为什么要序列化
django 查询数据库返回的类型是 queryset 类型 而我们和前端通信使用的大多数是json类型,这个时候我们需要把 queryset的数据类型转换成python的数据类型然后在转换成json 的格式返回
在我们没使用 restframework 中的 序列化之前我们是这样做的
class RolesView(APIView): def get(self,request,*args,**kwargs): roles = models.Role.objects.all().values('id','title') roles = list(roles) ret = json.dumps(roles,ensure_ascii=False) return HttpResponse(ret)
json.dumps 中的参数 ensure_ascii=False 意思是不把中文进行转义,即显示中文
restframework 中的序列化器就可以自动的帮助我们 把queryset 的数据类型转化成 python的数据类型
restframework 序列化的使用
建表 models.py
from django.db import models class UserGroup(models.Model): title = models.CharField(max_length=32) class UserInfo(models.Model): user_type_choices = ( (1,'普通用户'), (2,'VIP'), (3,'SVIP'), ) user_type = models.IntegerField(choices=user_type_choices) username = models.CharField(max_length=32,unique=True) password = models.CharField(max_length=64) group = models.ForeignKey("UserGroup") roles = models.ManyToManyField("Role") class UserToken(models.Model): user = models.OneToOneField(to='UserInfo') token = models.CharField(max_length=64) class Role(models.Model): title = models.CharField(max_length=32)
添加Role

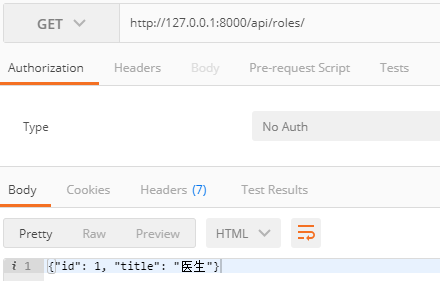
查询所有的角色,使用 restframework进行序列化基本的使用如下
1 写一个序列化的类继承 serializers 或 ModelSerializer ,类属性是要序列化的数据库表中的字段(注意:这个要对应)
2 把创建序列化对象Obj,把需要序列化的数据传入进去,如果有多条数据 many = True 否则为False
3 通过json.dumps(Obj.data) 转化成json格式
views.py 代码如下
import json from django.shortcuts import render,HttpResponse from rest_framework.views import APIView from . import models from rest_framework import serializers #要先写一个序列化的类 class RolesSerializer(serializers.Serializer): #Role表里面的字段id和title序列化 id = serializers.IntegerField() title = serializers.CharField() class RolesView(APIView): def get(self,request,*args,**kwargs): # 方式一 多条数据的情况: # roles = models.Role.objects.all().values('id','title') # roles = list(roles) # ret = json.dumps(roles,ensure_ascii=False) # 方式二 只有一条数据的情况 roles = models.Role.objects.all() # 序列化,两个参数,instance:接受Queryset(或者对象) mangy=True表示对Queryset进行处理,mant=False表示对对象进行进行处理 ser = RolesSerializer(instance=roles,many=True) # 转成json格式,ensure_ascii=False表示显示中文,默认为True ret = json.dumps(ser.data,ensure_ascii=False) return HttpResponse(ret)
添加对应路由
urlpatterns = [ url(r'roles/$', views.RolesView.as_view()), ]
测试的结果如下:
进阶使用
上述的情况是普通的字段,如果是特殊的字段,那么我们又该如何去处理呢,我们来操作user表,表中的字段如下
class UserInfo(models.Model):
user_type_choices = (
(1,'普通用户'),
(2,'VIP'),
(3,'SVIP'),
)
user_type = models.IntegerField(choices=user_type_choices)
username = models.CharField(max_length=32,unique=True)
password = models.CharField(max_length=64)
group = models.ForeignKey("UserGroup")
roles = models.ManyToManyField("Role")
我们使用上述的方法对其所有的字段进行序列化代码如下
class UserInfoSerializer(serializers.Serializer): user_type = serializers.CharField() # row.user_type username = serializers.CharField() password = serializers.CharField() group = serializers.CharField() roles = serializers.CharField() class UserInfoView(APIView): def get(self,request,*args,**kwargs): users = models.UserInfo.objects.all() # 对象, Serializer类处理; self.to_representation # QuerySet,ListSerializer类处理; self.to_representation ser = UserInfoSerializer(instance=users,many=True) ret = json.dumps(ser.data, ensure_ascii=False) return HttpResponse(ret)
为其添加路由
urlpatterns = [ url('(?P<version>[v1|v2]+)/users/$', views.UserView.as_view(),name='uuu'), url(r'parser/$', views.ParserView.as_view()), url(r'roles/$', views.RolesView.as_view()), url(r'userinfo/$', views.UserInfoView.as_view()), ]
测试的结果如下

