import os
import numpy as np
import pandas as pd
from datetime import datetime
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('white')
%matplotlib inline
%load_ext autoreload
%autoreload 2
def to_utms(ut):
return (ut.astype(np.int64) * 1e-6).astype(int)
def read_merged_train_and_test_data(file_name):
src_path = "F:\kaggleDataSet\hackathon-krakow\hackathon-krakow-2017-05-27"
train_path = os.path.join(src_path, "context--2014-01-01_2015-01-01--" + file_name + ".csv")
train_df = pd.read_csv(train_path)
test_path = os.path.join(src_path, "context--2015-01-01_2015-07-01--" + file_name + ".csv")
test_df = pd.read_csv(test_path)
df = pd.concat([train_df, test_df])
return convert_timestamp_to_date(df)
def convert_timestamp_to_date(df, timestamp_column="ut_ms"):
df[timestamp_column] = pd.to_datetime(df[timestamp_column], unit='ms')
df = df.set_index(timestamp_column)
df = df.dropna()
return df
def parse_subsystems(dmop_data):
dmop_frame = dmop_data.copy()
dmop_frame = dmop_frame[dmop_frame["subsystem"].str.startswith("A")]
dmop_frame["device"] = dmop_frame["subsystem"].str[1:4]
dmop_frame["command"] = dmop_frame["subsystem"].str[4:]
dmop_frame = dmop_frame.drop("subsystem", axis=1)
return dmop_frame
def generate_count_in_hour_from_raw_data(raw_data, column_name):
raw_frame = raw_data.copy()
raw_frame["timestamp_by_hour"] = raw_frame.index.map(lambda t: datetime(t.year, t.month, t.day, t.hour))
events_by_hour = raw_frame.groupby(["timestamp_by_hour", column_name]).agg("count")
events_by_hour = events_by_hour.reset_index()
events_by_hour.columns = ['timestamp_by_hour', column_name, 'count']
events_by_hour = events_by_hour.pivot(index="timestamp_by_hour", columns=column_name, values="count").fillna(0)
events_by_hour.columns =["count_" + str(column_name) + "_in_hour" for column_name in events_by_hour.columns]
events_by_hour.index.names = ['ut_ms']
return events_by_hour
def important_commands(dmop_data):
count_of_each_command = dmop_data["command"].value_counts()
important_commands = count_of_each_command[count_of_each_command > 2000]
return list(important_commands.index)
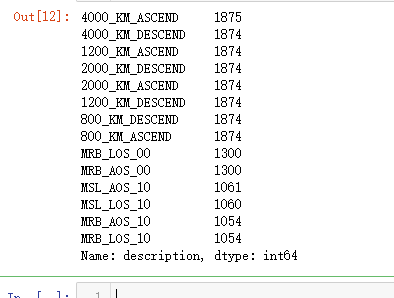
def important_events(evtf_data):
count_of_each_event = evtf_data["description"].value_counts()
