参考:https://www.cnblogs.com/kubidemanong/p/10834993.html
public class TreeNode { public char Char; public bool IsEnd; public int WordEndAt; private Dictionary<char, TreeNode> NodeDict; public TreeNode(char c) { Char = c; IsEnd = false; NodeDict = new Dictionary<char, TreeNode>(); } public bool ContainChar(char ch) { return NodeDict.ContainsKey(ch); } public TreeNode GetChild(char c) { TreeNode Child = null; NodeDict.TryGetValue(c, out Child); return Child; } public TreeNode AddNode(char ch) { TreeNode insertNode = null; if (!NodeDict.TryGetValue(ch, out insertNode)) { insertNode = new TreeNode(ch); NodeDict.Add(ch, insertNode); } return insertNode; } }
public class Trie { public TreeNode Root { get; } private HashSet<char> SkipCharSet; //忽略字符 private HashSet<char> SeparateCharSet; //常见分隔符 private string skipCharList = " `-=[]\',.·/~!@#$%^&*()_+{}|:"<>?* "; private TreeNode checkNode; private TreeNode backupNode; private char duplicateChar; public Trie() { Root = new TreeNode(' '); SkipCharSet = new HashSet<char>(); SeparateCharSet = new HashSet<char>(); foreach (char c in skipCharList) { SkipCharSet.Add(c); SeparateCharSet.Add(c); } } public void AddNode(TreeNode node, string word) { if (word.Length > 0) { char ch = word[0]; TreeNode insertNode = node.AddNode(ch); if (word.Length == 1) { insertNode.IsEnd = true; } word = word.Remove(0,1); AddNode(insertNode, word); } } private bool IsSkipChar(char c) { return SkipCharSet.Contains(c); } //是否是英文 private bool IsEnglishChar(char ch) { string str = new string(ch, 1); Regex regEnglish = new Regex("^[a-zA-Z]"); return regEnglish.IsMatch(str); } //是否是分割符 private bool Separator(char ch) { return SeparateCharSet.Contains(ch); } //是否是单词的开头 private bool IsWordBegin(string word,int pos) { if (pos == 0) return true; if (pos < word.Length) { char c1 = word[pos - 1]; char c2 = word[pos]; return (Separator(c1) && !Separator(c2)) || (!IsEnglishChar(c1) && IsEnglishChar(c2)); } return false; } //是否是单词的结尾 private bool IsWordEnd(string word,int pos) { if (pos == word.Length - 1) return true; if(pos < word.Length) { char c1 = word[pos]; char c2 = word[pos + 1]; return (!Separator(c1) && Separator(c2)) || (IsEnglishChar(c1) && !IsEnglishChar(c2)); } return false; } private void CheckWord(string checkWord,int begin) { int index = begin; while(index + 1 < checkWord.Length) { ++index; char ch = checkWord[index]; if (IsSkipChar(ch)) { if (checkNode.ContainChar(ch)) checkNode = checkNode.GetChild(ch); } else { if(checkNode.ContainChar(ch)) { checkNode = checkNode.GetChild(ch); if(checkNode.IsEnd) { checkNode.WordEndAt = index; backupNode = checkNode; duplicateChar = ch; CheckWord(checkWord,index); //继续匹配 break; } } else { if (duplicateChar == ch) //屏蔽fuccccccck例如这样的 backupNode.WordEndAt = index; else break; } } duplicateChar = ch; } } public string Filter(string filterWord) { int begin = 0; checkNode = null; backupNode = null; duplicateChar = ' '; string word = filterWord.ToLower(); StringBuilder result = new StringBuilder(filterWord); while(begin < word.Length) { checkNode = Root; backupNode = Root; char ch = word[begin]; duplicateChar = ch;
//设置是否严格匹配, 即逐个字符检测是否有可能是敏感词,否则像英语一样只检测单词,
//严格匹配: [av]是敏感词,那么[avoid]被替换成[**oid]
bool isStrict = !IsEnglishChar(ch);
bool isWordBegin = isStrict || IsWordBegin(word, begin); if(isWordBegin && checkNode.ContainChar(ch)) { checkNode = checkNode.GetChild(ch); if(!IsSkipChar(ch)) { CheckWord(word, begin); if(backupNode.IsEnd && backupNode.WordEndAt > 0) { bool isWordEnd = isStrict || IsWordEnd(word, backupNode.WordEndAt); //到单词末尾才行 have 中有av 但是不是末尾 所以不是屏蔽词 if(isWordEnd) { for(int i = begin; i <= backupNode.WordEndAt;++i) { result[i] = '*'; } begin = backupNode.WordEndAt; } } } } ++begin; } return result.ToString(); } }
测试用例:
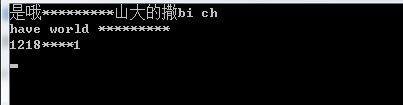
class Program { static void Main(string[] args) { Trie trie = new Trie(); trie.AddNode(trie.Root, "fuc"); trie.AddNode(trie.Root, "fuc bitch"); trie.AddNode(trie.Root, "fuck"); trie.AddNode(trie.Root, "bitch"); trie.AddNode(trie.Root, "屠杀"); Console.WriteLine(trie.Filter("是哦fuckkkkkk山大的撒bi ch")); Console.WriteLine(trie.Filter("have world fuc bitch")); Console.WriteLine(trie.Filter("1218fuck1")); Console.ReadKey(); } }
结果: