MapReduce:能够将某个处理任务分割成任务单元,然后并行运行在集群中的各节点上,并且最后能搜集各节点上的结果做二次处理,直至得到最终结果的并行处理框架;
MapReduce既是一种编程模型,也是一种与之关联的、用于处理和产生大数据集的实现。用户要特化一个map程序去处理key/value对,并产生中间key/value对的集合,以及一个reduce程序去合并有着相同key的所有中间key/value对。
计算过程就是输入一组key/value对,再生成输出一组key/value对。MapReduce库的使用者用两个函数来表示这个过程:map和reduce。
map由使用者编写,使用一个输入key/value对,生成一组中间key/value对。MapReduce库将有着相同中间key I的中间value都组合在一起,再传给reduce函数。
reduce也由使用者编写,它接受一个中间key I和一组与I对应的value。它将这些value合并为一个可能更小的value集合。通常每个reduce调用只产生0或1个输出value。中间value是通过一个迭代器提供给reduce函数的。这允许我们操作那些因为大到找不到连续存放的内存而使用链表的value集合。
Job Tracker:用于决定任务的运行位置,以及具体的执行方式;
Task Tracker:每个负责执行任务的节点在MapReduce中被称为Task Tracker;


HDFS:元数据存储在一个单独的服务器(NameNode)上并且会将数据存储在内存中,所以我们一般都会将数据在磁盘上再保存一份,以防服务器崩溃时数据丢失。但是磁盘中的元数据难免会比内存中的元数据缺少一些,所以我们使用一个类似于mysql中的事务日志的文件来提供原子操作(FsImage和EditLog是HDFS的中心数据结构。这些文件损坏可能导致HDFS实例无法正常运行。因此,NameNode可以配置为支持维护FsImage和EditLog的多个副本。对FsImage或EditLog的任何更新都会导致每个FsImages和EditLogs同步更新。这种FsImage和EditLog的多个副本的同步更新可能会降低NameNode可以支持的每秒命名空间事务的速率。但是,这种降级是可以接受的,因为即使HDFS应用程序本质上是数据密集型的,它们也不是元数据密集型的。当NameNode重新启动时,它会选择要使用的最新一致FsImage和EditLog。)。其实HDFS还提供了SecondNameNode,用于专门来实现将EditLog中的数据同步到磁盘上,如果NN宕机了,SNN可以读取存储在磁盘上的元数据从而提供服务(但是这个读取过程可能是漫长的,尤其是拥有大量数据的情况下);其实各种数据存储在各个单独的数据服务器(DataNode)上,各个DN会将自己所拥有的数据块报告给NN,并且为了数据的可靠性每个DN还可能会存储位于其他DN上的数据块的副本;
https://blog.csdn.net/sjmz30071360/article/details/79877846 https://www.cnblogs.com/qingyunzong/p/8548806.html https://www.jianshu.com/p/7843caa9b41a
Hadoop就是MapReduce和HDFS的结合,可以理解成HDFS的DN和MapReduce的Task Tracker是运行在一个服务器节点上的,让具体任务和数据处于一个位置,方便任务的执行;HDFS的NN自己位于一个服务器节点,SNN位于一个服务器节点;Job Tracker自己位于一个服务器节点,也可以与HDFS的NN位于同一个节点;
Hadoop本质上只是提供了一个分布式存储数据的平台和一个可以基于数据开发针对数据的处理程序的环境;如果仅是将数据存储到Hadoop的DHFS中,Hadoop是什么都做不了的,还要提供处理这些数据的程序,并且这个程序是要基于Hadoop提供的环境(MapReduce环境)来开发的,即通过map/reduce函数以及Hadoop API来实现指定功能;
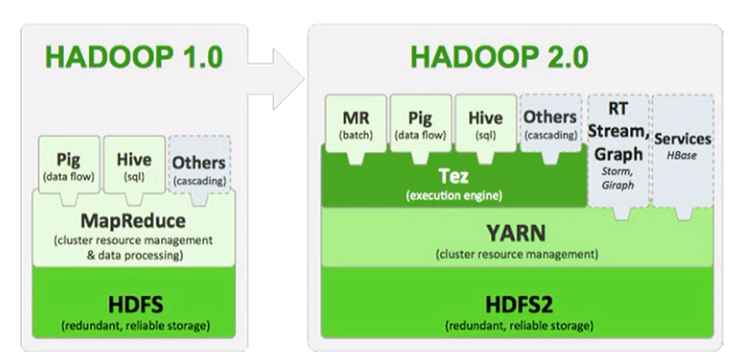


YARN简介:https://hadoop.apache.org/docs/r2.6.5/hadoop-yarn/hadoop-yarn-site/YARN.html
MR的版本分隔岭:
v1:MR负责管理Cluster resource manager与Data processing;
v2:
YARN:负责管理Cluster resource manager
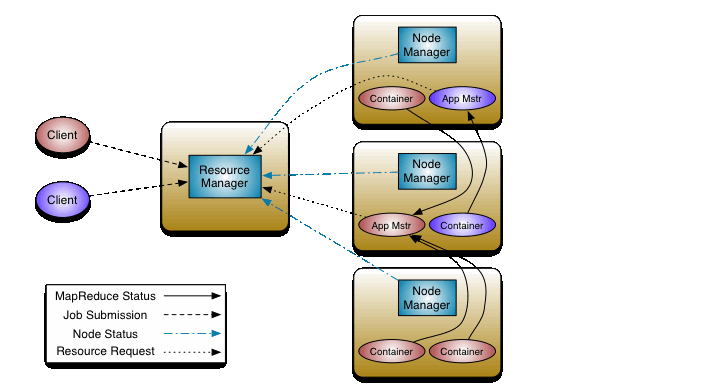
