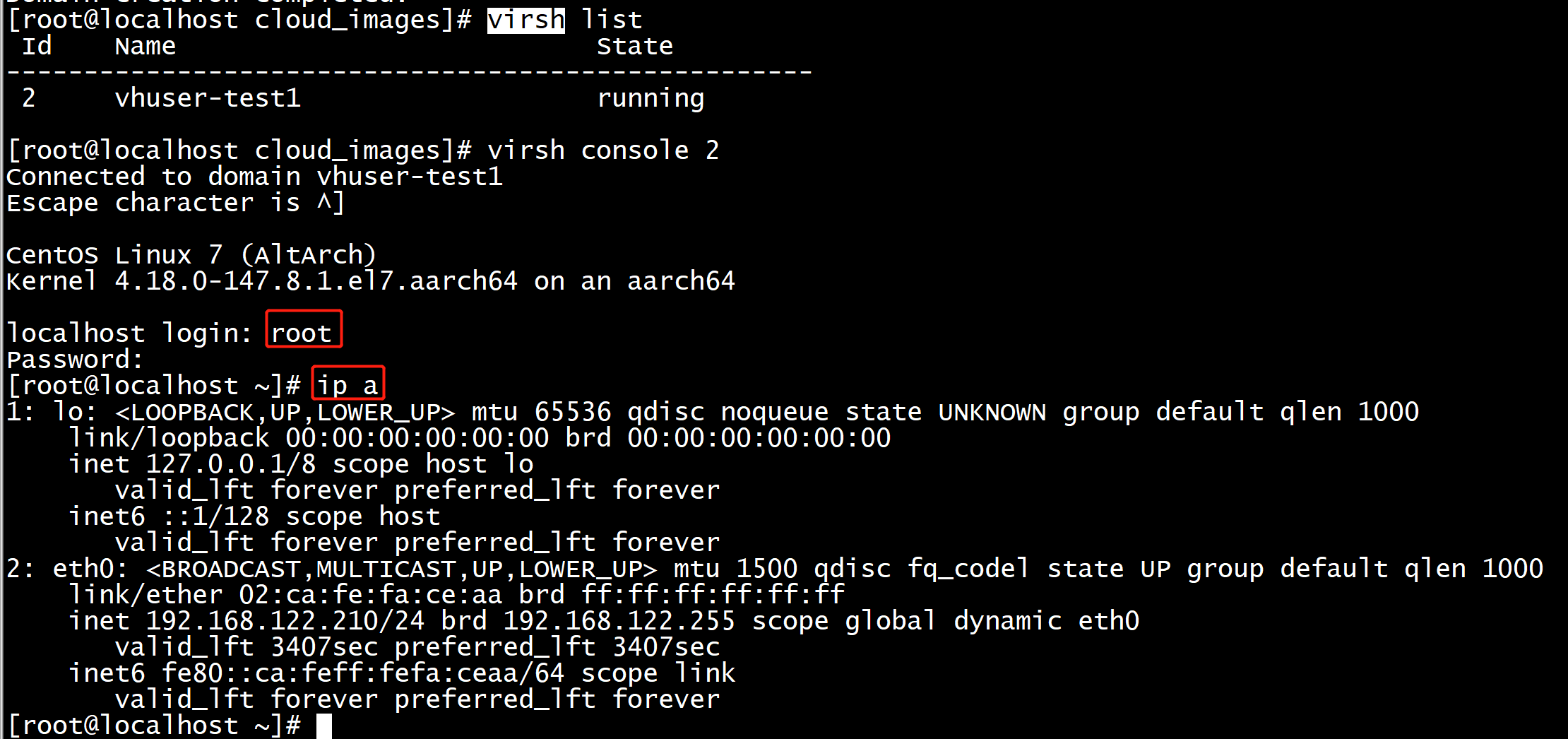
step
yum install qemu-kvm libvirt-daemon-qemu libvirt-daemon-kvm libvirt virt-install libguestfs-tools-c kernel-tools
dpdk手动编译
step
export LIBVIRT_DEFAULT_URI="qemu:///system"
step
[root@localhost cloud_images]# virt-sysprep --root-password password:changeme --uninstall cloud-init --selinux-relabel -a vhuser-test1.qcow2 [ 0.0] Examining the guest ... libvirt: XML-RPC error : Failed to connect socket to '/var/run/libvirt/libvirt-sock': No such file or directory virt-sysprep: error: libguestfs error: could not connect to libvirt (URI = qemu:///system): Failed to connect socket to '/var/run/libvirt/libvirt-sock': No such file or directory [code=38 int1=2] If reporting bugs, run virt-sysprep with debugging enabled and include the complete output: virt-sysprep -v -x [...]
[root@localhost cloud_images]# systemctl status libvirtd ● libvirtd.service - Virtualization daemon Loaded: loaded (/usr/lib/systemd/system/libvirtd.service; enabled; vendor preset: enabled) Active: inactive (dead) Docs: man:libvirtd(8) https://libvirt.org [root@localhost cloud_images]# systemctl restart libvirtd [root@localhost cloud_images]# systemctl status libvirtd ● libvirtd.service - Virtualization daemon Loaded: loaded (/usr/lib/systemd/system/libvirtd.service; enabled; vendor preset: enabled) Active: active (running) since Fri 2020-10-30 04:30:04 EDT; 1s ago Docs: man:libvirtd(8) https://libvirt.org Main PID: 28637 (libvirtd) Tasks: 22 (limit: 32768) CGroup: /system.slice/libvirtd.service ├─28637 /usr/sbin/libvirtd ├─28750 /usr/sbin/dnsmasq --conf-file=/var/lib/libvirt/dnsmasq/default.conf --leasefile-ro --dhcp-sc... └─28751 /usr/sbin/dnsmasq --conf-file=/var/lib/libvirt/dnsmasq/default.conf --leasefile-ro --dhcp-sc... Oct 30 04:30:05 localhost.localdomain dnsmasq[28743]: listening on virbr0(#8): 192.168.122.1 Oct 30 04:30:05 localhost.localdomain dnsmasq[28750]: started, version 2.76 cachesize 150 Oct 30 04:30:05 localhost.localdomain dnsmasq[28750]: compile time options: IPv6 GNU-getopt DBus no-i18n IDN...ify Oct 30 04:30:05 localhost.localdomain dnsmasq-dhcp[28750]: DHCP, IP range 192.168.122.2 -- 192.168.122.254, ... 1h Oct 30 04:30:05 localhost.localdomain dnsmasq-dhcp[28750]: DHCP, sockets bound exclusively to interface virbr0 Oct 30 04:30:05 localhost.localdomain dnsmasq[28750]: reading /etc/resolv.conf Oct 30 04:30:05 localhost.localdomain dnsmasq[28750]: using nameserver 8.8.8.8#53 Oct 30 04:30:05 localhost.localdomain dnsmasq[28750]: read /etc/hosts - 2 addresses Oct 30 04:30:05 localhost.localdomain dnsmasq[28750]: read /var/lib/libvirt/dnsmasq/default.addnhosts - 0 ad...ses Oct 30 04:30:05 localhost.localdomain dnsmasq-dhcp[28750]: read /var/lib/libvirt/dnsmasq/default.hostsfile Hint: Some lines were ellipsized, use -l to show in full. [root@localhost cloud_images]#

step
[root@localhost cloud_images]# virsh net-define /usr/share/libvirt/networks/default.xml error: Failed to define network from /usr/share/libvirt/networks/default.xml error: operation failed: network 'default' already exists with uuid 23320eef-5c42-4f82-bd53-353852d8a7be [root@localhost cloud_images]# virsh net-start default error: Failed to start network default error: Requested operation is not valid: network is already active [root@localhost cloud_images]# virsh net-list --all Name State Autostart Persistent ---------------------------------------------------------- default active yes yes [root@localhost cloud_images]#
step
