对颇具规模的Web服务进行日志收集、存储、分析、处理等;
ELK:ElasticSearch、Logstash、Kibana
ElasticSearch:是一个基于Lucene实现的开源的、分布式、RestFul的全文本搜索引擎;此外,它还是一个分布式实时文档存储,其中每个文档的每个field均是被索引的数据,且可被搜索;也是一个带实时分析功能的分布式搜索引擎,能够扩展至数以百计的节点,实时处理PB级的数据;
架构:
对于大规模的日志收集,都会专门的服务器用来将日志数据集中到一起进行整合。一般会在各个生产日志的节点上安装日志收集agent,然后通过agent向服务端发送日志数据。但是如果所有agent同时将日志发送给服务端,就算先不看服务端的性能,仅看网络带宽就是一个大问题,所以一般会在agent和服务端之间在放置一个消息队列(可以是redis、AMQP、kafka等)缓冲一下,然后服务端再一条一条的到队列中获取日志数据;
名词解释:
官网信息:https://www.elastic.co/guide/en/elasticsearch/reference/7.3/glossary.html#glossary-term
在Elasticsearch中存储数据的行为就叫做索引(indexing)
索引(index)这个词在Elasticsearch中有着不同的含义,所以有必要在此做一下区分:
索引(名词):如上文所述,一个索引(index)就像是传统关系数据库中的数据库,它是相关文档存储的地方,index的复数是indices 或indexes。
索引(动词):「索引一个文档」表示把一个文档存储到索引(名词)里,以便它可以被检索或者查询。这很像SQL中的INSERT关键字,差别是,如果文档已经存在,新的文档将覆盖旧的文档。
倒排索引:传统数据库为特定列增加一个索引,例如B-Tree索引来加速检索。Elasticsearch和Lucene使用一种叫做倒排索引(inverted index)的数据结构来达到相同目的。也可以理解为根据某个词找某个或某些文档;
文档(document):文档是Lucene索引和搜索的原子单位,它包含一个或多个域,是域的容器,基于JSON格式表示;
映射(mapping):原始内容存储为文档之前需要事先进行分析,例如切词、过滤某些词等;映射就是用于定义此分析机制应该如何实现;
示例:显示特定字段的类型;
~]# curl 'http://192.168.80.136:9200/students/_mapping/?pretty'
{
"students" : {
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"courses" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"first_name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"gender" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"last_name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
域由其名称和一个或多个值组成;
Note:ES对每个文档,会取得其所有域的所有值,生成一个名为_all的域。如果在query_string未指定查询的域,则在_all域上执行查询操作;
在Elasticsearch中,文档归属于一种类型(type),而这些类型存在于索引(index)中,且一个索引中可以有多种类型,我们可以画一些简单的对比图来类比传统关系型数据库:
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields
切词:对一段文字进行切割,可以词一句话也可以是一个词,然后以切割出来的词或句来进行搜索;或者是搜索相应的词或句时对其进行匹配;
域:
索引选项:用于通过倒排索引来控制文本是否可被索引;
Index.ANALYZED:分析(切词)并单独作为索引项;
Index.Not_ANALYZED:不分析(不切词),把整个内容当做一个索引项;
Index.ANALYZED_NORMS:类似于Index.ANALYZED,但不存储切词的Norms(加权基准)信息;
Index.Not_ANALYZED_NORMS:类似于Index.Not_ANALYZED,但不存储切词的Norms信息;
Index.NO:不对此域的值进行索引,因此不能被搜索;
存储选项:是否需要存储域的真实值;
store.YES:存储真实值(原值,切词以后原词的形式(比如大小写));
store.NO:不存储真实值;
文档和域的加权操作:
权重大的会在搜索结果中被优先显示;默认都是一样的;
搜索引擎进行搜索的流程:
获取原始内容 --> 构建文档 --> 文档分析 --> 创建索引 --> 用户查询 --> 构建查询 --> 运行查询(与创建索引密切相关) --> 返回结果 --> 展示给用户