Resource Manager:负责管理资源,位于Job Tracker节点;主要包含两个组件Scheduler和ApplicationsManager;
Scheduler:负责在各种队列、应用程序等之间对集群资源进行分区;
AM(applicationMaster):应用程序管理器,负责管理每个程序任务所需的资源,并且负责向RM请求为其调度程序运行所需要的资源,此处的资源就是container;其包含内存,cpu,磁盘,网络等元素;
Node Manager:NodeManager是每台机器的框架代理,负责监视容器的资源使用情况(cpu、内存、磁盘、网络),并向ResourceManager/Scheduler报告相同的情况;位于Task Tracker节点;
MR:负责管理批处理
Tez:负责提供运行时运行,即执行引擎
命令用法:
hdfs:http://hadoop.apache.org/docs/r3.2.0/hadoop-project-dist/hadoop-hdfs/HDFSCommands.html yarn:http://hadoop.apache.org/docs/r3.2.0/hadoop-yarn/hadoop-yarn-site/YarnCommands.html mapred:http://hadoop.apache.org/docs/r3.2.0/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapredCommands.html
Hadoop集群的搭建:
拓扑描述:一共四台主机,其中三台数据节点,一台作为NN、SNN与RM节点;
~]# cat /etc/hosts 192.168.80.128 master node1.guowei.com NN、SNN、RM节点 192.168.80.129 node2.guowei.com DN、NM节点 192.168.80.139 node3.guowei.com DN、NM节点 192.168.80.138 node6.guowei.com DN、NM节点 RM节点运行ResourceManager; DN节点运行DataNode以及NodeManager; NN节点运行NameNode以及SecondaryNameNode; Note:生产环境中NN、SNN以及RM要分别位于不同的主机之上,这里是因为我没有那么多的主机节点才这样做的;
1.配置好Hadoop的运行环境:因为Hadoop是使用Java开发的,所以各个节点都需要安装JDK;
~]# yum install java-1.8.0-openjdk.x86_64 java-1.8.0-openjdk-devel.x86_64 -y ~]# cat /etc/profile.d/java.sh export JAVA_HOME=/usr
配置Hadoop的环境变量:
~]# cat /etc/profile.d/hadoop.sh export HADOOP_HOME=/dbapps/hadoop/ export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin export HADOOP_COMMON_HOME=${HADOOP_HOME} export HADOOP_YARN_HOME=${HADOOP_HOME} export HADOOP_HDFS_HOME=${HADOOP_HOME} export HADOOP_MAPRED_HOME=${HADOOP_HOME}
2.在各个节点添加hadoop用户并创建相关目录:
~]# useradd hadoop ~]# echo "hadoop" | passwd --stdin hadoop 每个节点都要操作 ~]# mkdir -pv /dbapps /data/hadoop/hdfs/{nn,snn,tmp} 只有NN这么操作 ~]# chown -R hadoop:hadoop /data/hadoop/hdfs/
3.配置ssh基于秘钥认证,使NN可以登录DN、SNN节点,使NN可以通过脚本启动DN节点中的DN进程;yarn同理,使RM可以登录NM:
在NN节点上:
~]# su - hadoop ~]# ssh-keygen -t rsa -P '' ~]# ssh-copy-id -i .ssh/id_rsa.pub hadoop@node1.guowei.com ~]# ssh-copy-id -i .ssh/id_rsa.pub hadoop@node2.guowei.com ~]# ssh-copy-id -i .ssh/id_rsa.pub hadoop@node3.guowei.com ~]# ssh-copy-id -i .ssh/id_rsa.pub hadoop@node6.guowei.com