user@host $ virt-install --import --name vhuser-test1 --ram=4096 --vcpus=3 --nographics --accelerate --network network:default,model=virtio --mac 02:ca:fe:fa:ce:aa --debug --wait 0 --console pty --disk /var/lib/libvirt/images/vhuser-test1.qcow2,bus=virtio --os-variant centos7.0
<seclabel type='dynamic' model='dac' relabel='yes'> <label>+107:+107</label> <imagelabel>+107:+107</imagelabel> </seclabel> </domain> [Fri, 30 Oct 2020 04:34:32 virt-install 29126] DEBUG (virt-install:744) Domain state after install: 1 Domain creation completed. [root@localhost cloud_images]# virsh list Id Name State ---------------------------------------------------- 2 vhuser-test1 running [root@localhost cloud_images]#
step root/changeme
注:按 ctrl+] 组合键退出virsh console
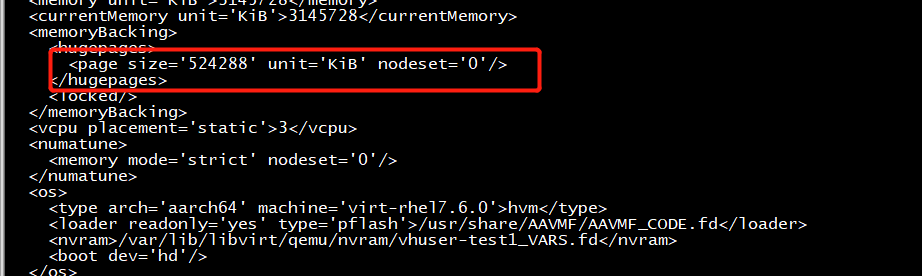
<memoryBacking>
<hugepages>
<page size='1048576' unit='KiB' nodeset='0'/>
</hugepages>
<locked/>
</memoryBacking>
<vcpu placement='static'>3</vcpu>
<numatune>
<memory mode='strict' nodeset='0'/>
</numatune>
<os>
<type arch='aarch64' machine='virt-rhel7.6.0'>hvm</type>
<loader readonly='yes' type='pflash'>/usr/share/AAVMF/AAVMF_CODE.fd</loader>
<nvram>/var/lib/libvirt/qemu/nvram/vhuser-test1_VARS.fd</nvram>
<boot dev='hd'/>
</os>
<features>
<acpi/>
<gic version='3'/>
</features>
<cpu mode='host-passthrough' check='none'>
<topology sockets='1' cores='3' threads='1'/>
<numa>
<cell id='0' cpus='0-2' memory='3145728' unit='KiB' memAccess='shared'/>
</numa>
</cpu>
step
[root@localhost dpdk-19.11]# ./arm64-armv8a-linuxapp-gcc/app/testpmd -l 0,2,3,4,5 --socket-mem=1024 -n 4 > --vdev 'net_vhost0,iface=/tmp/vhost-user1' > --vdev 'net_vhost1,iface=/tmp/vhost-user2' -- > --portmask=f -i --rxq=1 --txq=1 > --nb-cores=4 --forward-mode=io
root@localhost app]# virsh start vhuser-test1 error: Failed to start domain vhuser-test1 error: internal error: Unable to find any usable hugetlbfs mount for 1048576 KiB
[root@localhost app]# cat /proc/meminfo | grep -i huge AnonHugePages: 0 kB ShmemHugePages: 0 kB HugePages_Total: 256 HugePages_Free: 254 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 524288 kB [root@localhost app]#
[root@localhost app]# virsh start vhuser-test1 error: Failed to start domain vhuser-test1 error: internal error: qemu unexpectedly closed the monitor: 2020-11-03T09:59:54.537382Z qemu-kvm: -chardev socket,id=charnet1,path=/tmp/vhost-user1: Failed to connect socket /tmp/vhost-user1: Permission denied [root@localhost app]# ls /tmp/vhost-user1 /tmp/vhost-user1 [root@localhost app]#
https://docs.openvswitch.org/en/latest/topics/dpdk/vhost-user/#dpdk-vhost-user-xml
Adding vhost-user ports to the guest (libvirt)¶
To begin, you must change the user and group that qemu runs under, and restart libvirtd.
