es解压下载安装,下载链接:链接: https://pan.baidu.com/s/1ye775EegzZHHcqUCSS6iNA 提取码: u3cb
tar -xzvf elasticsearch-5.6.1.tar.gz
启动:
cd elasticsearch-5.6.1/bin
./elasticsearch -d
查看启动:
ps -ef | grep Elasticsearch

两个问题:
1.报错:[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
vi /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
2.报错:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
修改/etc/sysctl.conf文件,增加配置vm.max_map_count=262144
vi /etc/sysctl.conf
sysctl -p 生效
在config目录下修改elasticsearch.yml文件增加:
network.host: 0.0.0.0
http.port: 9200
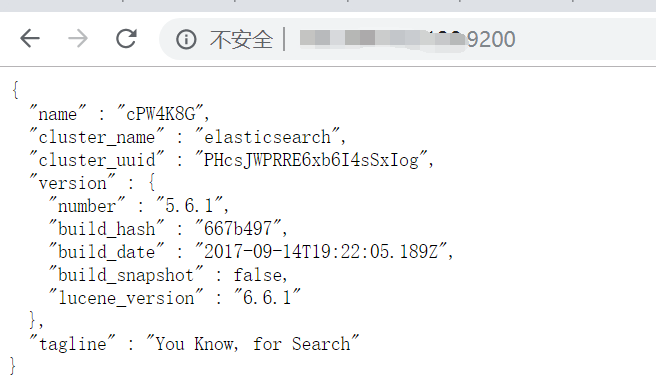
访问http://ip:9200,如下:
es集群配置:
es的config目录下elasticsearch.yml配置如下:
node-1:
#这是集群名字 cluster.name: my-es-demo #节点名 node.name: node-1 #必须为本机的ip地址 network.host: 192.168.132.128 #network.bind_host: 192.168.132.128 #设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0。 #network.publish_host: 192.168.132.128 #设置其它节点和该节点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址。 #这个参数是用来同时设置bind_host和publish_host上面两个参数。 http.host: 192.168.132.128 #设置节点间交互的tcp端口,默认是9300。 transport.tcp.port: 9300 #设置对外服务的http端口,默认为9200 http.port: 9200 #指定该节点是否有资格被选举成为node,默认是true,es是默认集群中的第一台机器为master,如果这台机挂了就会重新选举master node.master: true #指定该节点是否存储索引数据,默认为true node.data: true #设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点 discovery.zen.ping.unicast.hosts: ["192.168.132.128", "192.168.132.130"] #设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4 discovery.zen.minimum_master_nodes: 2 #设置集群中自动发现其它节点时ping连接超时时间,默认为3秒,对于比较差的网络环境可以高点的值来防止自动发现时出错 discovery.zen.fd.ping_timeout: 1m #失败或超时后重试的次数,默认3 discovery.zen.fd.ping_retries: 5
node-2:
#这是集群名字 cluster.name: my-es-demo #节点名 node.name: node-2 #必须为本机的ip地址 network.host: 192.168.132.130 #network.bind_host: 192.168.132.130 #设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0。 #network.publish_host: 192.168.132.130 #设置其它节点和该节点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址。 #这个参数是用来同时设置bind_host和publish_host上面两个参数。 http.host: 192.168.132.130 #设置节点间交互的tcp端口,默认是9300。 transport.tcp.port: 9300 #设置对外服务的http端口,默认为9200 http.port: 9200 #指定该节点是否有资格被选举成为node,默认是true,es是默认集群中的第一台机器为master,如果这台机挂了就会重新选举master node.master: true #指定该节点是否存储索引数据,默认为true node.data: true #设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点 discovery.zen.ping.unicast.hosts: ["192.168.132.128", "192.168.132.130"] #设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4 discovery.zen.minimum_master_nodes: 2 #设置集群中自动发现其它节点时ping连接超时时间,默认为3秒,对于比较差的网络环境可以高点的值来防止自动发现时出错 discovery.zen.fd.ping_timeout: 1m #失败或超时后重试的次数,默认3 discovery.zen.fd.ping_retries: 5
注:两台虚拟机的端口号9300和9200都要打开,如果集群有在同一台虚拟机下的http.port和transport.tcp.port要重新配置,
配置文件配置key: value信息的value值前要加上一个空格,不然会报错。
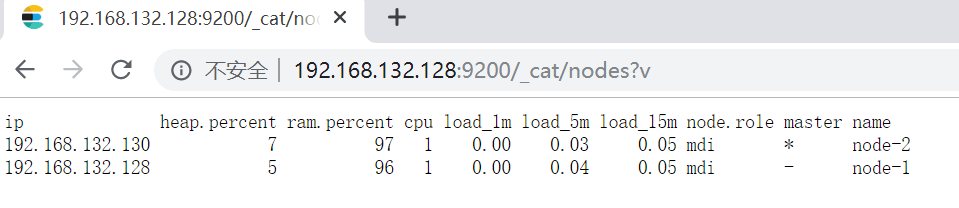
查看集群节点:http://192.168.132.128:9200/_cat/nodes?v
查看集群的健康状态:http://192.168.132.128:9200/_cat/health?v

kibana可视化管理工具安装:
下载解压和elasticsearch相同版本的,我这里是:kibana-5.6.1-linux-x86_64
启动前修改安装根目录的config下的kibana.yml文件:
server.port: 5601 server.name: "kibana-demo" server.host: "192.168.132.128" elasticsearch.url: "http://192.168.132.128:9200" elasticsearch.startupTimeout: 8000
在bin目录下执行:./kibana 效果如下图

然后访问:http://192.168.132.128:5601/
安装环境的jdk是1.8的。