4.安装hadoop:
~]# tar xf hadoop-3.2.0.tar.gz -C /dbapps/ ~]# cd /dbapps/ ~]# ln -sv hadoop-3.2.0/ hadoop ~]# mkdir logs 默认的日志文件会存储在这里 ~]# chmod g+w logs/ 因为只使用了hadoop用户,所以这里可以不用设置;如果是分别使用yarn、hdfs、mapred用户则需要此项设置; ~]# chown hadoop:hadoop ./* -R
5.编辑配置文件:
配置NN以及RM节点 ~]# cd /dbapps/hadoop/etc/hadoop ~]# cat core-site.xml <configuration> <property> <name>hadoop.tmp.dir</name> <value>/data/hadoop/hdfs/tmp</value> </property> #设置hadoop产生的临时文件的位置;此项配置关联了很多其他配置,默认是存储在/tmp目录中以用户名命名的目录中的,但是每次重启节点或者定期系统都会清理/tmp目录,所以不建议使用默认目录; <property> <name>fs.defaultFS</name> <value>hdfs://master</value> </property> #指定HDFS存储节点 </configuration> ~]# cat yarn-site.xml <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> #指定RM节点所在的位置,这一块的设置尤为重要,因为有很多其他的设置默认都是以这里的设置为默认变量参数; 官网资料:http://hadoop.apache.org/docs/r3.2.0/hadoop-yarn/hadoop-yarn-common/yarn-default.xml <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> #关闭内存检测,如果是虚拟机,则需要配置; </configuration> ~]# cat mapred-site.xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> #用于执行MapReduce作业的运行时框架。可以是local、classic、或者yarn; 官网资料:http://hadoop.apache.org/docs/r3.2.0/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml </configuration> ~]# cat hdfs-site.xml <configuration> <property> <name>dfs.namenode.name.dir</name> <value>file:///data/hadoop/hdfs/nn</value> </property> #配置NN存储数据的目录 <property> <name>dfs.datanode.data.dir</name> <value>file:///data/hadoop/hdfs/dn</value> </property> #配置DN存储数据的目录;对NN不起作用 <property> <name>dfs.namenode.checkpoint.edits.dir</name> <value>file:///data/hadoop/hdfs/snn</value> </property> #确定DFS辅助名称(SNN)节点应该在本地文件系统的何处存储要合并的临时编辑。如果这是一个以逗号分隔的目录列表,则编辑将复制到所有目录中,以实现冗余; <property> <name>dfs.namenode.checkpoint.dir</name> <value>file:///data/hadoop/hdfs/snn</value> </property> #确定DFS辅助名称(SNN)节点应将要合并的临时映像存储在本地文件系统的何处。如果这是一个以逗号分隔的目录列表,则为了冗余起见,将映像复制到所有目录中; <property> <name>dfs.replication</name> <value>3</value> </property> #指定备份的份数; <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> #如果“true”,在HDFS中启用权限检查。