-
In
/etc/libvirt/qemu.confadd/edit the following lines:user = "root" group = "root" -
Finally, restart the libvirtd process, For example, on Fedora:
$ systemctl restart libvirtd.service
[root@localhost app]# sudo -u qemu socat - UNIX-CONNECT:/tmp/vhost-user2 2020/11/03 06:31:36 socat[47574] E connect(5, AF=1 "/tmp/vhost-user2", 18): Permission denied [root@localhost app]# chown root:kvm /tmp/vhost-user2 [root@localhost app]# chmod g+w /tmp/vhost-user2 [root@localhost app]# sudo -u qemu socat - UNIX-CONNECT:/tmp/vhost-user2



cannot acquire state change lock
[root@localhost ~]# ps -elf | grep qemu 6 S root 48626 1 0 80 0 - 6068 poll_s 07:13 ? 00:00:00 /usr/libexec/qemu-kvm -name guest=vhuser-test1,debug-threads=on -S -object secret,id=masterKey0,format=raw,file=/var/lib/libvirt/qemu/domain-1-vhuser-test1/master-key.aes -machine virt-rhel7.6.0,accel=kvm,usb=off,dump-guest-core=off,gic-version=3 -cpu host -drive file=/usr/share/AAVMF/AAVMF_CODE.fd,if=pflash,format=raw,unit=0,readonly=on -drive file=/var/lib/libvirt/qemu/nvram/vhuser-test1_VARS.fd,if=pflash,format=raw,unit=1 -m 3072 -realtime mlock=on -smp 3,sockets=1,cores=3,threads=1 -object memory-backend-file,id=ram-node0,prealloc=yes,mem-path=/dev/hugepages/libvirt/qemu/1-vhuser-test1,share=yes,size=3221225472,host-nodes=0,policy=bind -numa node,nodeid=0,cpus=0-2,memdev=ram-node0 -uuid a412374f-2195-48b2-ac01-dcbddfb23c1d -display none -no-user-config -nodefaults -chardev socket,id=charmonitor,fd=25,server,nowait -mon chardev=charmonitor,id=monitor,mode=control -rtc base=utc -no-shutdown -boot strict=on -device pcie-root-port,port=0x8,chassis=1,id=pci.1,bus=pcie.0,multifunction=on,addr=0x1 -device pcie-root-port,port=0x9,chassis=2,id=pci.2,bus=pcie.0,addr=0x1.0x1 -device pcie-root-port,port=0xa,chassis=3,id=pci.3,bus=pcie.0,addr=0x1.0x2 -device pcie-root-port,port=0xb,chassis=4,id=pci.4,bus=pcie.0,addr=0x1.0x3 -device pcie-root-port,port=0xc,chassis=5,id=pci.5,bus=pcie.0,addr=0x1.0x4 -device pcie-root-port,port=0xd,chassis=6,id=pci.6,bus=pcie.0,addr=0x1.0x5 -device pcie-root-port,port=0xe,chassis=7,id=pci.7,bus=pcie.0,addr=0x1.0x6 -device qemu-xhci,p2=8,p3=8,id=usb,bus=pci.2,addr=0x0 -device virtio-serial-pci,id=virtio-serial0,bus=pci.3,addr=0x0 -drive file=/data1/cloud_images/vhuser-test1.qcow2,format=qcow2,if=none,id=drive-virtio-disk0 -device virtio-blk-pci,scsi=off,bus=pci.4,addr=0x0,drive=drive-virtio-disk0,id=virtio-disk0,bootindex=1 -netdev tap,fd=27,id=hostnet0,vhost=on,vhostfd=28 -device virtio-net-pci,netdev=hostnet0,id=net0,mac=02:ca:fe:fa:ce:aa,bus=pci.1,addr=0x0 -chardev socket,id=charnet1,path=/tmp/vhost-user2,server -netdev vhost-user,chardev=charnet1,id=hostnet1 -device virtio-net-pci,rx_queue_size=256,netdev=hostnet1,id=net1,mac=02:ca:fe:fa:ce:aa,bus=pci.6,addr=0x0 -chardev pty,id=charserial0 -serial chardev:charserial0 -chardev socket,id=charchannel0,fd=29,server,nowait -device virtserialport,bus=virtio-serial0.0,nr=1,chardev=charchannel0,id=channel0,name=org.qemu.guest_agent.0 -object rng-random,id=objrng0,filename=/dev/urandom -device virtio-rng-pci,rng=objrng0,id=rng0,bus=pci.5,addr=0x0 -sandbox on,obsolete=deny,elevateprivileges=deny,spawn=deny,resourcecontrol=deny -msg timestamp=on 0 S root 48663 46710 0 80 0 - 1729 pipe_w 07:13 pts/2 00:00:00 grep --color=auto qemu [root@localhost ~]# kill -9 48626
killall -9 libvirtd rm /var/run/libvirtd.pid ##### Remove the libvirtd pid file. /etc/init.d/libvirtd restart #### Restart libvirtd.