一.Spark内核架构
1、Application
2、spark-submit
3、Driver
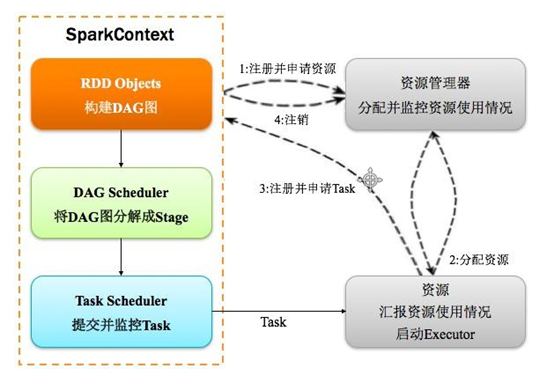
4、SparkContext
5、Master
6、Worker
7、Executor
8、Job
9、DAGScheduler
10、TaskScheduler
11、ShuffleMapTask and ResultTask
任务调度流程图
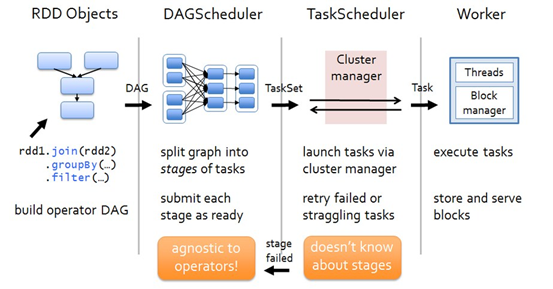
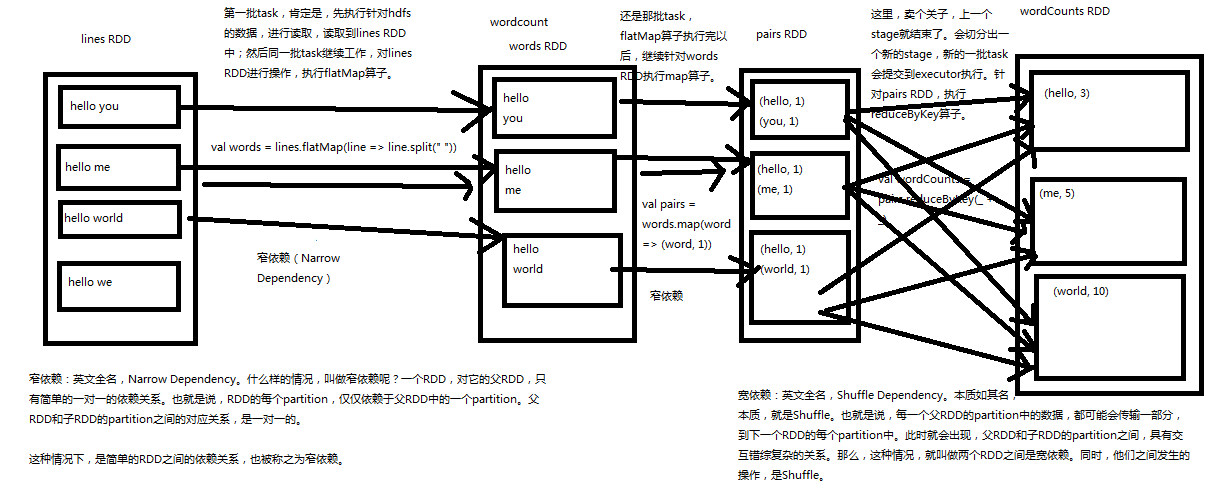
各个RDD之间存在着依赖关系,这些依赖关系就形成有向无环图DAG,DAGScheduler对这些依赖关系形成的DAG进行Stage划分,划分的规则很简单,从后往前回溯,遇到窄依赖加入本stage,遇见宽依赖进行Stage切分。完成了Stage的划分。DAGScheduler基于每个Stage生成TaskSet,并将TaskSet提交给TaskScheduler。TaskScheduler 负责具体的task调度,最后在Worker节点上启动task。
DAGScheduler
(1)DAGScheduler对DAG有向无环图进行Stage划分。
(2)记录哪个RDD或者 Stage 输出被物化(缓存),通常在一个复杂的shuffle之后,通常物化一下(cache、persist),方便之后的计算。
(3)重新提交shuffle输出丢失的stage(stage内部计算出错)给TaskScheduler
(4)将 Taskset 传给底层调度器
a)– spark-cluster TaskScheduler
b)– yarn-cluster YarnClusterScheduler
c)– yarn-client YarnClientClusterScheduler
TaskScheduler
(1)为每一个TaskSet构建一个TaskSetManager 实例管理这个TaskSet 的生命周期
(2)数据本地性决定每个Task最佳位置
(3)提交 taskset( 一组task) 到集群运行并监控
(4)推测执行,碰到计算缓慢任务需要放到别的节点上重试
(5)重新提交Shuffle输出丢失的Stage给DAGScheduler
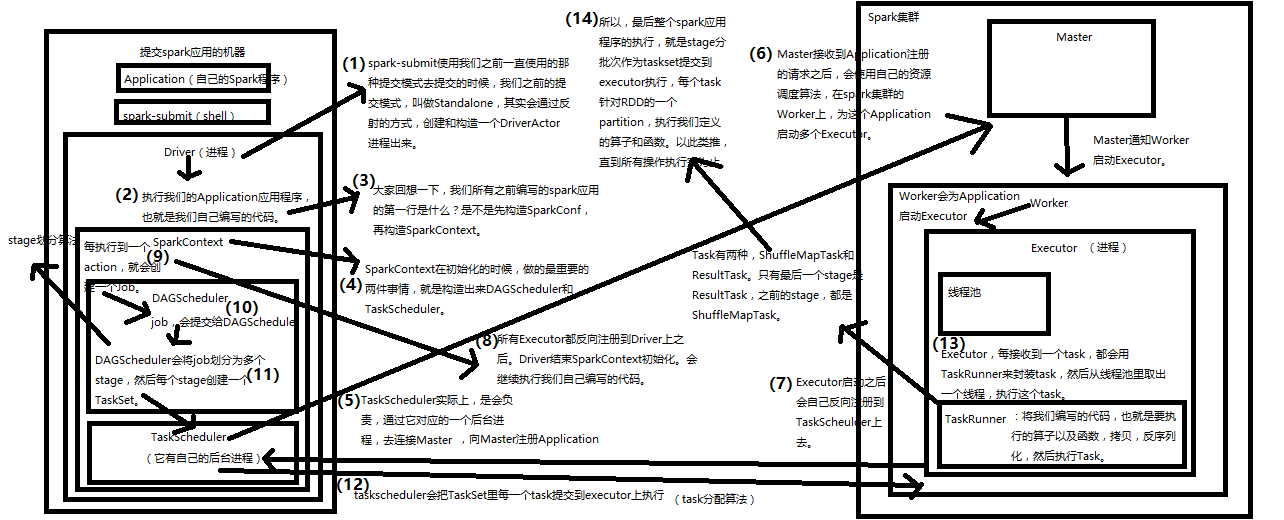
