一.倒排索引组成结构以及其索引可变原因
倒排索引,是适合用于进行搜索的
1.倒排索引的结构
(1)包含这个关键词的document list
(2)包含这个关键词的所有document的数量:IDF(inverse document frequency)
(3)这个关键词在每个document中出现的次数:TF(term frequency)
(4)这个关键词在这个document中的次序
(5)每个document的长度:length norm
(6)包含这个关键词的所有document的平均长度
word doc1 doc2
dog * *
hello *
you *
2.倒排索引不可变的好处
(1)不需要锁,提升并发能力,避免锁的问题
(2)数据不变,一直保存在os cache中,只要cache内存足够
(3)filter cache一直驻留在内存,因为数据不变
(4)可以压缩,节省cpu和io开销
倒排索引不可变的坏处:每次都要重新构建整个索引
二.剖析document写入原理(buffer,segment,commit)
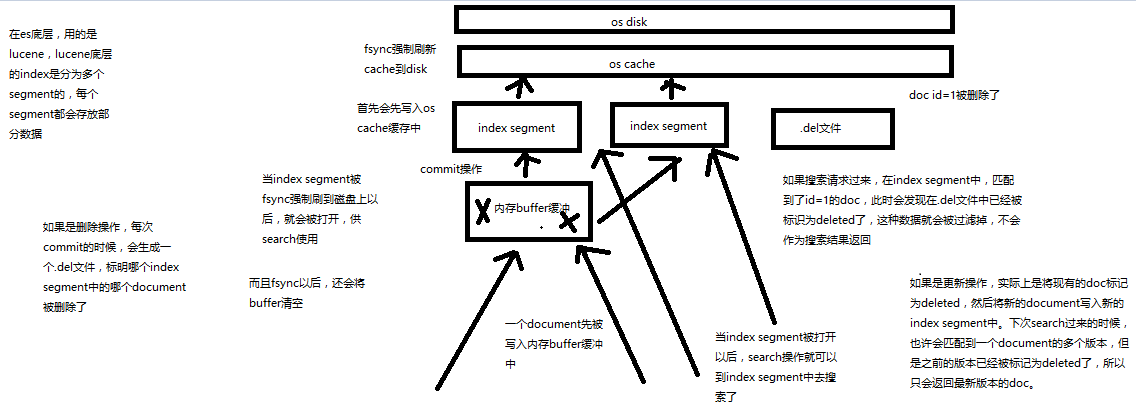
(1)数据写入buffer
(2)commit point
(3)buffer中的数据写入新的index segment
(4)等待在os cache中的index segment被fsync强制刷到磁盘上
(5)新的index sgement被打开,供search使用
(6)buffer被清空
每次commit point时,会有一个.del文件,标记了哪些segment中的哪些document被标记为deleted了
搜索的时候,会依次查询所有的segment,从旧的到新的,比如被修改过的document,在旧的segment中,会标记为deleted,在新的segment中会有其新的数据
三.优化写入流程实现NRT近实时(filesystem cache,refresh)
现有流程的问题,每次都必须等待fsync将segment刷入磁盘,才能将segment打开供search使用,这样的话,从一个document写入,到它可以被搜索,可能会超过1分钟!!!这就不是近实时的搜索了!!!主要瓶颈在于fsync实际发生磁盘IO写数据进磁盘,是很耗时的。
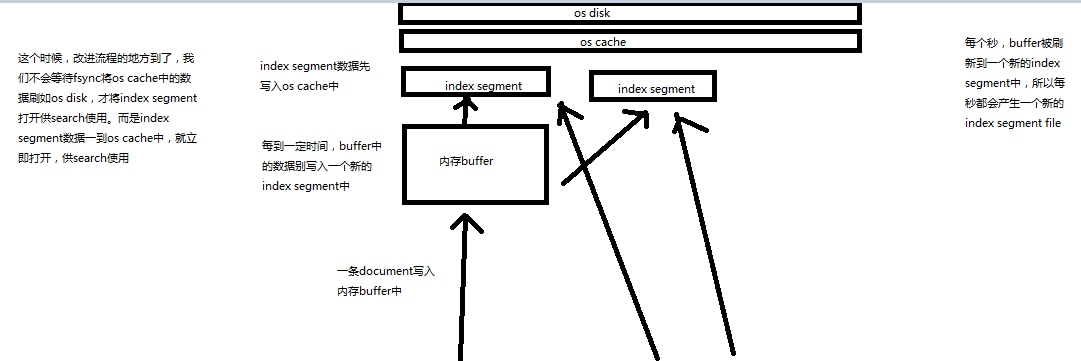
写入流程别改进如下:
(1)数据写入buffer
(2)每隔一定时间,buffer中的数据被写入segment文件,但是先写入os cache
(3)只要segment写入os cache,那就直接打开供search使用,不立即执行commit
数据写入os cache,并被打开供搜索的过程,叫做refresh,默认是每隔1秒refresh一次。也就是说,每隔一秒就会将buffer中的数据写入一个新的index segment file,先写入os cache中。所以,es是近实时的,数据写入到可以被搜索,默认是1秒。
POST /my_index/_refresh,可以手动refresh,一般不需要手动执行,没必要,让es自己搞就可以了
比如说,我们现在的时效性要求,比较低,只要求一条数据写入es,一分钟以后才让我们搜索到就可以了,那么就可以调整refresh interval
