1.需求分析
使用JAVA编程语言,独立完成一个英文文本词频统计的软件开发。软件基本功能要求如下:
1.程序可读入任意英文文本文件,该文件中英文词数大于等于1个。
2.程序需要很壮健,能读取容纳英文原版《哈利波特》10万词以上的文章。
3.指定单词词频统计功能:用户可输入从该文本中想要查找词频的一个或任意多个英文单词,运行程序的统计功能可显示对应单词在文本中出现的次数和柱状图。
4.高频词统计功能:用户从键盘输入高频词输出的个数k,运行程序统计功能,可按文本中词频数降序显示前k个单词的词频及单词。
5.统计该文本所有单词数量及词频数,并能将单词及词频数按字典顺序输出到文件words.txt。
2. 功能设计
基本功能:利用java的io流实现对文本文件的读取、Map和HashMap集合对文件进行存储,进行词频统计后输出单词的使用次数。
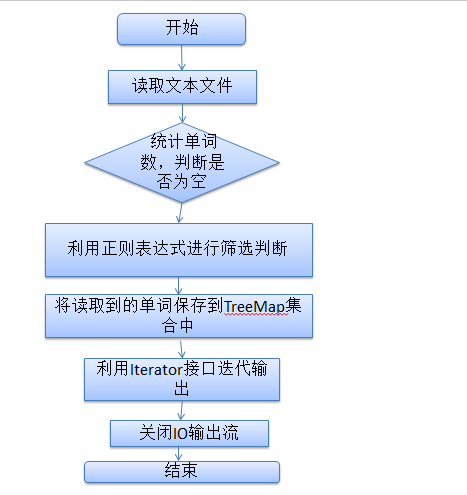
3. 流程图
程序设计流程图如下:
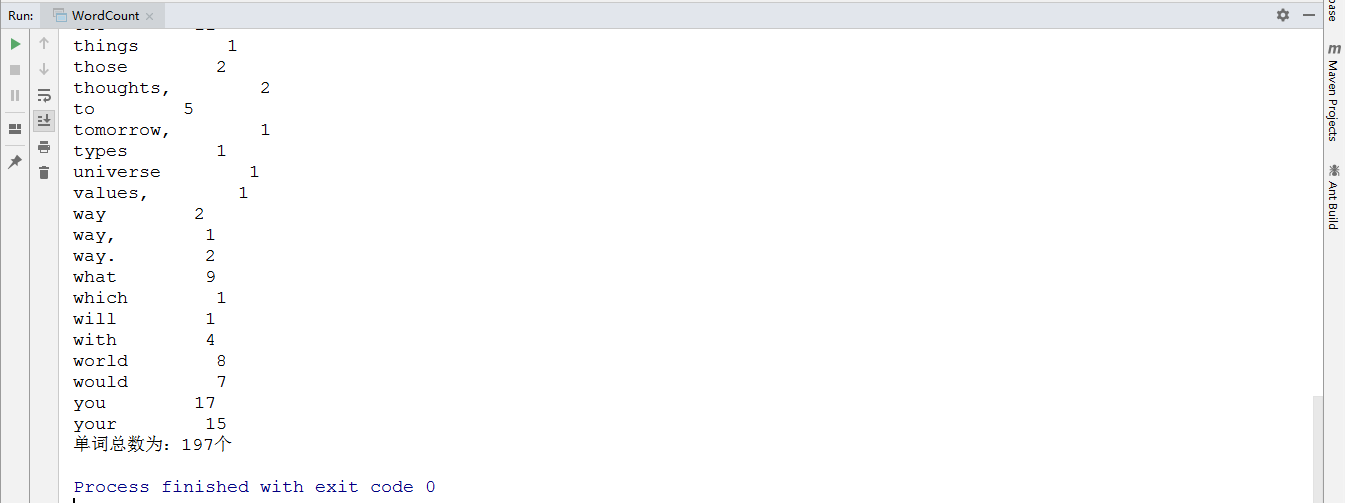
4. 测试运行

5. 主要代码
过滤代码块;
String[] str = readLine.split("[\s]"); //过滤掉多个空格,“+”代表多个空格的意思 for(int i = 0;i<str.length;i++){ count++; String word = str[i].trim();//trim()用来去掉字符串首尾的空格 if(treemap.containsKey(word)){//判断此映射是否包含指定键的映射关系 treemap.put(word, treemap.get(word)+1); }else{ treemap.put(word, 1); } }
输出代码块:
System.out.println("单词:"+" "+"单词出现的频率:" );
Iterator<Map.Entry<String,Integer>> it = treemap.entrySet().iterator();
//判断是否存在下一个单词
while(it.hasNext()){
Map.Entry<String, Integer> entry = it.next();//获取map中每一个键值
//输出结果
System.out.println(entry.getKey()+" "+entry.getValue());
br.close();//关闭流
}
System.out.println("单词总数为:"+count+"个");
}catch(FileNotFoundException e){//异常处理
e.printStackTrace();
}catch(IOException e){
e.printStackTrace();
}
6. 总结
本次设计主要分为字符流读取模块、字符存储模块、字频统计模块、字符输出模块,各个模块通过主函数来调用,实现了模块化设计。
7. PSP展示
| 任务内容 | 计划共完成需要的时间(min) | 实际完成需要的时间(min) |
|---|---|---|
| 计划 | 10 | 5 |
| 估计这个任务需要的时间,并规划大致工作步骤 | 5 | 3 |
| 开发 | 100 | 120 |
| 需求分析(包括学习新技术) | 7 | 9 |
| 生成设计文档 | 15 | 20 |
| 设计复审 | 5 | 7 |
| 代码规范(为目前的开发制定合适的规范) | 5 | 5 |
| 具体设计 | 6 | 8 |
| 具体编码 | 60 | 80 |
| 代码复审 | 10 | 25 |
| 测试(自我测试、修改代码、提交修改) | 10 | 8 |
| 报告 | 20 | 25 |
| 测试报告 | 10 | 10 |
| 事后总结,并提出过程改进计划 | 25 | 20 |
从PSP表中可以发现项目在实施工程中的时间比预计时间要长,可能和自己对开发流程不熟悉、算法设计不精有关。在以后的 开发中要多加改进。
源代码地址;https://github.com/CoderLixin/GitTest