Spark运行基本流程
Spark运行基本流程参见下面示意图:
1) 构建Spark Application的运行环境(启动SparkContext),SparkContext向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源;
2) 资源管理器分配Executor资源并启动Executor,Executor运行情况将随着心跳发送到资源管理器上;
3) SparkContext构建成DAG图,将DAG图分解成Stage,并把Taskset发送给Task Scheduler。Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor。
4) Task在Executor上运行,运行完毕释放所有资源。
Spark运行架构特点
Spark运行架构特点:
1. 每个Application获取专属的executor进程,该进程在Application期间一直驻留,并以多线程方式运行tasks。
2.Spark任务与资源管理器无关,只要能够获取executor进程,并能保持相互通信就可以了。
3.提交SparkContext的Client应该靠近Worker节点(运行Executor的节点),最好是在同一个Rack里,因为Spark程序运行过程中SparkContext和Executor之间有大量的信息交换;如果想在远程集群中运行,最好使用RPC将SparkContext提交给集群,不要远离Worker运行SparkContext。
4. Task采用了数据本地性和推测执行的优化机制。
Spark内核工作流程详细图解
二.宽依赖与窄依赖深度剖析
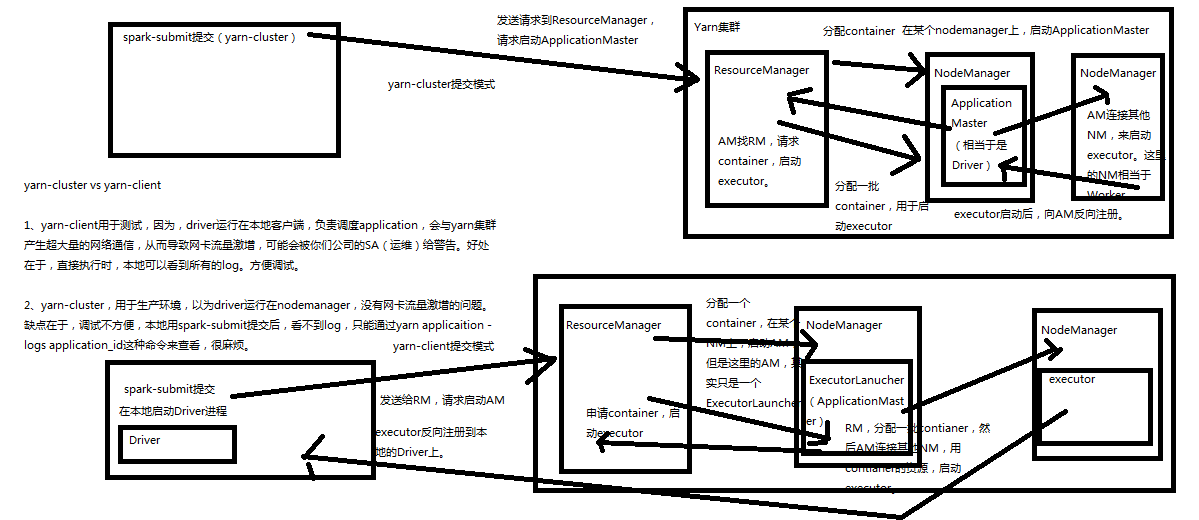
三.基于Yarn的两种提交模式
Spark的三种提交模式
1、Spark内核架构,其实就是第一种模式,standalone模式,基于Spark自己的Master-Worker集群。
2、第二种,是基于YARN的yarn-cluster模式。
3、第三种,是基于YARN的yarn-client模式。
4、如果,你要切换到第二种和第三种模式,很简单,将我们之前用于提交spark应用程序的spark-submit脚本,加上--master参数,设置为yarn-cluster,或yarn-client,即可。如果你没设置,那么,就是standalone模式。
基于YARN的两种提交模式深度剖析