AC自动机算法
AC自动机简介:
首先简要介绍一下AC自动机:Aho-Corasick automation,该算法在1975年产生于贝尔实验室,是著名的多模匹配算法之一。一个常见的例子就是给出n个单词,再给出一段包含m个字符的文章,让你找出有多少个单词在文章里出现过。要搞懂AC自动机,先得有字典树Trie和KMP模式匹配算法的基础知识。KMP算法是单模式串的字符匹配算法,AC自动机是多模式串的字符匹配算法。
AC自动机的构造:
1.构造一棵Trie,作为AC自动机的搜索数据结构。
2.构造fail指针,使当前字符失配时跳转到具有最长公共前后缀的字符继续匹配。如同 KMP算法一样, AC自动机在匹配时如果当前字符匹配失败,那么利用fail指针进行跳转。由此可知如果跳转,跳转后的串的前缀,必为跳转前的模式串的后缀并且跳转的新位置的深度(匹配字符个数)一定小于跳之前的节点。所以我们可以利用 bfs在 Trie上面进行 fail指针的求解。
3.扫描主串进行匹配。
AC自动机详讲:
我们给出5个单词,say,she,shr,he,her。给定字符串为yasherhs。问多少个单词在字符串中出现过。
一、Trie
首先我们需要建立一棵Trie。但是这棵Trie不是普通的Trie,而是带有一些特殊的性质。
首先会有3个重要的指针,分别为p, p->fail, temp。
1.指针p,指向当前匹配的字符。若p指向root,表示当前匹配的字符序列为空。(root是Trie入口,没有实际含义)。
2.指针p->fail,p的失败指针,指向与字符p相同的结点,若没有,则指向root。
3.指针temp,测试指针(自己命名的,容易理解!~),在建立fail指针时有寻找与p字符匹配的结点的作用,在扫描时作用最大,也最不好理解。
对于Trie树中的一个节点,对应一个序列s[1...m]。此时,p指向字符s[m]。若在下一个字符处失配,即p->next[s[m+1]] == NULL,则由失配指针跳到另一个节点(p->fail)处,该节点对应的序列为s[i...m]。若继续失配,则序列依次跳转直到序列为空或出现匹配。在此过程中,p的值一直在变化,但是p对应节点的字符没有发生变化。在此过程中,我们观察可知,最终求得得序列s则为最长公共后缀。另外,由于这个序列是从root开始到某一节点,则说明这个序列有可能是某些序列的前缀。
再次讨论p指针转移的意义。如果p指针在某一字符s[m+1]处失配(即p->next[s[m+1]] == NULL),则说明没有单词s[1...m+1]存在。此时,如果p的失配指针指向root,则说明当前序列的任意后缀不会是某个单词的前缀。如果p的失配指针不指向root,则说明序列s[i...m]是某一单词的前缀,于是跳转到p的失配指针,以s[i...m]为前缀继续匹配s[m+1]。
对于已经得到的序列s[1...m],由于s[i...m]可能是某单词的后缀,s[1...j]可能是某单词的前缀,所以s[1...m]中可能会出现单词。此时,p指向已匹配的字符,不能动。于是,令temp = p,然后依次测试s[1...m], s[i...m]是否是单词。
构造的Trie为:
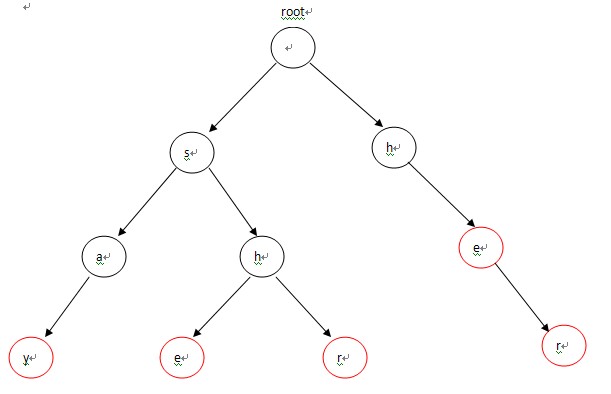
二、构造失败指针
用BFS来构造失败指针,与KMP算法相似的思想。
首先,root入队,第1次循环时处理与root相连的字符,也就是各个单词的第一个字符h和s,因为第一个字符不匹配需要重新匹配,所以第一个字符都指向root(root是Trie入口,没有实际含义)失败指针的指向对应下图中的(1),(2)两条虚线;第2次进入循环后,从队列中先弹出h,接下来p指向h节点的fail指针指向的节点,也就是root;p=p->fail也就是p=NULL说明匹配序列为空,则把节点e的fail指针指向root表示没有匹配序列,对应图-2中的(3),然后节点e进入队列;第3次循环时,弹出的第一个节点a的操作与上一步操作的节点e相同,把a的fail指针指向root,对应图-2中的(4),并入队;第4次进入循环时,弹出节点h(图中左边那个),这时操作略有不同。由于p->next[i]!=NULL(root有h这个儿子节点,图中右边那个),这样便把左边那个h节点的失败指针指向右边那个root的儿子节点h,对应图-2中的(5),然后h入队。以此类推:在循环结束后,所有的失败指针就是图-2中的这种形式。
