InfluxDB
Docker version: 19.03.8
运行容器实例:
docker run -d
--rm
--name influxdb
-p 8086:8086
-v /opt/docker/influxdb:/var/lib/influxdb
--hostname=influxdb
influxdb:1.8.0
这里不需要再额外为influx开放8083端口,因为InfluxDB 1.3以及之后的版本,已经取消了自带的web管理页面了,取而代之的是使用Chronograf。启动Chronograf容器实例:
这里选择是否创建Chronograf并不会影响后续的操作;
docker run -d
-p 8888:8888
--name chronograf
-v /opt/docker/chronograf:/var/lib/chronograf
chronograf:1.8
Chronograf 容器启动后,访问:IP:8888,进入控制台页面。
 除了使用Chronograf,若要在本地连接InfluxDB数据库,还可以下载使用 InfluxDB Studio.
除了使用Chronograf,若要在本地连接InfluxDB数据库,还可以下载使用 InfluxDB Studio.
influxdb 容器启动成功后,进入容器内的/usr/bin目录,这里面存放了Influxdb相关的工具:
docker exec -it influxdb bash
cd /usr/bin
find | grep influx
./influx_stress
./influx_inspect
./influx
./influxd
./influx_tsm
# 查看版本
./influx -version
InfluxDB shell version: 1.8.0
# 进入Influxdb客户端命令行
./influx
# 创建数据库用户root,并设置密码
CREATE USER "root" WITH PASSWORD "123456" WITH ALL PRIVILEGES
# 创建jenkins数据库
`CREATE DATABASE jenkins
Jenkins
Jenkins需要安装influxdb插件,承担数据采集的角色,在项目构建完成后,将本次构建信息推送到数据库中,后续Grafana配置好数据源后,就可以将数据进行可视化展示。

插件安装完成后,进入系统配置页面,设置下InfluxDB Targets:
配置保存成功后,进入项目配置页面,添加构建后操作。
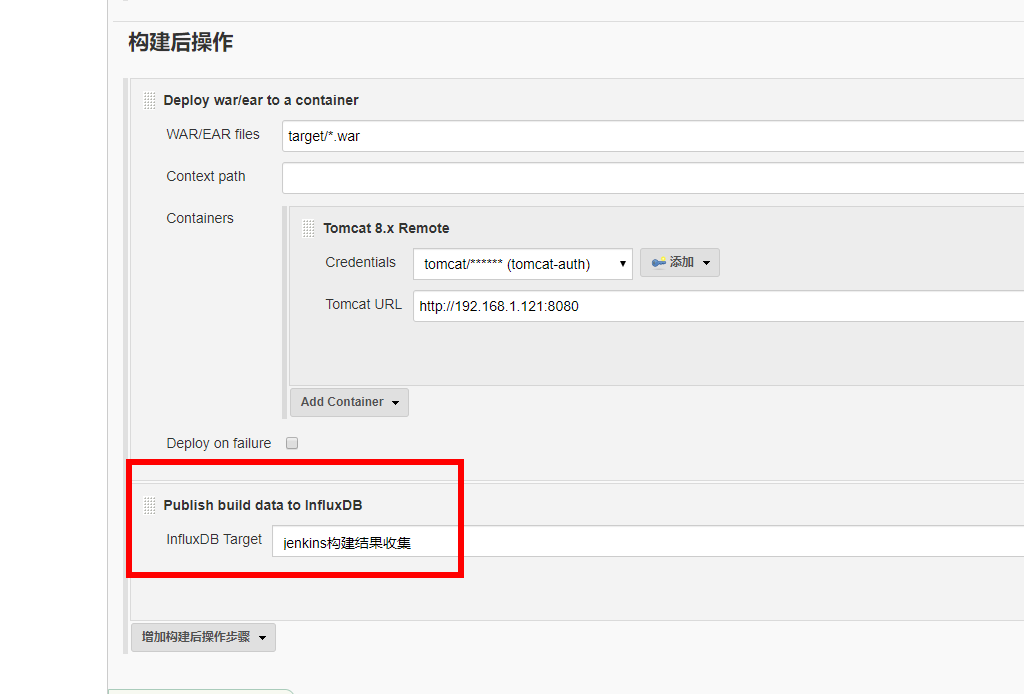
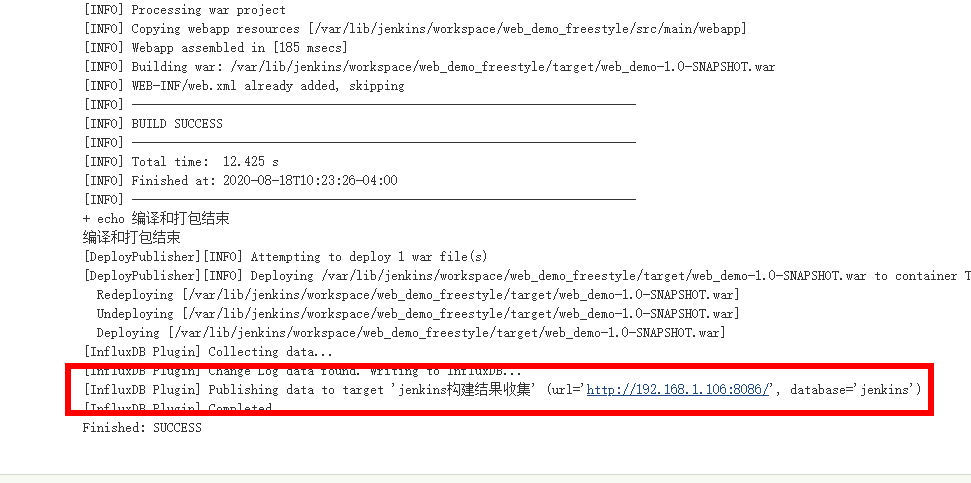
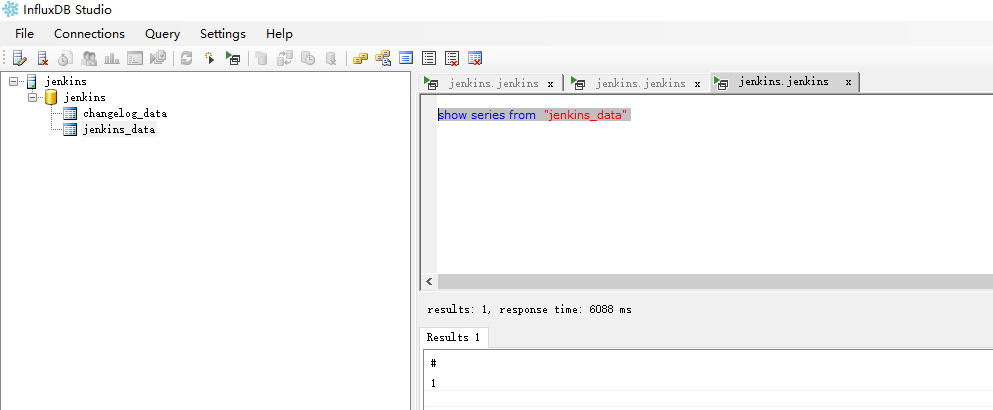
当项目构建完成后,会自动上报十分详细的构建信息到数据库中,通过InfluxDB Studio连接数据库,可以看到一些数据表已经自动被创建了。