我们可以使用Lucene创建索引但是它不获取且不提供供用户使用的搜索页面,所以我们可以将它看成一个库,可以通过调用它的API接口来实现索引创建相关的功能;对于搜索界面我们可以使用ElasticSearch来实现;
查询Lucene索引时,它返回的是一个有序的scoreDOC对象;查询时,Lucene会对每个文档计算出其score;
Lucene的查询:
IndexSearcher中的search方法:
TermQuery:对索引中的特定项进行搜索;Term是索引中的最小索引片段,每个Term包含了一个域名和一个文本值;
例子:
title: This is a pen;
owner:Tom;
des:It is blue;
title:This is a book;
owner:Jack
des:It has 400 pages;
当我们进行搜索时就可以指定在title或者owner范围内搜索指定内容;
TermRangeQuery:在索引中的多个特定项中进行搜索,能搜索指定的多个域;
NumericRangeQuery:对数值范围进行搜索;
PrefixQuery:用于搜索以指定字符串开头的项;
BooleanQuery:用于实现组合搜索;AND、OR、NOT;
WildcardQuery:使用通配符进行查询;
FuzzyQuery:模糊查询,比如查询与指定内容相似的内容;
Elasticsearch致力于隐藏分布式系统的复杂性。以下这些操作都是在底层自动完成的:
将你的文档分区到不同的容器或者分片(shards)中,它们可以存在于一个或多个节点中。
将分片均匀的分配到各个节点,对索引和搜索做负载均衡。
冗余每一个分片,防止硬件故障造成的数据丢失。
将集群中任意一个节点上的请求路由到相应数据所在的节点。
无论是增加节点,还是移除节点,分片都可以做到无缝的扩展和迁移。
ES的集群组件:
Cluster:ES的集群名称。节点就是靠此名称来决定加入到哪个集群中,且一个节点只能加入到一个集群中;
Node:运行了单个ES实例的主机即为节点。用于存储数据、参与集群索引及搜索操作;通过节点名标识此节点;
Shard:将索引分割成多个shard,存储在多个节点中;从而减少单个节点的磁盘IO的压力;默认情况下ES会将一个索引分割成5个shard,当然,用户也可以自定义,但是确定之后不可以再修改shard的数量;
shard有两种类型:primary shard和replica
primary shard用于文档存储,默认切割成5个primary shard;且ES还会为每个primary shard提供副本,当primary shard不可用是,其副本就会提升为primary shard,这个副本就是replica;其replica也可用于查询时的负载均衡;每个primary shard的replica数量也可以自定义;
ES集群状态:
green:正常状态
red:故障状态
yellow:修复状态
ES Cluster的工作过程:
启动时,ES的各个节点会通过组播(默认)或单播在TCP协议的9300端口查找同一集群中的其他节点,并与之建立通信;并且选举出一个主节点,负责管理集群状态,以及在集群范围内决定各shard的分布方式,这对用户是透明的,也就是说每个节点都可以接收和相应用户的请求;
ES通过http协议,使用9200接受客户的查询请求;
ES的安装:
1.准备环境:
安装ES需要安装JDK,使用OpenJDK或者OracleJDK都是可以的;
~]# yum install java-1.8.0-openjdk.x86_64 -y
~]# yum install java-1.8.0-openjdk-devel.x86_64 -y
~]# yum install java-1.8.0-openjdk-headless.x86_64 -y
配置JAVA的环境变量;
2.下载ES软件包:
官网下载地址:https://www.elastic.co/cn/downloads/elasticsearch/elasticsearch-7.3.0-x86_64.rpm
~]# yum install ./elasticsearch-7.3.0-x86_64.rpm 我下载的是rpm包
~]# sudo systemctl daemon-reload
~]# sudo systemctl enable elasticsearch.service
3.编辑配置文件:
~]# vim /etc/elasticsearch/elasticsearch.yml
cluster.name: myes 集群名称
node.name: node3 节点名称
http.port: 9200 监听端口
network.host: 192.168.80.129 绑定的主机地址
discovery.seed_hosts: ["192.168.80.129", "192.168.80.136"] 初始主机列表