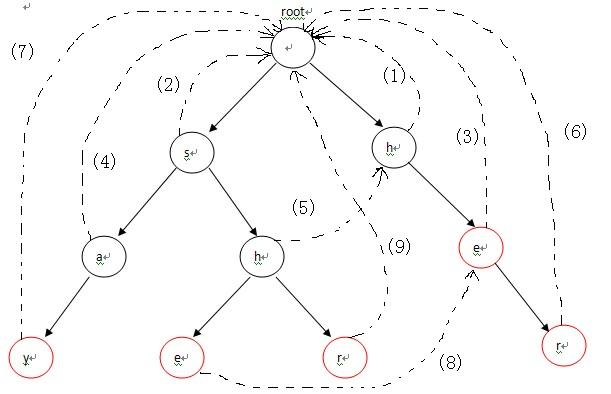
三、扫描
构造好Trie和失败指针后,我们就可以对主串进行扫描了。这个过程和KMP算法很类似,但是也有一定的区别,主要是因为AC自动机处理的是多串模式,需要防止遗漏某个单词,所以引入temp指针。
匹配过程分两种情况:(1)当前字符匹配,表示从当前节点沿着树边有一条路径可以到达目标字符,此时只需沿该路径走向下一个节点继续匹配即可,目标字符串指针移向下个字符继续匹配;(2)当前字符不匹配,则去当前节点失败指针所指向的字符继续匹配,匹配过程随着指针指向root结束。重复这2个过程中的任意一个,直到模式串走到结尾为止。
对照上图,看一下模式匹配这个详细的流程,其中模式串为yasherhs。对于i=0,1。Trie中没有对应的路径,故不做任何操作;i=2,3,4时,指针p走到左下节点e。因为节点e的count信息为1,所以cnt+1,并且讲节点e的count值设置为-1,表示改单词已经出现过了,防止重复计数,最后temp指向e节点的失败指针所指向的节点继续查找,以此类推,最后temp指向root,退出while循环,这个过程中count增加了2。表示找到了2个单词she和he。当i=5时,程序进入第5行,p指向其失败指针的节点,也就是右边那个e节点,随后在第6行指向r节点,r节点的count值为1,从而count+1,循环直到temp指向root为止。最后i=6,7时,找不到任何匹配,匹配过程结束。
AC自动机专辑
一、总概述:
在acm用到的算法中我觉得字符串类算法在实际中的应用价值可能最大,因为我们很多时候在和字符串打交道,在和匹配、查询打交道,比如我们按Ctrl+F的查找,目测有用Kmp匹配算法,linux下的fgrep利用AC自动机实现,还有很多的哈希方法也在各种实际应用中展现它的价值等等。
本文针对AC自动机做个总结,并附带若干题解。
建立AC自动机的一般步骤是:1、初始化根节点,根节点是所有字符串的前缀 2、利用模式串建立字典树(一般将主串叫匹配串,子串或去匹配的串叫模式串) 3、对字典树上的构建fail指针,fail指针指向当前串的最长后缀,这个后缀也是某个串的前缀,和KMP的next指针相似 4、利用构建好的ac自动机或者trie图(ac自动机的所有后继节点拓展之后就是trie图)进行操作,一般有查询、利用trie图建立矩阵、利用trie图进行状态DP等等。
AC自动机(以下trie图也叫AC自动机)的精华是fail指针,上面有颜色的字是对fail指针的阐释,当匹配到p这个节点,如果后继节点失配了,那么总是找当前串的最长后缀也是某串的前缀的的后继节点去匹配,如果还不匹配继续找p->fail的最长后缀的后继结点去匹配,直到遇到能匹配的后继结点或者回溯到根节点重头再来。
在字典树上构建fail指针是通过一个广搜来完成,从根节点开始像洪水般一层层向外构建fail指针,规定根节点的fail指针指向它自己。假设p点fail指针构建好了,q是p的后继结点也就是说q = p->next[k],除根为的所有节点都有q->fail = p->fail->next[k] ,特别的,当p是根时p->next[k]->fail = root,显然根的第k个后继没办法匹配不可能再指向第k个后继,否则就陷入死循环.具体的过程见我的Hdu 2222代码。