Grafana
我是之前在k8s的一套测试环境安装的kube-promethus,直接拿过来用
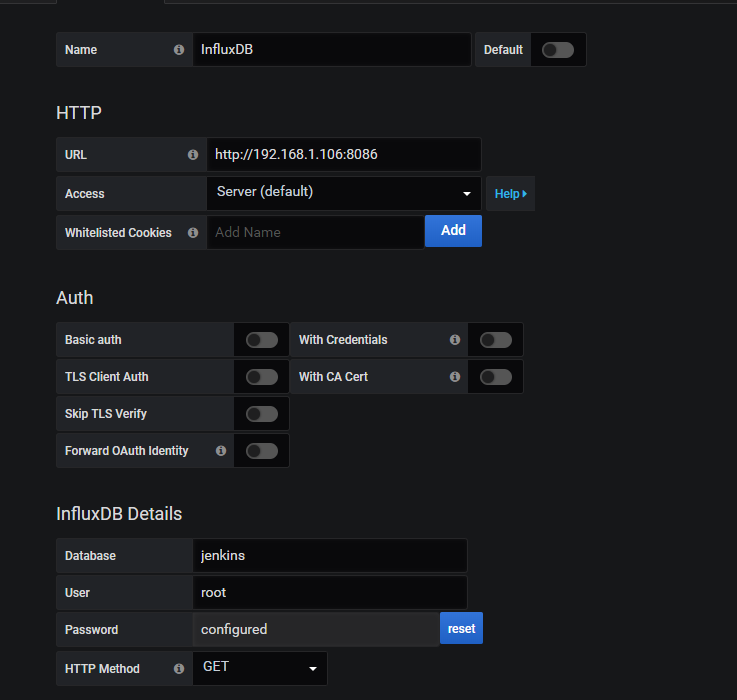
配置Grafana 数据源
数据源可以配置多个,配置项和Jenkins中一致就可以了。
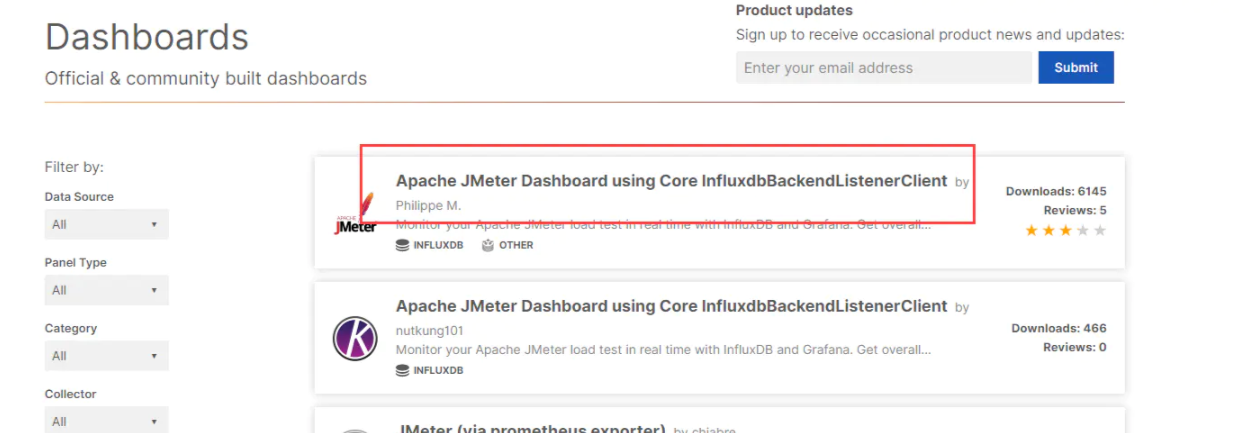
Jenkins Dashboard
Grafana提供了导入Dashboards模板的功能,在官网可以搜索很多别人已经实现的模板,我们只需要按需导入即可,十分方便,这里以Jmeter为例,进入官网 Grafana Dashboards 搜索页面,点击搜索结果中的第一条:
在页面右侧可以看到模板ID为5496,复制此ID,进入Grafana控制台页面,点击左侧的加号,选择Import然后输入模板ID,并导入即可,导入成功后,会自动新建一个 Jmeter Dashboard。
这里尝试去搜索Jenkins相关的模板,发现并没有符合我们要求的模板,所以后续是通过手动配置的方式来完成的,需要手动创建一个名为Jenkins的Dashboard,然后在进行后续操作。
创建环境变量
采集到的数据是包括所有jenkins项目的构建数据,在利用这部分数据时,可以创建项目名称变量(projectName),这个变量实际就是Jenkins的Job Name,配置如下:
