因为要上线一个需求,有改到spark sql。 在改之前我一般习惯把生产原逻辑跑一边理解下(需求赶,都是边读业务边写)
但奇怪的是,在生产上已经跑了24个账期的代码,拉到自己环境跑却报了 两者的版本都是2.X
Detected cartesian product for INNER join between logical plans的错误。
这个错误很明显,笛卡尔积。
国内所有的解决方案都是抄袭的
设置 配置 spark.conf.set("spark.sql.crossJoin.enabled", "true") 这个在2.X是默认关闭的。
但是!我去生产上spark.conf.get("spark.sql.crossJoin.enabled") 一下,得到的结果是false, 说明生产上也是没开启的。而且开启这个在许多情况下是不建议的,极度消耗性能。
于是我就跑去外面问问老外是怎么解决了。

很显然,这位老兄遇到了和我同样的问题。
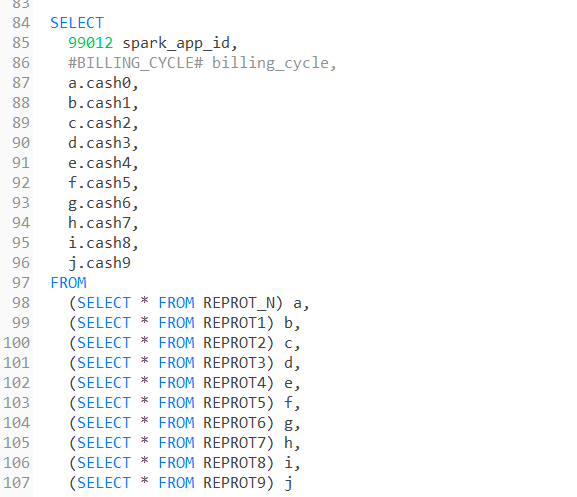
REPORT_X 都是列仅包含单个值,优化器此时无法推断连接列仅包含单个值,并将尝试应用散列或排序合并连接。
说明正常情况下,这串代码理应报笛卡尔积连接问题。但是为什么生产上没有呢。
我就想到了是否是版本问题。结果一查!正是!
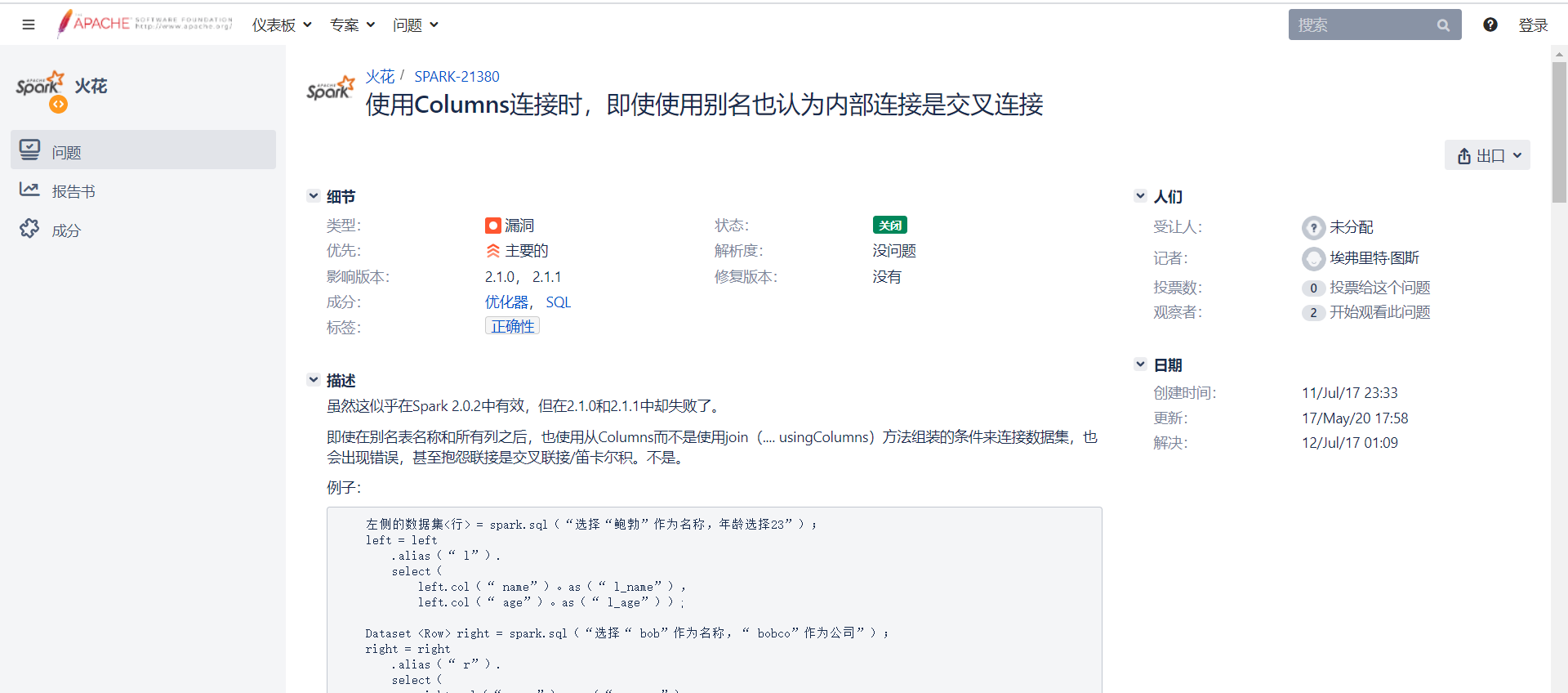
刚好因为版本的问题,虽然在1.X默认开启,2.X默认关闭,但是2.X之间似乎还说会有细微的差别。
至此,问题解决。暂定是版本问题。