作业①
(1)要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据。
code:
数据库:

item:
import scrapy
class BookItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
author=scrapy.Field()
date=scrapy.Field()
publisher=scrapy.Field()
detail=scrapy.Field()
price=scrapy.Field()
pipeline:
import pymysql
class BookPipeline(object):
def open_spider(self,spider):
print("opened")
try:
self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="1394613257",
db="MyDB",charset="utf8")
self.cursor=self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from books")
self.opened=True
self.count=0
except Exception as err:
print(err)
self.opened=False
def close_spider(self,spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened=False
print("closed")
print("总共爬取",self.count,"本书籍")
def process_item(self, item, spider):
try:
print(item["title"])
print(item["author"])
print(item["publisher"])
print(item["date"])
print(item["price"])
print(item["detail"])
print()
if self.opened:
self.cursor.execute("insert into books(bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail)values(%s,%s,%s,%s,%s,%s)",(item["title"],item["author"],item["publisher"],item["date"],item["price"],item["detail"]))
self.count+=1
except Exception as err:
print(err)
return item
books:
import scrapy
from demo.items import BookItem
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
class MySpider(scrapy.Spider):
name = 'books'
#allowed_domains = ['www.dangdang.com']
key='python'
source_url = ['http://search.dangdang.com/']
def start_requests(self):
url=MySpider.source_url[0]+"?key="+MySpider.key
yield scrapy.Request(url=url,callback=self.parse)
def parse(self,response):
try:
dammit = UnicodeDammit(response.body,["utf-8","gbk"])
data = dammit.unicode_markup
selector=scrapy.Selector(text=data)
lis=selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]")
for li in lis:
title=li.xpath("./a[position()=1]/@title").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
price=li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
date=li.xpath("./p[@class='search_book_author']/span[position()= last()-1]/text()").extract_first()
publisher=li.xpath("./p[@class='search_book_author']/span[position()=3]/a/@title").extract_first()
detail=li.xpath("./p[@class='detail']/text()").extract_first()
item=BookItem()
item["title"]=title.strip() if title else""
item["author"]=author.strip() if author else""
item["date"]=date.strip()[1:] if date else""
item["publisher"]=publisher.strip() if publisher else""
item["price"]=price.strip() if price else""
item["detail"]=detail.strip() if detail else""
yield item
link = selector.xpath(
"//div[@class='paging']/ul[@name='Fy']/li[@class='next'] / a / @ href").extract_first()