再说下如何将ac自动机改造成trie图,其实只需要一步就完成了。当我们匹配到p这个节点,如果它的后继节点失配了,ac自动机的做法是顺着fail指针一步一步回溯直到某点的后继结点匹配之或者到达根节点,而trie图就将这步改成O(1)的做法,最后匹配的那个节点直接赋给p的后继节点p->next[k].因为我们是一层层向外扩散,到达节点p,p->fail的next数组都已经赋好值,可以直接利用..这达到的效果正和fail指针的定义相一致。当我们在trie图上遍历出一条路径的时候,这条路径恰好表示一个串S,当遍历到节点p时,从根节点到p这条路径表示的串s为S的后缀。
另外,我们还可以利用fail指针来方便的查找后缀,当我们反转fail指针后会得到一棵fail树,fail树中父亲节点是儿孙节点的后缀,当我们要查找含某些子串的父串时,利用这种树搭配着线段树或树状数组将十分飘逸,而我们要找当前节点代表的串的所有后缀,就可以从当前点找到根节点,这条路径上的节点在字典树中代表的串都是它的后缀。而字典树中父亲节点时儿孙节点的前缀,这两种树十分相似,所以我猜测fail树也具备很多性质。
二、题目列表:
2、Hdu 3695 Computer Virus on Planet Pandora
19、20...持续更新
三、简单题解
1、普通自动机
模版题,普通的AC自动机照样不超时,但这题的数据太弱,很多人写搓了但是还能ac,最下面我附上本题的代码,并且带一些坑爹数据。
Hdu 3695 Computer Virus on Planet Pandora
题目数据看上去很大,其实不然,用ac自动机可以轻松虐。先用模式串构建ac自动机,然后将主串解析成正常字符串,正反各查询一次就好了。
上题的加强版。但模式串不能出现某串是另一串的子串。本题要用到fa指针和fail指针,一个找当前串前缀一个找后缀,从从当前串的结束节点开始沿着fa指针和fail指针遍历到根节点,这两条路径上的节点到根节点的串便是当前串的子串,然后进行相应地处理即可。详细报告和测试数据见Here.
估计这题是2011年成都区域赛GRE那题的原题,但这题比较简单。题目给定n个字符串,让我们找出若干个字符串组成一个序列,前面一个字符串是后面一个字符串的子串,问我们能获得得最长序列的长度。因为先坐GRE那题,受那题思维束缚,死活要让这题的字符串从短到长,然后顺序就固定了,这样就按照GRE那题的做法,先离线建立ac自动机,然后一步步查询,然后就跪了。其实没要求顺序,本题就变得十分简单,我们要做的是找某个串的匹配部分和fail指针指向的最长后缀,取其中大者作为前序状态进行转移即可。这步在我们构造trie图的时候就可以边构造fail指针边进行转移。
解析字符串,然后建立AC自动机查询之。
2011年成都区域赛的题目,是上题的加强版,先建立ac自动机但不更新节点信息,构建完成之后进行查询、更新。具体报告见Here。
题目给定n个熟悉的串,问长度为m且至少含一个熟悉串的方案数,m<=100万。逆向思维,用总的方案数减去不含熟悉串的方案数。先用ac自动机先求出一个矩阵,mat[i][j]表示从自动机的节点i不经过熟悉串的结尾有几种方法可以走到节点j。然后用mat矩阵进行二分快速幂,幂乘的时候注意尽量少用%mod。
题目给定n个病毒串,问是否存在一个无限循环串都不包含这n个串。这题困扰了我很多天,我在建好AC自动机后尝试过很多解法,比如判断能不能回到根节点、将将两个相同的病毒串拼起来然后做n次插入等等,卡了好几天,不过我觉得这样挺好的,至少我的思维没被束缚。
这题的本质是找到一个环,环上不包含所有的病毒串。正解是先构建AC自动机,改造成trie图,然后在trie图上顺着next数组进行深搜,如果搜到的一个节点在之前搜过,说明出现了环,否则就不存在这样的环。
2、自动机 + DP
给定n个危险DNA序列,再给一段长度长为L的DNA序列S,DNA序列S中可能包含危险DNA序列,可以改变S中的字符,改变一个算一次操作,问最少操作几次可使S不含危险DNA序列,如果怎么操作都会含有危险DNA序列输出-1。
比较简单的AC自动机+DP。状态转移方程:dp[i][j->next[k]] += min(dp[i-1][j] + (S[[i] == k))(dp[i][j]表示在我们构造解的过程中,长度为i且到j位置的最少操作数,不可达值为inf)
