地址 https://leetcode-cn.com/problems/find-all-anagrams-in-a-string/
给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
异位词 指由相同字母重排列形成的字符串(包括相同的字符串)。
示例 1:
输入: s = "cbaebabacd", p = "abc"
输出: [0,6]
解释:
起始索引等于 0 的子串是 "cba", 它是 "abc" 的异位词。
起始索引等于 6 的子串是 "bac", 它是 "abc" 的异位词。
示例 2:
输入: s = "abab", p = "ab"
输出: [0,1,2]
解释:
起始索引等于 0 的子串是 "ab", 它是 "ab" 的异位词。
起始索引等于 1 的子串是 "ba", 它是 "ab" 的异位词。
起始索引等于 2 的子串是 "ab", 它是 "ab" 的异位词。
提示:
1 <= s.length, p.length <= 3 * 104
s 和 p 仅包含小写字母
解法
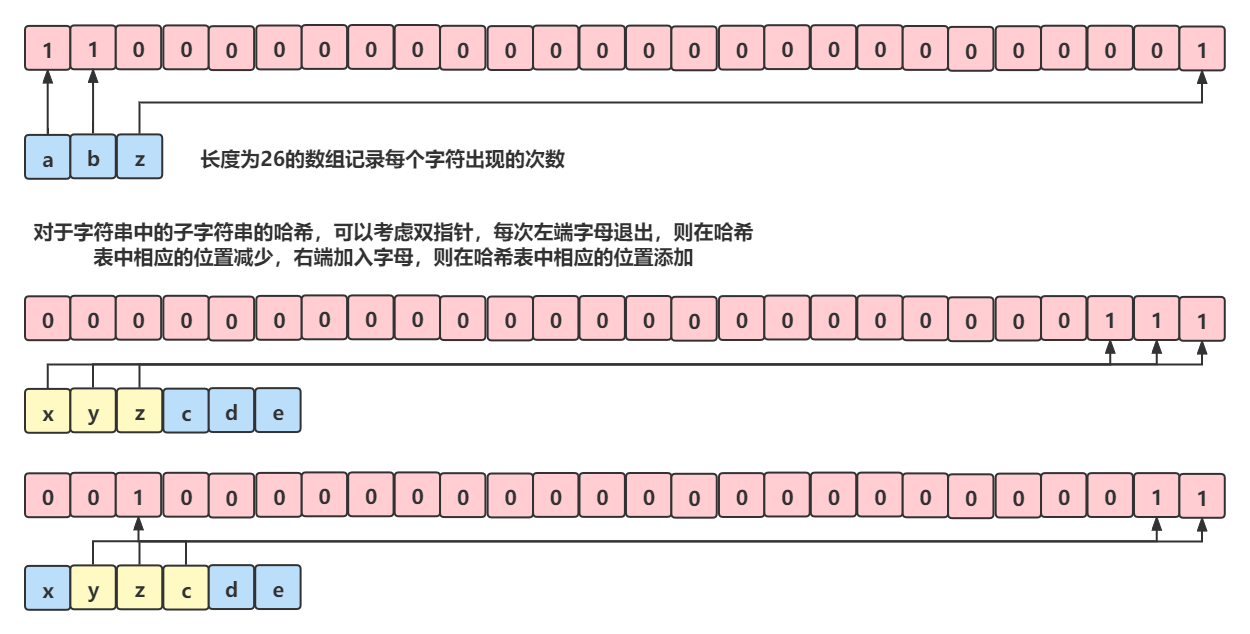
快速查找比对字符串的情况,可以考虑哈希。
其中一种方法就是长度为26的数组记录每个字符出现的次数
class Solution {
public:
int hashP[30];
int hashS[30];
vector<int> ans;
bool issame(){
for(int i =0;i<26;i++){
if(hashP[i]!=hashS[i]) return false;
}
return true;
}
vector<int> findAnagrams(string s, string p) {
if(s.size()<p.size()) return ans;
int len = p.size();
memset(hashP,0,sizeof hashP);
memset(hashS,0,sizeof hashS);
for(int i = 0;i <len;i++){
int idx = p[i]-'a';
hashP[idx]++;
}
//制作前len个字母的哈希
for(int i =0;i < len;i++){
int idx = s[i]-'a';
hashS[idx]++;
}
int l =0; int r =len-1;
//然后依次偏移一位 比较哈希值
while(r < s.size()){
if(issame()==true){
ans.push_back(l);
}
//最左端字母从哈希表中删除, 且退出双指针范围
hashS[s[l]-'a']--;l++;
//最右端添加字母 且添加进哈希表
r++;
if(r >=s.size()){break;}
hashS[s[r]-'a']++;
}
return ans;
}
};