情况一 对于数据库中自已选择的字段
对于表中的 user_type是choices(1,2,3)我们想显示全称 ,解决的方法是 传入参数source="get_user_type_display" ,它会自动的帮我们执行 get_user_type_display方法
修改后的序列化器如下
class UserInfoSerializer(serializers.Serializer): # user_type = serializers.CharField() # row.user_type user_type = serializers.CharField(source="get_user_type_display") # row.get_user_type_display() username = serializers.CharField() password = serializers.CharField() group = serializers.CharField() roles = serializers.CharField()
测试的结果如下

情况二对于外键(一对一)
对于表中外键的字段gruop ,我们想显示与其关联的title字段的内容 ,解决的方法是还是通过传入参数source="group.title" 它会自动的去查找
修改后的序列化器如下

情况三 对于外键(多对多的情况)
对于外键多对多的情况我们想显示其中的一些字段,这个时候由于是多对多它是一个可迭代的对象,所以不能直接向上面一对一的情况直接取,解决的方法这时候我们需要自定义方法来获取
特别需要注音的是
1 如果 要显示外键多对多内容 要使用 roles = serializers.SerializerMethodField()
2 还有就是自定义函数的函数名应该是 如果多对多的外键是roles 函数名则应该是 get_roles(self,role--->可以随命名) ,如果是rls则函数名为get_rls
代码如下
class UserInfoSerializer(serializers.Serializer): # user_type = serializers.CharField() # row.user_type user_type = serializers.CharField(source="get_user_type_display") # row.get_user_type_display() username = serializers.CharField() password = serializers.CharField() # group = serializers.CharField() group = serializers.CharField(source='group.title') # roles = serializers.SerializerMethodField() roles = serializers.SerializerMethodField() # 自定义显示 def get_roles(self,row): role_obj_list = row.roles.all() ret = [] for item in role_obj_list: ret.append({'id':item.id,'title':item.title}) return ret
测试的结果如下

ModelSerializer 序列化器的使用
ModelSerializer 继承 的是Serializer ,所以我们在使用它的时候同样可以混合着 Serializer 使用,它主要是在序列化字段的时候做了一些简化可以简单的对字段进行批量的定义和全部序列
在用的时候需要注意的是 对于一些普通的字段不能调用的应该放入 列表中,要是向Serializer 中 password = serializers.CharField() 这样去使用会报错
基本使用
class UserInfoSerializer(serializers.ModelSerializer): class Meta: model = models.UserInfo fields = "__all__" # 序列话所有的字段 # fields = ['id','username','password','oooo','rls','group','x1'] # 对指定的字段进行批量处理
测试的结果如下

和Serializer混合使用
class UserInfoSerializer(serializers.ModelSerializer): oooo = serializers.CharField(source="get_user_type_display") # row.user_type rls = serializers.SerializerMethodField() # 自定义显示 class Meta: model = models.UserInfo # fields = "__all__" fields = ['id','username','password','oooo','rls','group'] def get_rls(self, row): role_obj_list = row.roles.all() ret = [] for item in role_obj_list: ret.append({'id':item.id,'title':item.title}) return ret
测试结果如下