PUT /my_index
{
"settings": {
"refresh_interval": "30s"
}
}
四.继续优化写入流程实现durability可靠存储(translog,flush)
1.再次优化的写入流程
(1)数据写入buffer缓冲和translog日志文件
(2)每隔一秒钟,buffer中的数据被写入新的segment file,并进入os cache,此时segment被打开并供search使用
(3)buffer被清空
(4)重复1~3,新的segment不断添加,buffer不断被清空,而translog中的数据不断累加
(5)当translog长度达到一定程度的时候,commit操作发生
(5-1)buffer中的所有数据写入一个新的segment,并写入os cache,打开供使用
(5-2)buffer被清空
(5-3)一个commit ponit被写入磁盘,标明了所有的index segment
(5-4)filesystem cache中的所有index segment file缓存数据,被fsync强行刷到磁盘上
(5-5)现有的translog被清空,创建一个新的translog

五.基于translog和commit point,如何进行数据恢复
fsync+清空translog,就是flush,默认每隔30分钟flush一次,或者当translog过大的时候,也会flush
POST /my_index/_flush,一般来说别手动flush,让它自动执行就可以了
translog,每隔5秒被fsync一次到磁盘上。在一次增删改操作之后,当fsync在primary shard和replica shard都成功之后,那次增删改操作才会成功
但是这种在一次增删改时强行fsync translog可能会导致部分操作比较耗时,也可以允许部分数据丢失,设置异步fsync translog
PUT /my_index/_settings
{
"index.translog.durability": "async",
"index.translog.sync_interval": "5s"
}

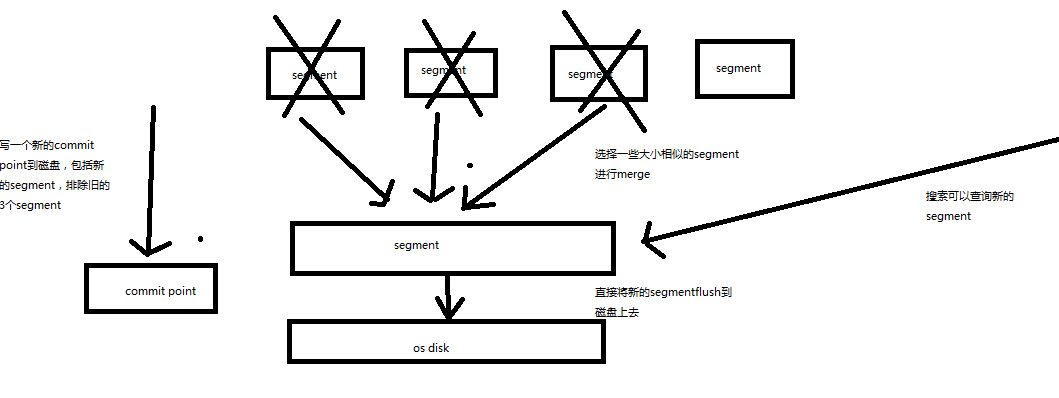
六.最后优化写入流程实现海量磁盘文件合并(segment merge,optimize)
每秒一个segment file,文件过多,而且每次search都要搜索所有的segment,很耗时
默认会在后台执行segment merge操作,在merge的时候,被标记为deleted的document也会被彻底物理删除
每次merge操作的执行流程
(1)选择一些有相似大小的segment,merge成一个大的segment
(2)将新的segment flush到磁盘上去
(3)写一个新的commit point,包括了新的segment,并且排除旧的那些segment
(4)将新的segment打开供搜索
(5)将旧的segment删除
POST /my_index/_optimize?max_num_segments=1,尽量不要手动执行,让它自动默认执行就可以了