cluster.initial_master_nodes: ["node3 ", "node2 "] 使用一组符合主节点条件的初始节点引导集群
更多参数请参考官网:https://www.elastic.co/guide/en/elasticsearch/reference/current/settings.html
4.启动ES:
~]# sudo systemctl start elasticsearch.service
Note:多个节点重复以上步骤即可;
ES的RestFul API:
1.检查集群、节点、索引等健康与否,以及获取及相应状态;
2.管理集群、节点、索引、及元数据;
查询数据:
查询方式:
1.通过RestFul request API查询,也成为query string;
2.通过发送REST request body进行;
分为两类:
query DSL:执行full-text查询时,基于相关度来评判其查询结果;
执行过程相对复杂,且不会被缓存;
filter DSL:执行exact查询时,基于其结果为“yes”或“no”进行评判;
速度快,且结果可以缓存;
示例:
~]# curl -XGET 'http://192.168.80.136:9200/students/_search/?pretty'
{
"took" : 24,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "students",
"_type" : "class1",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"first_name" : "Jing",
"last_name" : "Guo",
"gender" : "Male",
"age" : 25,
"courses" : "Xainglong shiba zhang"
}
}
]
}
}
~]# curl -H "Content-Type: application/json" -XGET 'http://192.168.80.136:9200/students/_search/?pretty' -d '
{
"query": { "match_all":{} }
}' 结果同上;
多索引、多类型查询:
/_search:查询所有索引
/INDEX_NAME/_search:单索引查询
/INDEX_NAME1,INDEX_NAME2/_search:多索引查询
/g*,w*/_search:通配索引查询
/INSEX_NAME/TYPE1,TYPE2/_search:多类型查询
3.执行CRUD(增删查改)操作;
示例:
创建文档:
~]# curl -H "Content-Type: application/json" -XPUT 'http://192.168.80.136:9200/students/class1/1?pretty' -d '
{
"first_name":"Jing",
"last_name":"Guo",
"gender":"Male",
"age":25,
"courses":"Xainglong shiba zhang"
}'
查看:
~]# curl -XGET 'http://192.168.80.136:9200/students/class1/1?pretty'
{
"_index" : "students",
"_type" : "class1",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"first_name" : "Jing",
"last_name" : "Guo",
"gender" : "Male",
"age" : 25,
"courses" : "Xainglong shiba zhang"
}
}
更新:
PUT方法会直接覆盖文档内容,如果只是更新部分内容,需要使用_update API;
~]# curl -H "Content-Type:application/json" -XPOST 'http://192.168.80.136:9200/students/class1/1/_update?pretty' -d '
> {
> "doc":{"age":28}
> }'
{
"_index" : "students",
"_type" : "class1",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}
删除:
~]# curl -XDELETE 'http://192.168.80.136:9200/students/class1/2'
{"_index":"students","_type":"class1","_id":"2","_version":2,"result":"deleted","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":3,"_primary_term":1}
