一、贝叶斯分类
是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称贝叶斯分类。而贝叶斯分类中最简单的一种:朴素贝叶斯分类。
二、贝叶斯定理:
已知某条件概率,如何得到两个事件交换后的概率,也就是在已知P(A|B)的情况下如何求得P(B|A)。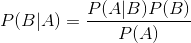
三、朴素贝叶斯分类思想:
给出待分类项,求解在此项出现的条件下其他各个类别的出现的概率,哪个概率较大就认为待分类项属于哪个类别。
四、朴素贝叶斯法分解过程:
p(yi|x)=p(x|yi)*p(yi)/p(x) 其中对于分母所有类别为常数,因此我们只需将分子最大化皆可。
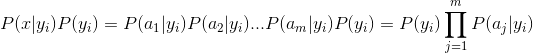
拉普拉斯校准:就是对没类别下所有划分的计数加1,这样如果训练样本集数量充分大时,并不会对结果产生影响,并且解决了上述频率为0的尴尬局面。
下面这个博主讲的例子非常简明,看完了就知道上面的四个步骤的由来
五、案例分析
来一个李航博士书中案例(Naive Bayes Classifier,或 NBC)实现过程


首先给出一些定义,输入空间x属于Rn为n维向量集合,输出空间为类标记集合y={c1,c2,...,cK}
1.先验概率分布,P(Y=ck)即案例中P(Y=1),先验概率的个数size(y)
2. 条件概率 P(X=x|Y=ck)即案例中P(X(1)=1|Y=1),条件概率的个数等于size(x)*size(y)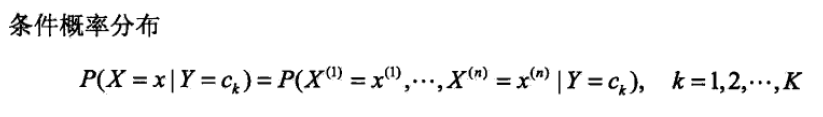
朴素贝叶斯法实际上学习到生成数据的机制,属于生成模型。条件独立假设等于是说用分类的特征在类确定的条件下都是独立条件,这一假设会使贝叶斯变得简单,但是会牺牲一定分类准确率
3.朴素贝叶斯法的学习与分类算法

六、算法实现
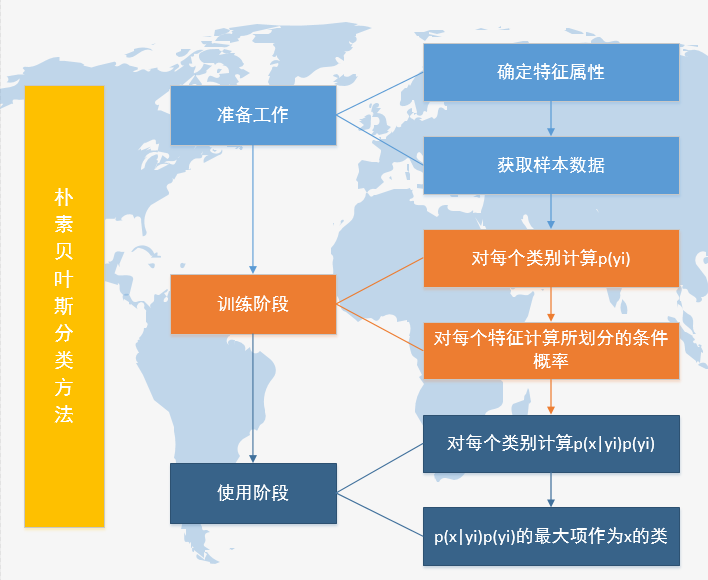
看了很多博主写的贝叶斯算法,但是大多数都是只有代码看不到数据,要么提供了数据,由于自己是新手,看不懂他们如何处理的数据,于是打算自己写个算法,数据就是本文中的案例数据,代码见下
' '
#encoding=utf-8
import numpy as np
import pandas as pd
test = [2,'S']
def Train(features, labels):
global label, feature
# 计算结果的类别
label = np.unique(labels)
# 计算数据特征的维度,每个维度不止一个特征值
features_num = features.shape[1]
feature = np.unique(features) #这里可能有文字,文字里面有可能有空格干扰求无重复项
# 初始化先验概率和条件概率
prior = np.zeros(len(label))
conditional = np.zeros([len(label), len(feature)])
# 首先计算先验概率
for i in range(len(label)):
label_class_sum = np.sum(labels ==label[i])
label_len = len(labels)
prior[i] = float(label_class_sum)/float(label_len)
# 其次再计算条件概率
for j in range(len(feature)):
feature_conditional = features[labels==label[i]]
feature_class_sum= np.sum(feature_conditional==feature[j])
conditional[i][j] = float(feature_class_sum)/float(label_class_sum )
return prior, conditional
def Predict(prior, conditional,test):
global label,feature
result = np.zeros(len(label))
for i in range(len(label)):
result[i] =conditional[i,feature==test[0]]*conditional[i,feature==test[1]]*(prior[i])
result = np.vstack([result,label])
return result
if __name__=="__main__":
raw_data = pd.read_csv('D:\Python27\yy\data\three_bayes.csv')
raw_data = raw_data.replace(' ','',regex=True)
data = raw_data.values
labels = data[::,0]
features = data[::,1::]
prior_probability, conditional_probability = Train(features, labels)
result = Predict(prior_probability, conditional_probability, test)
print 'the test result is',result,
返回结果
the test result is [[0.06666666666666667 0.02222222222222222]
[-1L 1L]]