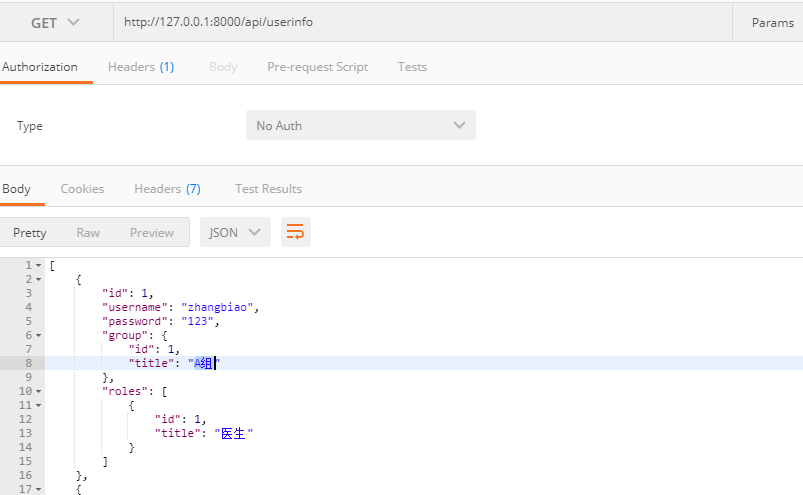
自动序列化连表(depth)
在使用 ModelSerializer 遇到连表的操作,需要我们结合 Serializer 混合使用,其实在ModelSerializer 中还有一个参数表示depth表示连表的深度可以自动的帮我们去取数据
depth 表示夸几张表查询数据,官方建议的参数是 ( 0 ~ 10 )
修改后的序列化器如下所示:
class UserInfoSerializer(serializers.ModelSerializer): class Meta: model = models.UserInfo #fields = "__all__" fields = ['id','username','password','group','roles'] #表示连表的深度 depth = 1 class UserInfoView(APIView): '''用户的信息''' def get(self,request,*args,**kwargs): users = models.UserInfo.objects.all() ser = UserInfoSerializer(instance=users,many=True) ret = json.dumps(ser.data,ensure_ascii=False) return HttpResponse(ret)
测试的结果如下
生成URL
有时候一些数据,我们需要生成url返回给用户,让用户再次请求获取想要的数据
基本的使用如下:
添加字段 group = serializers.HyperlinkedIdentityField(view_name='gp',lookup_field='group_id',lookup_url_kwarg='xxx')
参数说明 view_name 是 需要生成的url 中的name lookup_field 需要生成url的真实传入到额参数, lookup_url_kwarg 需要生成url的形参
修改后的序列化器如下所示
class UserInfoSerializer(serializers.ModelSerializer): group = serializers.HyperlinkedIdentityField(view_name='gp',lookup_field='group_id',lookup_url_kwarg='xxx') class Meta: model = models.UserInfo # fields = "__all__" fields = ['id','username','password','group','roles'] depth = 0 # 0 ~ 10
添加再次请求的类视图和序列化器
class GroupSerializer(serializers.ModelSerializer): class Meta: model = models.UserGroup fields = "__all__" class GroupView(APIView): def get(self,request,*args,**kwargs): pk = kwargs.get('xxx') obj = models.UserGroup.objects.filter(pk=pk).first() ser = GroupSerializer(instance=obj,many=False) ret = json.dumps(ser.data,ensure_ascii=False) return HttpResponse(ret)
添加路由
urlpatterns = [ url('(?P<version>[v1|v2]+)/users/$', views.UserView.as_view(),name='uuu'), url(r'parser/$', views.ParserView.as_view()), url(r'roles/$', views.RolesView.as_view()), url(r'userinfo/$', views.UserInfoView.as_view()), url(r'^(?P<version>[v1|v2]+)/group/(?P<xxx>d+)$', views.GroupView.as_view(),name='gp'), ]
测试的结果如下

用户请求数据验证
使用序列化器对用户传送的值进行非空的判断
添加类视图代码如下
class UserGroupSerializer(serializers.Serializer): title = serializers.CharField(error_messages={'required':'标题不能为空'}) class UserGroupView(APIView): def post(self,request,*args,**kwargs): ser = UserGroupSerializer(data=request.data) if ser.is_valid(): print(ser.validated_data['title']) else: print(ser.errors) return HttpResponse('提交数据')
添加路由
url(r'usergroup/$', views.UserGroupView.as_view(),name='gp'),
测试传入的值为空的接口如下

传入的值为空,后台打印的数据如下

测试非空的值

后台打印的结果如下

自定义验证规则
自定义了一个规则,传入的值必须以老男人开头,否则验证不通过
完整的代码如下
class XXValidator(object): def __init__(self, base): self.base = base def __call__(self, value): if not value.startswith(self.base): message = '标题必须以 %s 为开头。' % self.base raise serializers.ValidationError(message) def set_context(self, serializer_field): """ This hook is called by the serializer instance, prior to the validation call being made. """ # 执行验证之前调用,serializer_fields是当前字段对象 pass class UserGroupSerializer(serializers.Serializer): title = serializers.CharField(error_messages={'required':'标题不能为空'},validators=[XXValidator('老男人'),]) class UserGroupView(APIView): def post(self,request,*args,**kwargs): ser = UserGroupSerializer(data=request.data) if ser.is_valid(): print(ser.validated_data['title']) else: print(ser.errors) return HttpResponse('提交数据')
测试满足自定义规则的数据的结果如下