一开始我用类似上题的dp解本题,但是TLE了,因为复杂度为O(m*len*total),len是主串长度,total为ac自动机节点总数,最坏的计算量为1920*8000,差不多1536,因为多组数据所以TLE了。再看一遍题目,我了个擦,原来是用空格来替换字符,而空格在模式串中都没出现过,这样用上面的DP就显得很鸡肋。后来YY了一个结论,如果碰到危险节点就滚回根节点,统计滚的次数。空格从未在模式串出现过,可知遇到空格的话就得滚回根节点,这很显然。我YY的结论貌似是按照题意去模拟,那么怎么保证次数最少呢?想想如果一个串还是病毒串,那么在这个串里肯定要替换一次,在最后替换对以当前串为前缀的串影响最大,所以必须选最后的危险节点,这个貌似YY但实则必然。Hnu的discuss里有个讲得比较多貌似比较靠谱的证明,大家可以看看,Here。
这题用贪心过掉之后,就开始搞上题,改成贪心交上去就wa掉了,因为上题必须用ACTG去替换,替换完不一定回到根节点,这是本质的差别,所以不能用那么贪心。
利用这些串建立AC自动机,然后在自动机上DP.dp[i][j][k]表示长度为i在自动机上j位置状态为k是否可达。
状态转移方程:if (dp[i][j][k] == true) dp[i+1][j->next[s]][newk].(实现的时候要用滚动数组,不然MLE).
最后计算每个可达状态中的最大值。
和上题相似,但要难些。因为是重组,考虑将ACGT进行状态压缩,单个A为1,单个C为1 * (num[A] + 1),单个G为(num[C] + 1) * (num[A] + 1),单个T为(num[C] + 1) * (num[A] + 1) * (num[G] + 1).然后在自动机上DP,dp[i][j]表示状态为i时到达位置j的最优值。状态转移方程和具体思路见Here
要求用集合A中的串可重叠地构造出一个串,使得这个串含有最多的B集合中的串。利用B集合的串建立自动机,然后预处理A串哪些串可以重叠相连。设dp[i][j][k]表示长度为i的串匹配到位置j且最后的那个串为集合A中串k的最多含B串数。dp[nl][nj][s] = max(dp[nl][nj][s],dp[i][j][k] + ts),(ts为A中的串s从j位置开始匹配的路径中含有多少B串,nj为最后匹配到的位置).
这题i的复杂度很可怕,O(len*(m*10)*n*n),但运算量其实并不特别大,我的代码100msAC,名列第二.
3、自动机+矩阵
我们从反方向来想,计算都不含病毒串的方案数,然后用总方案数减去不含病毒串的方案数即可。利用单词构造AC自动机,然后利用自动机上的状态得到一个矩阵mat。用total - (mat^1+mat^2..mat^len),后面的可以利用矩阵快速幂求得。具体解题报告见Here
我们需要构造一个(total *2 )* (total * 2),类似于 ,第1行第一个1所代表的矩阵块表示怎么走都不经过病毒串的方案数,第二个1表示会经过一个串的方案数,第2行做辅助作用。具体解题报告见Here.
,第1行第一个1所代表的矩阵块表示怎么走都不经过病毒串的方案数,第二个1表示会经过一个串的方案数,第2行做辅助作用。具体解题报告见Here.
4、几道难题:
大视野 2434 阿狸的打字机 (NOI 好题)
将trie图的指针反转建fail树,然后利用树状数组进行离线查询。好题,难题.具体报告见Here
用代码串和病毒串建立自动机,他们在自动机上的差别是一个末节点标记,一个不标记。然后将每个代码串尾节点看做图上的一个节点,利用自动机计算每个串其他所有串的不重叠的最短长度即两两节点间的最短距离。最后转变成TSP问题,状态压缩DP解之.具体见Here。
自动机和数位DP结合,需要对trie进行压缩,压缩成一个mat矩阵,mat[i][j]表示i位置下一个j的位置,j为数字0,1...9,找下一个位置是将0,1,2,..9编码成4位二进制,0001,0010,0011...然后在自动机上跑。具体见Here.