if link:
url=response.urljoin(link)
yield scrapy.Request(url=url,callback=self.parse)
except Exception as err:
print(err)
结果:

(2)实验心得:
一言难尽,一开始mysql连接不上,好不容易解决了,参考书上代码运行,得到了“爬取0书本”的结果,后面查了下,应该是url那边的问题,然后又调了下url,最后跑出这么一个结果,但是mysql那边又显示不出来……按照网上给的方式试了下,还是失败了……不知道什么原因。
作业②
(1)要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
code:
#pipeline
import pymysql
class GetstockPipeline(object):
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host='localhost', port=3306, user="root", passwd="1394613257",
db="MyStock", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from stock")
self.opened = True
self.count = 0
self.num = 1
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "股票")
def process_item(self, item, spider):
print(item['name'])
print(item['code'])
print(item['date'])
print(item['nprice'])
print(item['high'])
print(item['low'])
print(item['ed'])
print(item['op'])
print(item['hangye'])
print()
if self.opened:
n = str(self.num)
self.cursor.execute("insert into stock(bname,bcode,bdate,bnprice,bhigh,blow,bed,bop,bhangye)values(%s,%s,%s,%s,%s,%s,%s,%s,%s)",(item['name'],item['code'],str(item['date']),str(item['nprice']),item['high'],item['low'],item['ed'],item['op'],item['hangye']))
self.count += 1
return item
#stock
import scrapy
from ..items import GetstockItem
import json
class StockSpider(scrapy.Spider):
name = 'Stock'
start_urls = ['https://30.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124004229850317009731_1585637567592&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:5&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f26,f22,f33,f11,f62,f128,f136,f115,f152&_=1585637567593']
# start_requests(self):
# url = StockSpider.start_url
# yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
jsons = response.text[43:][:-2] # 将前后用不着的字符排除
text_json = json.loads(jsons)
for data in text_json['data']['diff']:
item = GetstockItem()
item["code"] = data['f12']
item["name"] = data['f14']
item["nprice"] = data['f2']
item["op"] = data['f3']
item["ed"] = data['f4']
item["high"] = data['f15']
item["low"] = data['f16']
item["date"] = data['f6']
item["hangye"] = data['f7']
yield item
item:
import scrapy
class GetstockItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
code = scrapy.Field()
nprice = scrapy.Field()
op = scrapy.Field()
ed = scrapy.Field()
high = scrapy.Field()
low = scrapy.Field()
date = scrapy.Field()
hangye = scrapy.Field()
run.py
from scrapy import cmdline
cmdline.execute("scrapy crawl Stock -s LOG_ENABLED=False".split())
结果:
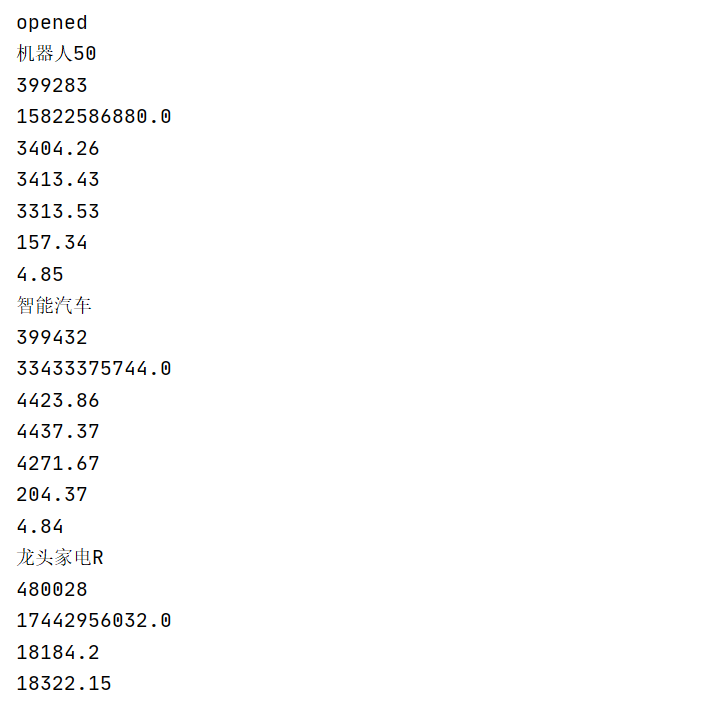
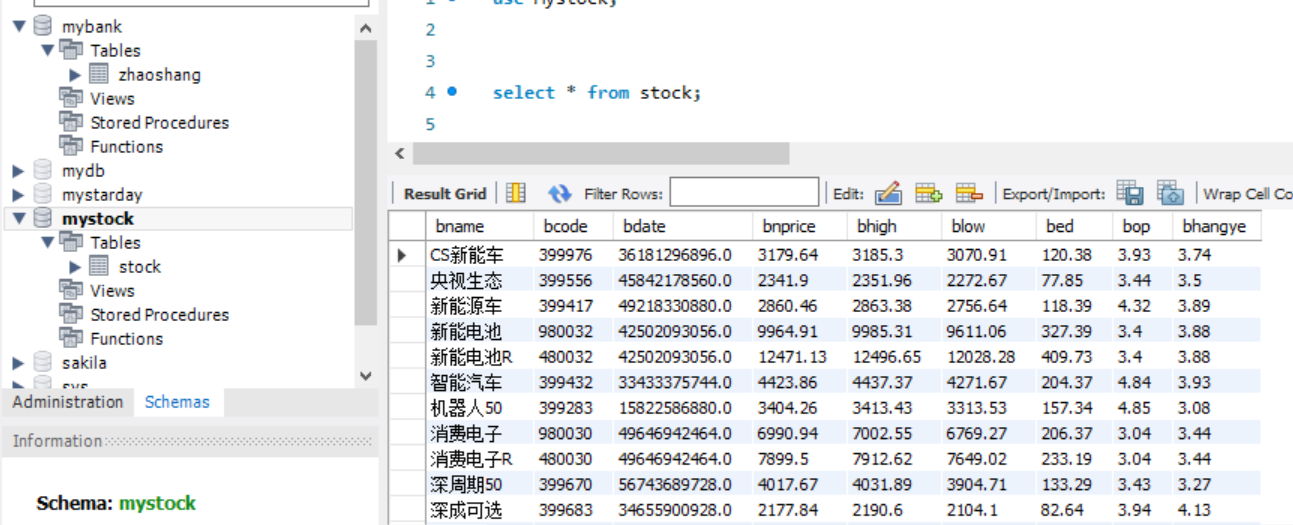
(2)心得体会:
进一步加深理解了对scrapy的理解与运用,在做题中不断地加深记忆。以及终于成功连接上MySQL了!
作业③
(1)要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据
代码:
pipeline:
import pymysql
class BanksPipeline:
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",
passwd="1394613257", db="Mybank", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from zhaoshang")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "条")
def process_item(self, item, spider):
try:
print(item["Currency"])
print(item["Tsp"])
print(item["Csp"])
print(item["Tbp"])
print(item["Cbp"])
print(item["Time"])
print()
if self.opened:
self.cursor.execute("insert into zhaoshang(bcurrency,btsp,bcsp,btbp,bcbp,btime) values (%s,%s,%s,%s,%s,%s)",(item["Currency"], item["Tsp"], item["Csp"], item["Tbp"], item["Cbp"], item["Time"]))
self.count += 1
except Exception as err:
print(err)
return item
bank:
import scrapy
from banks.items import BanksItem
from bs4 import UnicodeDammit
class BankSpider(scrapy.Spider):
name = 'bank'
#allowed_domains = ['fx.cmbchina.com']
start_urls = ["http://fx.cmbchina.com/hq/"]
def parse(self,response):
dammit = UnicodeDammit(response.body,["utf-8","gbk"])
data = dammit.unicode_markup
selector=scrapy.Selector(text=data)
lis=selector.xpath("//div[@id='realRateInfo']/table/tr")
for li in lis[1:]:
item = BanksItem()
Currency=li.xpath("./td[position()=1][@class='fontbold']/text()").extract_first()
Tsp = li.xpath("./td[position()=4][@class='numberright']/text()").extract_first()
Csp = li.xpath("./td[position()=5][@class='numberright']/text()").extract_first()
Tbp=li.xpath("./td[position()=6][@class='numberright']/text()").extract_first()
Cbp=li.xpath("./td[position()=7][@class='numberright']/text()").extract_first()
#Time=li.xpath("./td[position()=8][@class='numberright']/text()").extract_first()本来是这样的,后面发现这样跑不出来,问了大佬,改成下面的。
Time=li.xpath("./td[position()=8][@align='center']/text()").extract_first()
item["Currency"]=str(Currency.strip())
item["Tsp"]=str(Tsp.strip())
item["Csp"]=str(Csp.strip())
item["Tbp"]=str(Tbp.strip())
item["Cbp"]=str(Cbp.strip())
item["Time"]=str(Time.strip())
yield item
item:
import scrapy
class BanksItem(scrapy.Item):
Currency = scrapy.Field()
Tsp = scrapy.Field()
Csp = scrapy.Field()
Tbp = scrapy.Field()
Cbp = scrapy.Field()
Time = scrapy.Field()
结果:

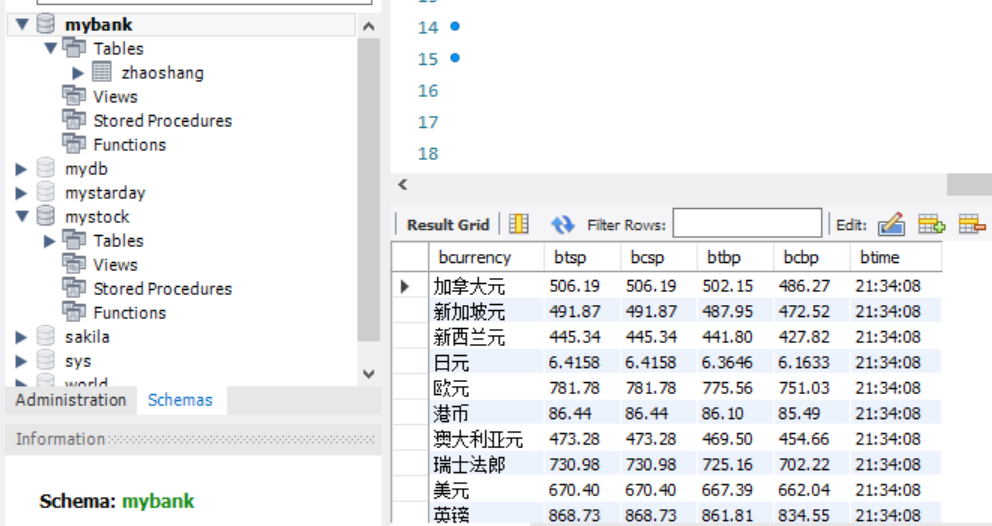
(2)心得体会:
一开始那边xpath最后一个错误,爬取出来的一直都是0,没有任何结果,想了大半天,最后是求助了大佬,才知道自己那个解析是错的,掀桌!