如果“false”,则关闭权限检查,但所有其他行为不变; <property> <name>dfs.namenode.http-address</name> <value>master:9870</value> </property> #指定NN监听的Web URL地址及端口; <property> <name>dfs.namenode.secondary.http-address</name> <value>master:9868</value> </property> #指定SNN监听的Web URL地址及端口; </configuration>
~]# cat workers 指定所管理的DN主机
node2.guowei.com
node3.guowei.com
node6.guowei.com
配置DN及NM节点: ~]# mkdir -pv /data/hadoop/hdfs/{dn,tmp} /dbapps ~]# chown hadoop:hadoop -R /data/hadoop/hdfs/ ~]# tar xf hadoop-3.2.0.tar.gz -C /dbapps/ ~]# cd /dbapps/ ~]# ln -sv hadoop-3.2.0/ hadoop ~]# cd /dbapps/hadoop ~]# mkdir logs ~]# chmod g+w logs/ ~]# chown hadoop:hadoop -R ./*
在NN上操作: ~]# su - hadoop ~]# scp /dbapps/hadoop/etc/hadoop/* node2.guowei.com:/dbapps/hadoop/etc/hadoop/ ~]# scp /dbapps/hadoop/etc/hadoop/* node3.guowei.com:/dbapps/hadoop/etc/hadoop/ ~]# scp /dbapps/hadoop/etc/hadoop/* node6.guowei.com:/dbapps/hadoop/etc/hadoop/ ~]# scp /etc/profile.d/hadoop.sh node2.guowei.com:/etc/profile.d/ ~]# scp /etc/profile.d/hadoop.sh node3.guowei.com:/etc/profile.d/ ~]# scp /etc/profile.d/hadoop.sh node6.guowei.com:/etc/profile.d/ ~]$ hdfs namenode -format 格式化命名空间 ~]$ start-all.sh 在master节点启动所有服务 ~]$ jps 4546 NameNode 4818 SecondaryNameNode 9074 Jps 5031 ResourceManager
在各DN上操作: ~]# su - hadoop ~]$ jps 5764 DataNode 6124 Jps 5871 NodeManager
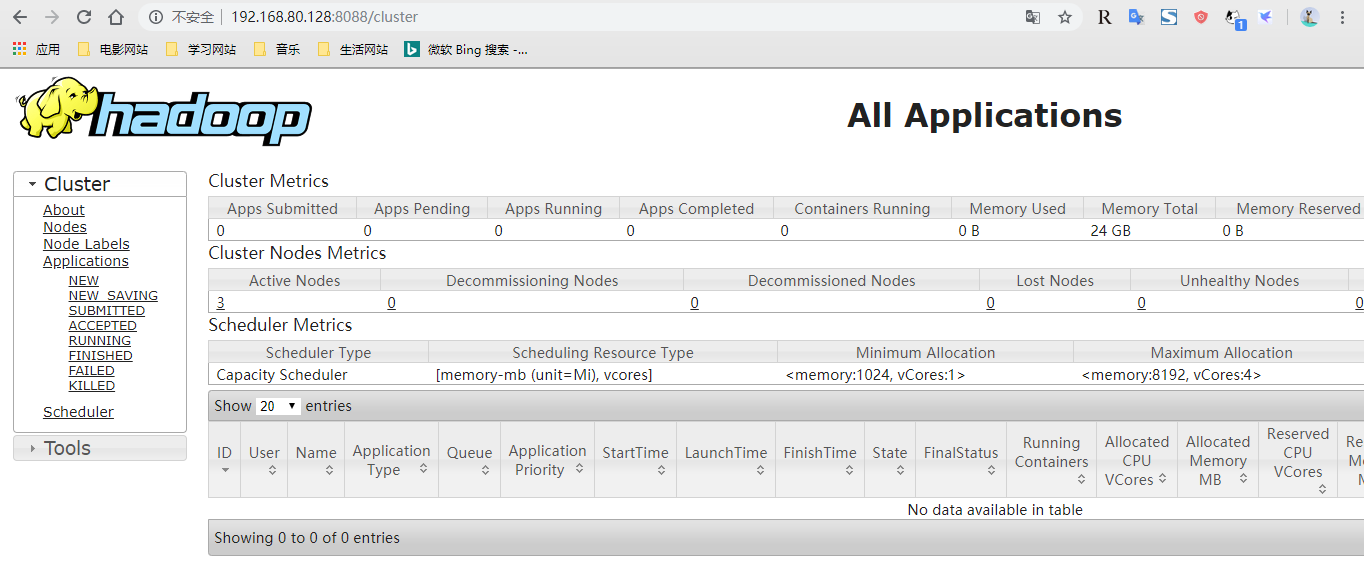

Note:此处的配置不适合生产环境,因为NN以及DN节点有很多服务的监听地址都是0.0.0.0(默认),这是极其不安全的,所以在生产环境中还需要进行更细粒度的设置,具体信息查看上面给出的官网地址即可;
~]$ yarn jar /dbapps/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar 查看自带的测试小程序 ~]$ hdfs dfs -put /etc/fstab /test/fstab 上传一个小文件 ~]$ yarn jar /dbapps/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar wordcount /test/fstab /test/fstab1 统计文本fstab中各个单词出现的次数,并将结果输出到fstab1中; ~]$ hdfs dfs -cat /test/fstab1/part-r-00000
报错解决方案:https://blog.csdn.net/hongxiao2016/article/details/88919176
Hadoop还可以使用Ambari进行自动安装部署;
借鉴文章:https://www.cnblogs.com/fuzhe1989/p/3413457.html
注:根据马哥视频做的学习笔记,如有错误,欢迎指正;侵删 && 文内图片来自互联网,侵删