4.执行各种高级操作;比如paging、filtering等
ES的请求格式:
向Elasticsearch发出的请求的组成部分与其它普通的HTTP请求是一样的:
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'
VERB HTTP方法:GET, POST, PUT, HEAD, DELETE
PROTOCOL http或者https协议(只有在Elasticsearch前面有https代理的时候可用)
HOST Elasticsearch集群中的任何一个节点的主机名,如果是在本地的节点,那么就叫localhost
PORT Elasticsearch HTTP服务所在的端口,默认为9200
PATH API路径(例如_count将返回集群中文档的数量),PATH可以包含多个组件,例如_cluster/stats或者_nodes/stats/jvm
QUERY_STRING 一些可选的查询请求参数,例如?pretty参数将使请求返回更加美观易读的JSON数据
BODY 一个JSON格式的请求主体(如果请求需要的话)
举例说明,为了计算集群中的文档数量,我们可以这样做:
curl -H "Content-Type: application/json" -XGET 'http://192.168.80.136:9200/_search?pretty' -d '
{
"query": {
"match_all": {}
}
}
'
Elasticsearch返回一个类似200 OK的HTTP状态码和JSON格式的响应主体(除了HEAD请求)。上面的请求会得到如下的JSON格式的响应主体:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 0,
"successful" : 0,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : 0.0,
"hits" : [ ]
}
}
我们看不到HTTP头是因为我们没有让curl显示它们,如果要显示,使用curl命令后跟-i参数:
curl -i -XGET 'localhost:9200/'
示例:
~]# curl -XGET 'http://192.168.80.136:9200/_cat/nodes?v' 显示字段名
~]# curl -XGET 'http://192.168.80.129:9200/_cat/nodes?help' 显示帮助信息
Note:ES有很多的API,具体参见官网:https://www.elastic.co/guide/en/elasticsearch/reference/current/rest-apis.html
ES的Plugins:
插件扩展的功能:添加自定义的映射类型、自定义分析器、本地脚本、自定义发现方式等;
安装插件的方式:
1.直接将插件放置到plugins目录(/usr/share/elasticsearch/plugins)中;
2.使用plugin(/usr/share/elasticsearch/bin/elasticsearch-plugin)命令进行添加插件;
有关插件的文档:https://www.elastic.co/guide/en/elasticsearch/plugins/7.3/index.html https://www.elastic.co/guide/en/kibana/current/kibana-plugins.html
Logstash:负责数据的收集
官网简介:https://www.elastic.co/guide/en/logstash/current/introduction.html
可以通过Agent在各个产生日志的服务器上收集数据,然后再通过Agent将数据统一发送到Logstash服务器中进行统一处理,再存储到ElasticSearch上;
支持多种数据获取机制,通过TCP/UDP协议、文件、syslog、Windows EventLogs及STDIN等;获取到数据后,它还支持对数据进行过滤修改等操作;
使用JRuby语言开发,因此安装环境需要JVM;
Logstash的许多功能都是使用插件完成的,所以Logstash必须加载各种插件从而完成其各种功能;
插件类型:输入插件、编码插件、过滤插件、输出插件
工作流程:input|filter|output
各种插件:https://www.elastic.co/guide/en/logstash-versioned-plugins/current/index.html
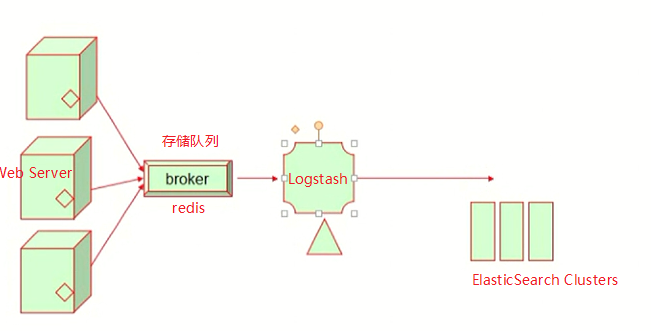
安装Logstash:
1.环境搭建:
安装JDK(前面已经介绍了,就不赘述了!)
2.下载软件包并安装:
下载地址:https://www.elastic.co/cn/downloads/logstash
~]# yum install ./logstash-7.3.0.rpm
3.测试
~]# /usr/share/logstash/bin/logstash -e 'input { stdin { } } output { stdout {} }'

Ctrl+D退出;
更多参数:https://www.elastic.co/guide/en/logstash/current/running-logstash-command-line.html
4.配置文件:/etc/logstash/以及/etc/logstash/conf.d/(自定义的配置信息建议放在这里且以".conf"结尾)
配置文件的框架:
input {
……
}
filter {
……
}
output {
……
}
Logstash的插件:
input插件:
file:从指定的文件中读取事件流;使用FileWatch(Ruby Gem库)监视文件是否变化且可以同时监视多个文件,还可以保存文件的读取位置,以方便以后接着读取(存储在.sincedb,其记录了每个被监视的文件的inode、major、minor、number、pos等);
默认以单行数据为一个事件作为一次读取,但是可以通过编码器将文本中的多行合并成一行进行一次读取;
示例:
~]# cat /etc/logstash/conf.d/file.conf
input {
file {
path => ["/var/log/messages"]
type => "system"
start_position => "beginning"
}
}
output {
stdout {
codec => rubydebug
}
}
~]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/file.conf
运行此命令就会将/var/log/messages中所有的信息都输出到STDOUT;
udp:通过udp协议从网络连接读取Message,其必备的参数为port(自己监听的端口号)和host(自己监听的地址);
如果使用udp作为输入插件,则在被收集端还应该有一个与其对应的软件来完成将其数据主动发送到收集端(Logstash端)中,可以使用nc或者collectd(位于epel源中)中的network插件(通过Server配置段指定Logstash的地址即可)完成相应的功能;当然还有很多其他的软件可以使用;
Note:Logstash端input{}要使用collectd专用的编码器(codec => collectd {});
redis插件:
从redis读取数据,支持redis channel和lists两种方式;
filter插件:
用于在将event(事件)通过output发出之前对其进行某些处理操作;
grok插件:
用于分析并结构化文本数据的插件;是Logstash中将非结构日志数据转化为结构化可查询数据的不二之选;
结构化方式:
通过将数据的各个字段进行重新命名来实现数据的结构化,比如apache的日志,其中字段依次是客户端的IP地址、用户、组、访问时间、方法、URL、版本、状态码、大小、referer以及客户端代理;grok就是通过将各个字段定义为某个名称,然后在输出时用各个键值对表示其数据结构形式;
ip => 192.168.80.123
user => liubocheng
……
文件/usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns/grok-patterns中就包含了其支持的各种形式,并且也支持自定义格式;
output插件:
redis插件:
示例:
1.配置redis.conf
vim /etc/redis.conf
port 6379
bind 0.0.0.0
2.配置被收集端的Logstash
~]# cat /etc/logstash/conf.d/redis.conf
input {
file {
path => ["/var/log/messages"]
type => "system"
start_position => "beginning"
}
}
output {
redis {
port => "6379"
host => ["127.0.0.1"]
data_type => "list"
key => "logstash-%{type}"
}
}
3.配置收集端的Logstash
~]# cat /etc/logstash/conf.d/redis.conf
input {
redis {
port => "6379"
host => "192.168.80.129"
data_type => "list"
key => "logstash-system"
}
}
output {
stdout {
codec => rubydebug
}
}
4.在收集端执行命令进行测试
~]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/redis.conf
5.将收集的数据存储到ES中
~]# cat /etc/logstash/conf.d/redis.conf
input {
redis {
port => "6379"
host => "192.168.80.129"
data_type => "list"
key => "logstash-system"
}
}
filter {
mutate {
rename => { "[host][name]" => "host" }
}
}
output {
elasticsearch {
hosts => ["192.168.80.129:9200"]
id => "redis"
index => "logstash-%{+YYYY.MM.dd}"
}
}
Note:lumberjack可以代替客户端的Logstash作为发送数据的Agent,因为Logstash作为客户端Agent太重量级了;
安装Kibana:
1.下载并安装软件包:
https://www.elastic.co/cn/downloads/kibana
~]# yum install ./kibana-7.3.0-x86_64.rpm -y
2.配置文件:
~]# vim /etc/kibana/kibana.yml
server.port: 5601
server.host: "node2.guowei.com"
指定Kibana服务器将绑定到的地址。IP地址和主机名都是有效值。要允许来自远程用户的连接
server.name: "node2.guowei.com"
指定节点名称,可以是任意字符
elasticsearch.hosts: ["http://node2.guowei.com:9200"]
指定ES的监听地址
kibana.index: ".mykibana"
Kibana在Elasticsearch中使用索引来存储保存的搜索、可视化和仪表盘。如果索引不存在,Kibana将创建一个新索引。
xpack.security.enabled: false
配置kibana的安全机制,测试时可以关闭。
3.启动Kibana
systemctl start kibana.service
4.在浏览器中键入http://192.168.80.129:5601即可连接至Kibana
借鉴文章:https://es.xiaoleilu.com/index.html
根据马哥视频做的学习笔记,如有错误,欢迎指正;侵删