后台打印数据如下

测试不满足自定义规则

后台打印结果如下

write_only和write_only的区别
write_only 包含这个字段只作用于反序 (即对前端传来的值做序列话),正序的时候会忽略该字段
read_only 包含这个字段只作用于正序 (即查询数据库做序列化返回给前端),反序的时候会忽略该字段
方法字段
serializers.SerializerMethodField 会把一个字段变成一个方法的字段,所以要为这个字段定义一个方法,返回的值为作为该字段的值
实例如下
表结构
class Book(models.Model): title = models.CharField(max_length=32) CHOICES = ((1, "Python"), (2, "Linux"), (3, "go")) category = models.IntegerField(choices=CHOICES) pub_time = models.DateField() publisher = models.ForeignKey(to="Publisher") authors = models.ManyToManyField(to="Author") class Publisher(models.Model): title = models.CharField(max_length=32) class Author(models.Model): name = models.CharField(max_length=32)
序列化
class BookSerializer(serializers.ModelSerializer): publisher_info = serializers.SerializerMethodField(read_only=True) authors_info = serializers.SerializerMethodField(read_only=True) def get_authors_info(self, obj): authors_querset = obj.authors.all() return [{"id": author.id, "name": author.name} for author in authors_querset] def get_publisher_info(self, obj): publisher_obj = obj.publisher return {"id": publisher_obj.id, "title": publisher_obj.title} class Meta: model = Book fields = "__all__" # exclude=["id"] # 会让你这些所有的外键关系变成read_only = True # depth = 1 extra_kwargs = {"publisher": {"write_only": True}, "authors":{"write_only": True}}
简单实例
class BookEditView(APIView):
def get(self, request, id):
book_obj = Book.objects.filter(id=id).first()
ser_obj = BookSerializer(book_obj)
return Response(ser_obj.data)
def put(self, request, id):
book_obj = Book.objects.filter(id=id).first()
ser_obj = BookSerializer(instance=book_obj, data=request.data, partial=True)
if ser_obj.is_valid():
ser_obj.save()
return Response(ser_obj.validated_data)
return Response(ser_obj.errors)
ModelSerializer 中 deep 使用注意事项
在使用 deep 是 会把所有的 外键关系变成 read_only = True ,解决这个问题,我们可以 通过 extra_kwargs 为其添加额外的参数配置
class Meta:
model = Book
fields = "__all__"
# exclude=["id"]
# 会让你这些所有的外键关系变成read_only = True
depth = 1
extra_kwargs = {"publisher": {"write_only": True}, "authors":{"write_only": True}}
验证
-- 单个字段的验证 权重 222
def validate_字段名称(self, value):
不通过 raise serializers.ValidationError("错误信息")
通过 return value
-- 多个字段的验证 权重 333
def validate(self, attrs):
attrs 是所有字段组成的字典
不通过 raise serializers.ValidationError("错误信息")
通过 return attrs
-- 自定义的验证 权重 111
def my_validate(value):
不通过 raise serializers.ValidationError("错误信息")
通过 return value
配置
-- 给字段加validators=[my_validate]
简单用法
def validate_title(self, value):
print(2222)
# value就是title的值 对value处理
if "python" not in value.lower():
raise serializers.ValidationError("标题必须含有python")
return value
def validate(self, attrs):
print(33333)
# attrs 字典有你传过来的所有的字段
print(attrs)
if "python" in attrs["title"].lower() or attrs["post_category"] == 1:
return attrs
else:
raise serializers.ValidationError("分类或标题不合符要求")
重写update方法
def update(self, instance, validated_data):
# instance 更新的book_obj 对象
# validated_data 校验通过的数据
# ORM做更新操作
instance.title = validated_data.get("title", instance.title)
instance.pub_time = validated_data.get("pub_time", instance.pub_time)
instance.category = validated_data.get("post_category", instance.category)
instance.publisher_id = validated_data.get("publisher_id", instance.publisher_id)
if validated_data.get("author_list"):
instance.authors.set(validated_data["author_list"])
instance.save()
return instance
重写create方法
def create(self, validated_data):
# validated_data 校验通过的数据 就是book_obj
# 通过ORM操作给Book表增加数据
print(validated_data)
book_obj = Book.objects.create(title=validated_data["title"], pub_time=validated_data["pub_time"], category=validated_data["post_category"], publisher_id=validated_data["publisher_id"])
print(book_obj)
book_obj.authors.add(*validated_data["author_list"])
return book_obj
过滤Filtering
对于列表数据可能需要根据字段进行过滤,我们可以通过添加django-fitlter扩展来增强支持。
pip install django-filter
注册应用:
INSTALLED_APPS = [ "django_filters", ]
在配置文件中增加过滤后端的设置:
REST_FRAMEWORK = {
'DEFAULT_FILTER_BACKENDS': ('django_filters.rest_framework.DjangoFilterBackend',)
}
在视图中添加filter_fields属性,指定可以过滤的字段
class BookListView(ListAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
filter_fields = ('btitle', 'bread')