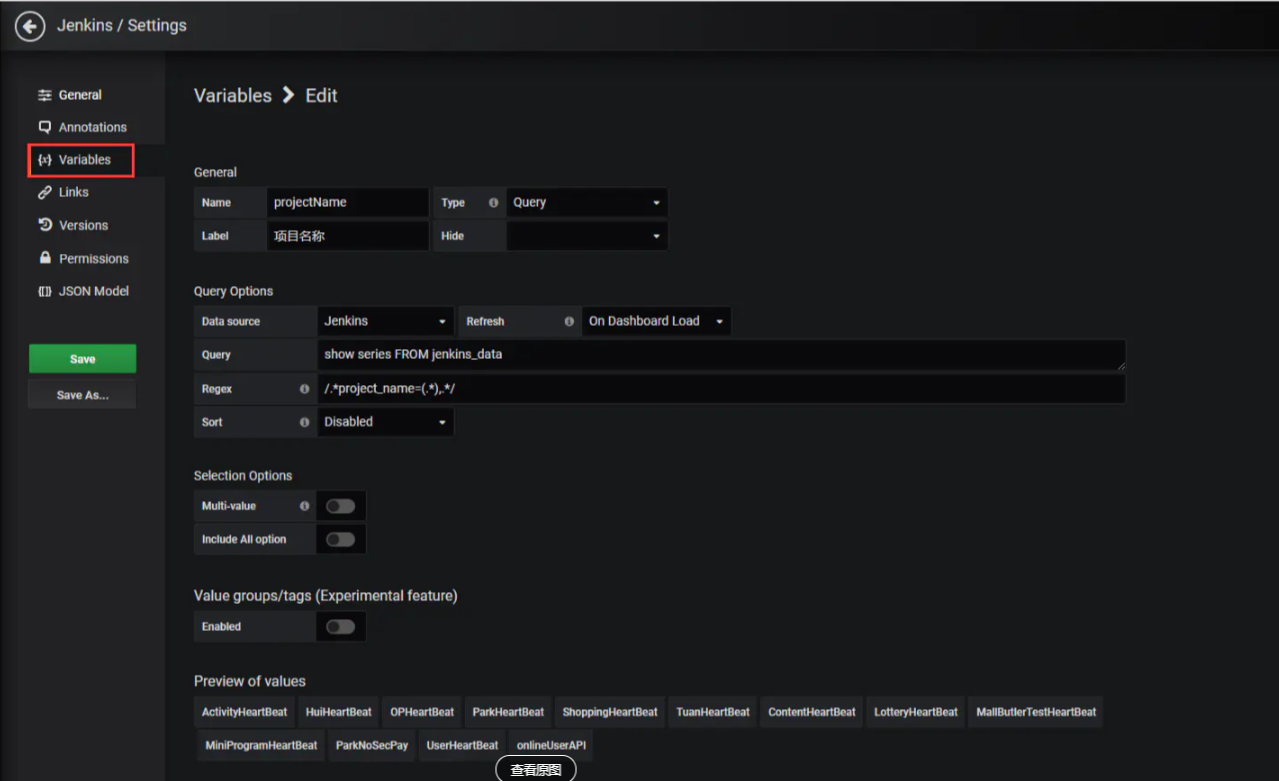
下面就直接参考别人的博客了https://www.jianshu.com/p/06b0da4737fd,grafana没有系统的学一下,配置有点一头雾水
保存完成后,在Dashboard页面,会发现多了一个名为"项目名称"的筛选项:
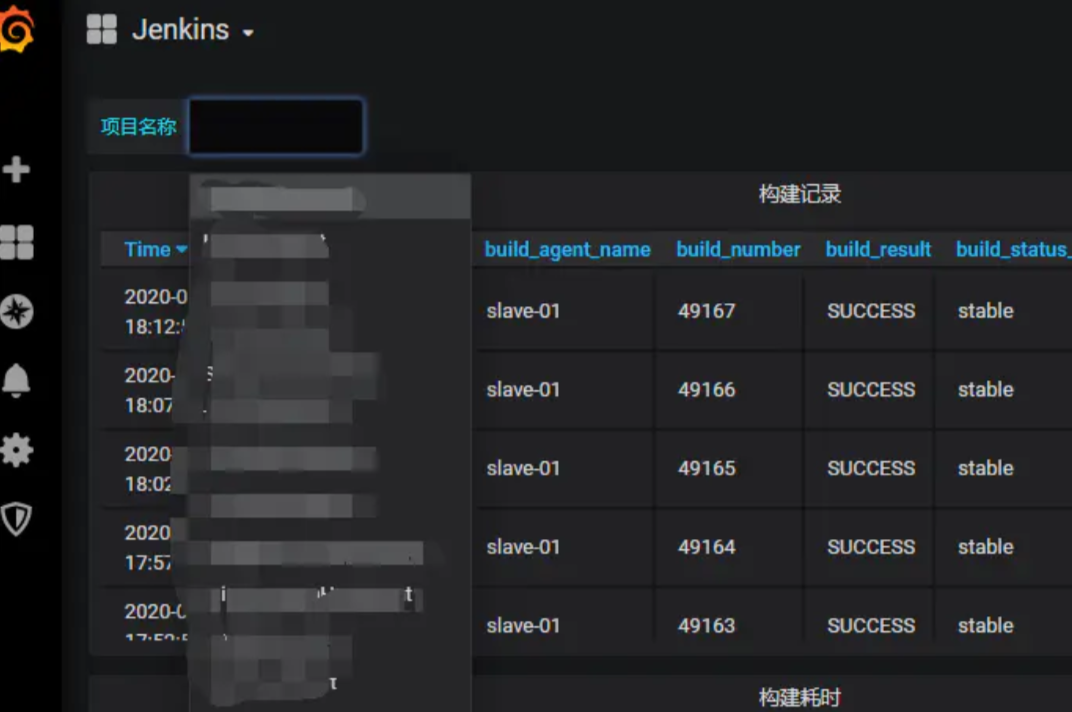
后续配置Panel时,在InfluxQL中可以通过$projectName的方式使用这个自定义的变量。
**Add Panel **
下面是一些我用到视图类型以及对应的InlfuxQL,Visualization配置可以按照喜欢自行调整。
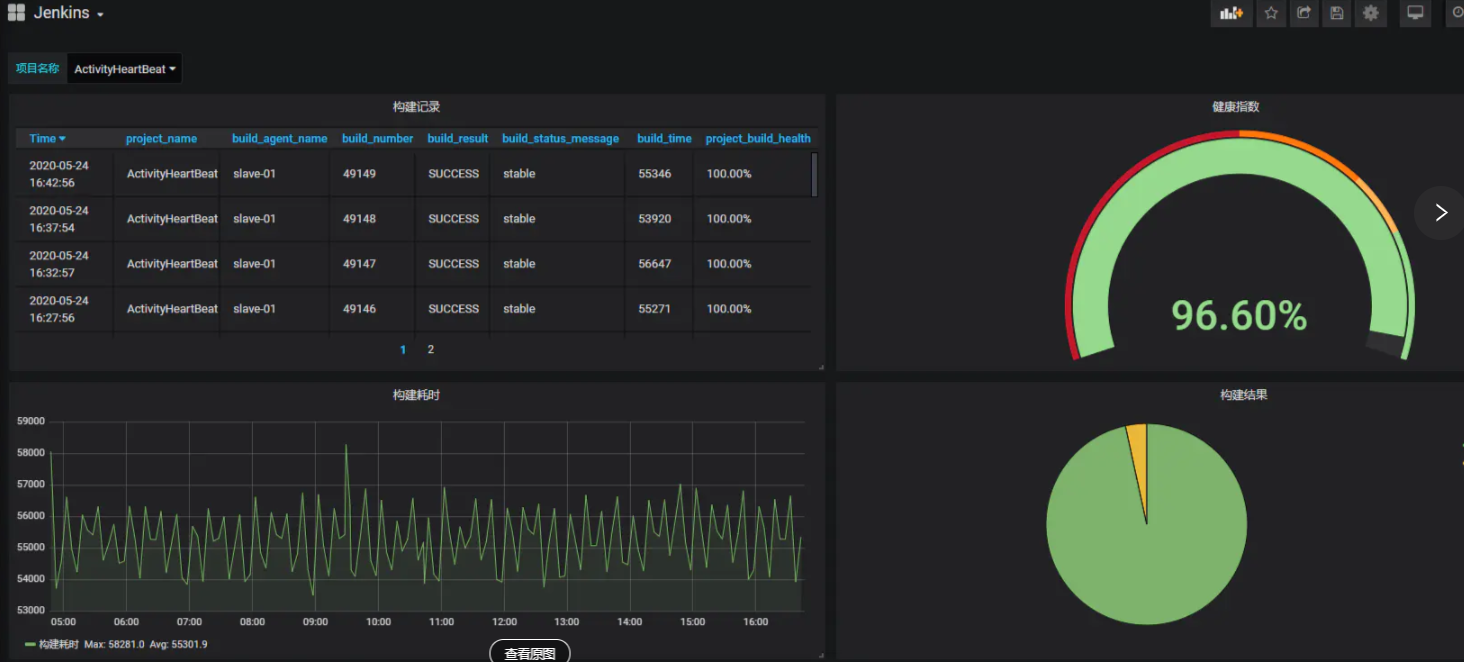
- Pie Chart
# Title构建成功
SELECT count("build_result") FROM jenkins_data WHERE ("build_result" = 'SUCCESS' AND "project_path" =~ /^$projectName$/) AND $timeFilter GROUP BY time($__interval) fill(null)
# Title 构建成功
SELECT count("build_result") FROM jenkins_data WHERE ("build_result" = 'FAILURE' AND "project_path" =~ /^$projectName$/) AND $timeFilter GROUP BY time($__interval) fill(null)
- Graph
# Title 构建耗时
SELECT "build_time" FROM "jenkins_data" WHERE ("project_path" =~ /^$projectName$/) AND $timeFilter ORDER BY time DESC tz('Asia/Shanghai')
- Gauge
# Title 健康指数
SELECT project_build_health FROM jenkins_data WHERE ("project_path" =~ /^$projectName$/) AND $timeFilter
- Table
# Title 构建记录
SELECT "build_agent_name", "build_number", "build_result", "build_status_message", "build_time", "project_build_health" FROM "jenkins_data" WHERE ("project_path" =~ /^$projectName$/) AND $timeFilter GROUP BY "project_name" ORDER BY time DESC
成功的图: