目标1:掌握Spark SQL原理
目标2:掌握DataFrame/DataSet数据结构和使用方式
目标3:熟练使用Spark SQL完成计算任务
1. Spark SQL概述
1.1. Spark SQL的前世今生
Shark是一个为Spark设计的大规模数据仓库系统,它与Hive兼容。Shark建立在Hive的代码基础上,并通过将Hive的部分物理执行计划交换出来。这个方法使得Shark的用户可以加速Hive的查询,但是Shark继承了Hive的大且复杂的代码使得Shark很难优化和维护,同时Shark依赖于Spark的版本。随着我们遇到了性能优化的上限,以及集成SQL的一些复杂的分析功能,我们发现Hive的MapReduce设计的框架限制了Shark的发展。在2014年7月1日的Spark Summit上,Databricks宣布终止对Shark的开发,将重点放到Spark SQL上。
1.2. 什么是Spark SQL
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用。
相比于Spark RDD API,Spark SQL包含了对结构化数据和在其上运算的更多信息,Spark SQL使用这些信息进行了额外的优化,使对结构化数据的操作更加高效和方便。
有多种方式去使用Spark SQL,包括SQL、DataFrames API和Datasets API。但无论是哪种API或者是编程语言,它们都是基于同样的执行引擎,因此你可以在不同的API之间随意切换,它们各有各的特点,看你喜欢那种风格。
1.3. 为什么要学习Spark SQL
我们已经学习了Hive,它是将Hive SQL转换成MapReduce然后提交到集群中去执行,大大简化了编写MapReduce程序的复杂性,由于MapReduce这种计算模型执行效率比较慢,所以Spark SQL应运而生,它是将Spark SQL转换成RDD,然后提交到集群中去运行,执行效率非常快!
1.易整合
将sql查询与spark程序无缝混合,可以使用java、scala、python、R等语言的API操作。
2.统一的数据访问

以相同的方式连接到任何数据源。
3.兼容Hive
支持hiveSQL的语法。
4.标准的数据连接

可以使用行业标准的JDBC或ODBC连接。
2. DataFrame
2.1. 什么是DataFrame
DataFrame的前身是SchemaRDD,从Spark 1.3.0开始SchemaRDD更名为DataFrame。与SchemaRDD的主要区别是:DataFrame不再直接继承自RDD,而是自己实现了RDD的绝大多数功能。你仍旧可以在DataFrame上调用rdd方法将其转换为一个RDD。
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库的二维表格,DataFrame带有Schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型,但底层做了更多的优化。DataFrame可以从很多数据源构建,比如:已经存在的RDD、结构化文件、外部数据库、Hive表。
2.2. DataFrame与RDD的区别
RDD可看作是分布式的对象的集合,Spark并不知道对象的详细模式信息,DataFrame可看作是分布式的Row对象的集合,其提供了由列组成的详细模式信息(就是列的名称和类型),使得Spark SQL可以进行某些形式的执行优化。DataFrame和普通的RDD的逻辑框架区别如下所示:
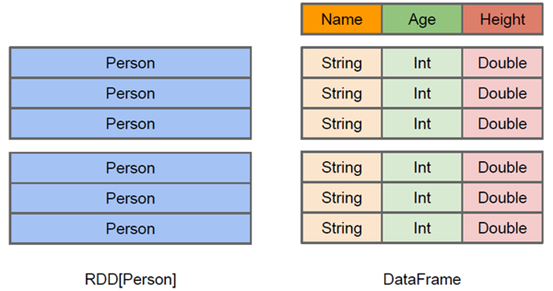
上图直观地体现了DataFrame和RDD的区别。
左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解 Person类的内部结构。
而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么,DataFrame多了数据的结构信息,即schema。这样看起来就像一张表了,DataFrame还配套了新的操作数据的方法,DataFrame API(如df.select())和SQL(select id, name from xx_table where ...)。
此外DataFrame还引入了off-heap,意味着JVM堆以外的内存, 这些内存直接受操作系统管理(而不是JVM)。Spark能够以二进制的形式序列化数据(不包括结构)到off-heap中, 当要操作数据时, 就直接操作off-heap内存. 由于Spark理解schema, 所以知道该如何操作。
RDD是分布式的Java对象的集合。DataFrame是分布式的Row对象的集合。DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效
率、减少数据读取以及执行计划的优化。
有了DataFrame这个高一层的抽象后,我们处理数据更加简单了,甚至可以用SQL来处理数据了,对开发者来说,易用性有了很大的提升。
不仅如此,通过DataFrame API或SQL处理数据,会自动经过Spark 优化器(Catalyst)的优化,即使你写的程序或SQL不高效,也可以运行的很快。
2.3. DataFrame与RDD的优缺点
2.3.1RDD的优缺点:
优点:
(1)编译时类型安全
编译时就能检查出类型错误
(2)面向对象的编程风格
直接通过对象调用方法的形式来操作数据
缺点:
(1)序列化和反序列化的性能开销
无论是集群间的通信, 还是IO操作都需要对对象的结构和数据进行序列化和反序列化。
(2)GC的性能开销
频繁的创建和销毁对象,
势必会增加GC
2.3.2DataFrame的优缺点:
优点:
DataFrame通过引入schema和off-heap(不在堆里面的内存,指的是除了不在堆的内存,使用操作系统上的内存),解决了RDD的缺点, Spark通过schame就能够读懂数据, 因此在通信和IO时就只需要序列化和反序列化数据, 而结构的部分就可以省略了;
缺点:
通过off-heap引入,可以快速的操作数据,避免大量的GC。但是却丢了RDD的优点,DataFrame不是类型安全的, API也不是面向对象风格的。
3.RDD、DataFrame、DataSet区别
在spark中,RDD、DataFrame、Dataset是最常用的数据类型,本博文给出笔者在使用的过程中体会到的区别和各自的优势
3.1共性:
1、RDD、DataFrame、Dataset全都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利
2、三者都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action如foreach时,三者才会开始遍历运算,极端情况下,如果代码里面有创建、转换,但是后面没有在Action中使用对应的结果,在执行时会被直接跳过,如
|
1 2 3 4 5 6 7 8 |
val sparkconf = new SparkConf().setMaster("local").setAppName("test").set("spark.port.maxRetries","1000") val spark = SparkSession.builder().config(sparkconf).getOrCreate() val rdd=spark.sparkContext.parallelize(Seq(("a", 1), ("b", 1), ("a", 1)))
rdd.map{line=> println("运行") line._1 } |
map中的println("运行")并不会运行
3、三者都会根据spark的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出
4、三者都有partition的概念,如
|
1 2 3 4 5 6 7 8 |
var predata=data.repartition(24).mapPartitions{ PartLine => { PartLine.map{ line => println(“转换操作”) } } } |
这样对每一个分区进行操作时,就跟在操作数组一样,不但数据量比较小,而且可以方便的将map中的运算结果拿出来,如果直接用map,map中对外面的操作是无效的,如
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
val rdd=spark.sparkContext.parallelize(Seq(("a", 1), ("b", 1), ("a", 1))) var flag=0 val test=rdd.map{line=> println("运行") flag+=1 println(flag) line._1 } println(test.count) println(flag) /** 运行 1 运行 2 运行 3 3 0 * */ |
不使用partition时,对map之外的操作无法对map之外的变量造成影响
5、三者有许多共同的函数,如filter,排序等
6、在对DataFrame和Dataset进行操作许多操作都需要这个包进行支持
|
1 2 |
import spark.implicits._ //这里的spark是SparkSession的变量名 |
7、DataFrame和Dataset均可使用模式匹配获取各个字段的值和类型
DataFrame:
|
1 2 3 4 5 6 7 |
testDF.map{ case Row(col1:String,col2:Int)=> println(col1);println(col2) col1 case _=> "" } |
为了提高稳健性,最好后面有一个_通配操作,这里提供了DataFrame一个解析字段的方法
Dataset:
|
1 2 3 4 5 6 7 8 |
case class Coltest(col1:String,col2:Int)extends Serializable //定义字段名和类型 testDS.map{ case Coltest(col1:String,col2:Int)=> println(col1);println(col2) col1 case _=> "" } |
3.2区别:
RDD:
1、RDD一般和spark mlib同时使用
2、RDD不支持sparksql操作
DataFrame:
1、与RDD和Dataset不同,DataFrame每一行的类型固定为Row,只有通过解析才能获取各个字段的值,如
|
1 2 3 4 5 |
testDF.foreach{ line => val col1=line.getAs[String]("col1") val col2=line.getAs[String]("col2") } |
每一列的值没法直接访问
2、DataFrame与Dataset一般与spark ml同时使用
3、DataFrame与Dataset均支持sparksql的操作,比如select,groupby之类,还能注册临时表/视窗,进行sql语句操作,如
|
1 2 |
dataDF.createOrReplaceTempView("tmp") spark.sql("select ROW,DATE from tmp where DATE is not null order by DATE").show(100,false) |
4、DataFrame与Dataset支持一些特别方便的保存方式,比如保存成csv,可以带上表头,这样每一列的字段名一目了然
|
1 2 3 4 5 6 |
//保存 val saveoptions = Map("header" -> "true", "delimiter" -> " ", "path" -> "hdfs://172.xx.xx.xx:9000/test") datawDF.write.format("com.databricks.spark.csv").mode(SaveMode.Overwrite).options(saveoptions).save() //读取 val options = Map("header" -> "true", "delimiter" -> " ", "path" -> "hdfs://172.xx.xx.xx:9000/test") val datarDF= spark.read.options(options).format("com.databricks.spark.csv").load() |
利用这样的保存方式,可以方便的获得字段名和列的对应,而且分隔符(delimiter)可以自由指定
Dataset:
这里主要对比Dataset和DataFrame,因为Dataset和DataFrame拥有完全相同的成员函数,区别只是每一行的数据类型不同
DataFrame也可以叫Dataset[Row],每一行的类型是Row,不解析,每一行究竟有哪些字段,各个字段又是什么类型都无从得知,只能用上面提到的getAS方法或者共性中的第七条提到的模式匹配拿出特定字段
而Dataset中,每一行是什么类型是不一定的,在自定义了case class之后可以很自由的获得每一行的信息
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
case class Coltest(col1:String,col2:Int)extends Serializable //定义字段名和类型 /** rdd ("a", 1) ("b", 1) ("a", 1) * */ val test: Dataset[Coltest]=rdd.map{line=> Coltest(line._1,line._2) }.toDS test.map{ line=> println(line.col1) println(line.col2) } |
可以看出,Dataset在需要访问列中的某个字段时是非常方便的,然而,如果要写一些适配性很强的函数时,如果使用Dataset,行的类型又不确定,可能是各种case class,无法实现适配,这时候用DataFrame即Dataset[Row]就能比较好的解决问题
3.3转化:
RDD、DataFrame、Dataset三者有许多共性,有各自适用的场景常常需要在三者之间转换
DataFrame/Dataset转RDD:
这个转换很简单
|
1 2 |
val rdd1=testDF.rdd val rdd2=testDS.rdd |
RDD转DataFrame:
|
1 2 3 4 |
import spark.implicits._ val testDF = rdd.map {line=> (line._1,line._2) }.toDF("col1","col2") |
一般用元组把一行的数据写在一起,然后在toDF中指定字段名
RDD转Dataset:
|
1 2 3 4 5 |
import spark.implicits._ case class Coltest(col1:String,col2:Int)extends Serializable //定义字段名和类型 val testDS = rdd.map {line=> Coltest(line._1,line._2) }.toDS |
可以注意到,定义每一行的类型(case class)时,已经给出了字段名和类型,后面只要往case class里面添加值即可
Dataset转DataFrame:
这个也很简单,因为只是把case class封装成Row
|
1 2 |
import spark.implicits._ val testDF = testDS.toDF |
DataFrame转Dataset:
|
1 2 3 |
import spark.implicits._ case class Coltest(col1:String,col2:Int)extends Serializable //定义字段名和类型 val testDS = testDF.as[Coltest] |
这种方法就是在给出每一列的类型后,使用as方法,转成Dataset,这在数据类型是DataFrame又需要针对各个字段处理时极为方便
特别注意:
在使用一些特殊的操作时,一定要加上 import spark.implicits._ 不然toDF、toDS无法使用
4. 读取数据源创建DataFrame
4.1 读取文本文件创建DataFrame
在spark2.0版本之前,Spark SQL中SQLContext是创建DataFrame和执行SQL的入口,可以利用hiveContext通过hive sql语句操作hive表数据,兼容hive操作,并且hiveContext继承自SQLContext。在spark2.0之后,这些都统一于SparkSession,SparkSession 封装了 SparkContext,SqlContext,通过SparkSession可以获取到SparkConetxt,SqlContext对象。
(1)在本地创建一个文件,有三列,分别是id、name、age,用空格分隔,然后上传到hdfs上。person.txt内容为:
|
1 zhangsan 20 2 lisi 29 3 wangwu 25 4 zhaoliu 30 5 tianqi 35 6 kobe 40 |
上传数据文件到HDFS上:
hdfs dfs -put person.txt /
先执行 spark-shell --master local[2]
(2)在spark shell执行下面命令,读取数据,将每一行的数据使用列分隔符分割
val lineRDD= sc.textFile("/person.txt").map(_.split(" "))

(3)定义case class(相当于表的schema)
case class Person(id:Int, name:String, age:Int)

(4)将RDD和case class关联
val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))

(5)将RDD转换成DataFrame
val personDF = personRDD.toDF

(6)对DataFrame进行处理
personDF.show

personDF.printSchema

(7)不使用样例类构建DF,自定义schema
scala> val peopleDF = sc.textFile("/people.txt").map(_.split(" ")).map(x=>(x(0),x(1),x(2))).toDF("id","name","age")
peopleDF: org.apache.spark.sql.DataFrame = [id: string, name: string ... 1 more field]
(8)通过SparkSession构建DataFrame
使用spark-shell中已经初始化好的SparkSession对象spark生成DataFrame
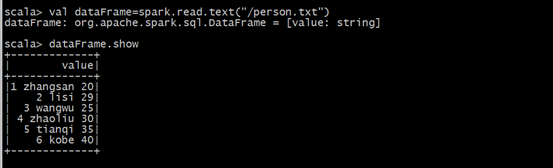
val dataFrame=spark.read.text("/person.txt")
4.2 读取json文件创建DataFrame
(1)数据文件
使用spark安装包下的
/opt/bigdata/spark/examples/src/main/resources/people.json文件
(2)在spark shell执行下面命令,读取数据
val jsonDF= spark.read.json("file:///opt/bigdata/spark/examples/src/main/resources/people.json")

(3)接下来就可以使用DataFrame的函数操作


4.3 读取parquet列式存储格式文件创建DataFrame
(1)数据文件
使用spark安装包下的
/opt/bigdata/spark/examples/src/main/resources/users.parquet文件
(2)在spark shell执行下面命令,读取数据
val parquetDF=spark.read.parquet("file:///opt/bigdata/spark/examples/src/main/resources/users.parquet")

(3)接下来就可以使用DataFrame的函数操作


5.DataSet
5.1. 什么是DataSet
DataSet是分布式的数据集合,Dataset提供了强类型支持,也是在RDD的每行数据加了类型约束。DataSet是在Spark1.6中添加的新的接口。它集中了RDD的优点(强类型和可以用强大lambda函数)以及使用了Spark SQL优化的执行引擎。DataSet可以通过JVM的对象进行构建,可以用函数式的转换(map/flatmap/filter)进行多种操作。
5.2. DataFrame、DataSet、RDD的区别
假设RDD中的两行数据长这样:

那么DataFrame中的数据长这样:

那么Dataset中的数据长这样:
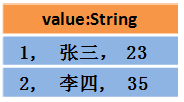
或者长这样(每行数据是个Object):

DataSet包含了DataFrame的功能,Spark2.0中两者统一,DataFrame表示为DataSet[Row],即DataSet的子集。
(1)DataSet可以在编译时检查类型
(2)并且是面向对象的编程接口
相比DataFrame,Dataset提供了编译时类型检查,对于分布式程序来讲,提交一次作业太费劲了(要编译、打包、上传、运行),到提交到集群运行时才发现错误,这会浪费大量的时间,这也是引入Dataset的一个重要原因。
5.3. DataFrame与DataSet互相转换
DataFrame和DataSet可以相互转化。
(1)DataFrame转为 DataSet
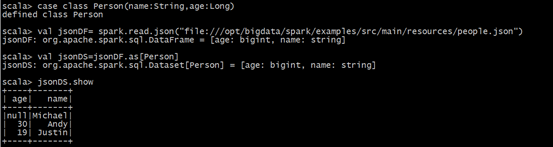
df.as[ElementType] 这样可以把DataFrame转化为DataSet。
(2)DataSet转为DataFrame
ds.toDF() 这样可以把DataSet转化为DataFrame。
5.4. 创建DataSet
(1)通过spark.createDataset创建


(2)通toDS方法生成DataSet
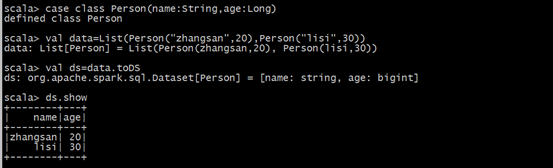
(3)通过DataFrame转化生成
使用as[类型]转换为DataSet