important_event_names = count_of_each_event[count_of_each_event > 1000]
return list(important_event_names.index)
dmop_raw = read_merged_train_and_test_data("dmop")
evtf_raw = read_merged_train_and_test_data("evtf")
ltdata_raw = read_merged_train_and_test_data("ltdata")
saaf_raw = read_merged_train_and_test_data("saaf")
power_train_raw = convert_timestamp_to_date(pd.read_csv("F:\kaggleDataSet\hackathon-krakow\hackathon-krakow-2017-05-27\power--2014-01-01_2015-01-01.csv"))
power_train_raw = power_train_raw.resample("1H").mean().dropna()
power_test_raw = convert_timestamp_to_date(pd.read_csv("F:\kaggleDataSet\hackathon-krakow\hackathon-krakow-2017-05-27\sample_power_zeros--2015-01-01_2015-07-01.csv"))
power_raw = pd.concat([power_train_raw, power_test_raw])
plt.figure(figsize=(20, 3))
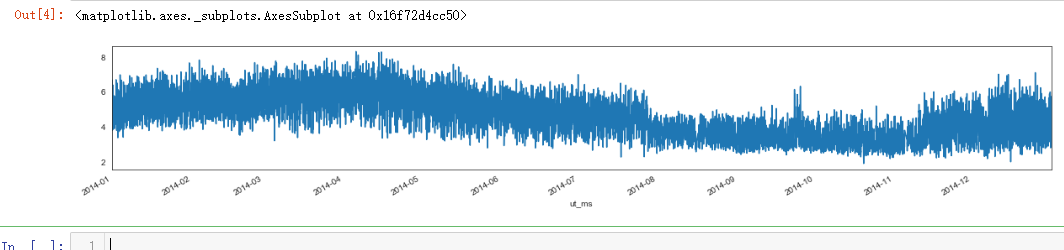
power_raw_with_sum = power_train_raw.copy()
power_raw_with_sum["power_sum"] = power_raw_with_sum.sum(axis=1)
power_raw_with_sum["power_sum"].plot()
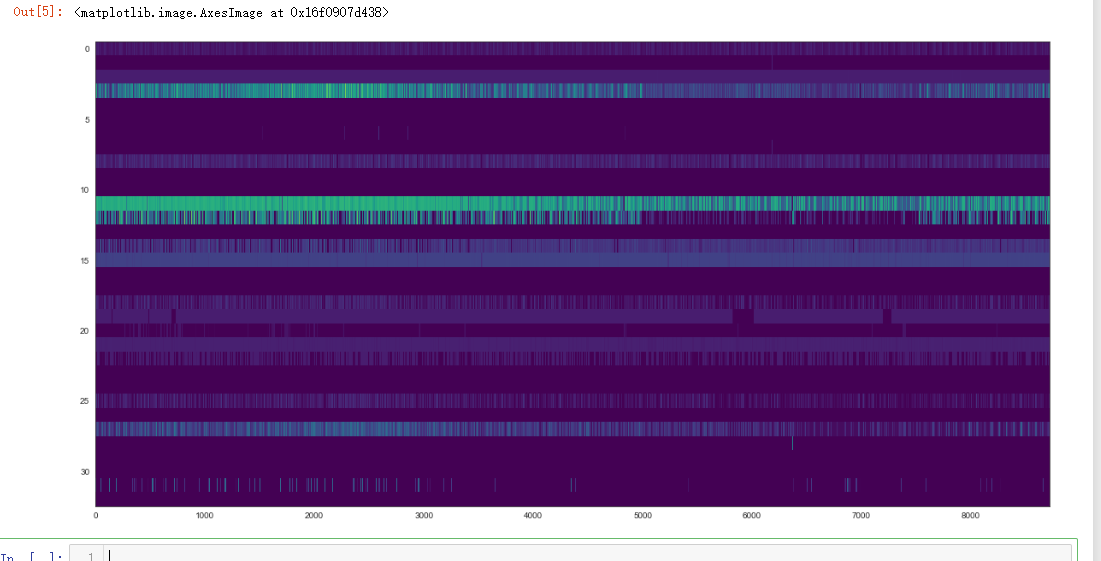
plt.figure(figsize=(20, 10))
plt.imshow(power_train_raw.values.T, aspect='auto', cmap="viridis")
dmop_devices = parse_subsystems(dmop_raw)
dmop_devive_commands_by_hour = generate_count_in_hour_from_raw_data(dmop_devices, "device")
dmop_devive_commands_by_hour["dmop_sum"] = dmop_devive_commands_by_hour.sum(axis=1)
dmop_commands_by_hour = generate_count_in_hour_from_raw_data(dmop_devices, "command")
important_command_names = important_commands(dmop_devices)
important_command_names = list(map(lambda x: "count_" + x + "_in_hour", important_command_names))
dmop_commands_by_hour = dmop_commands_by_hour[important_command_names]
dmop_data_per_hour = pd.concat([dmop_devive_commands_by_hour, dmop_commands_by_hour], axis=1)
dmop_data_per_hour.head()
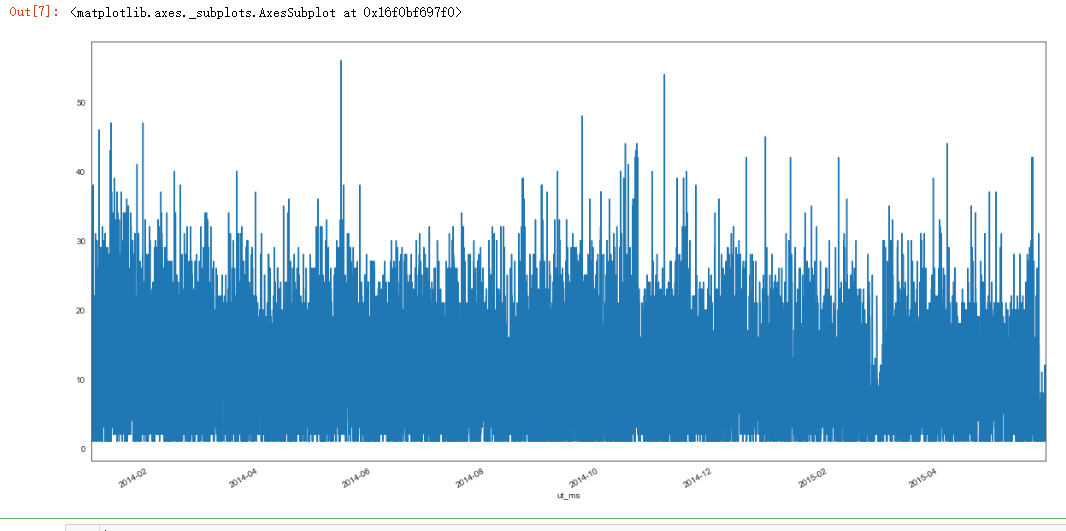
plt.figure(figsize=(20, 10))
dmop_devive_commands_by_hour["dmop_sum"].plot()
dmop_data = dmop_data_per_hour.reindex(power_raw_with_sum.index, method="nearest")
dmop_with_power_data = pd.concat([power_raw_with_sum, dmop_data], axis=1)
dmop_with_power_data.columns
sns.jointplot("dmop_sum", "power_sum", dmop_with_power_data)

dmop_with_power_data = dmop_with_power_data.resample("24h").mean()
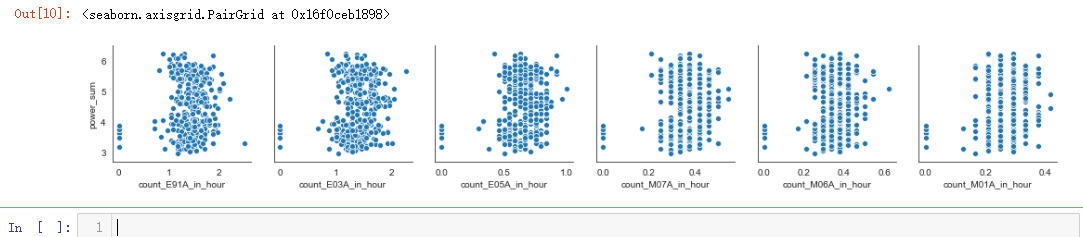
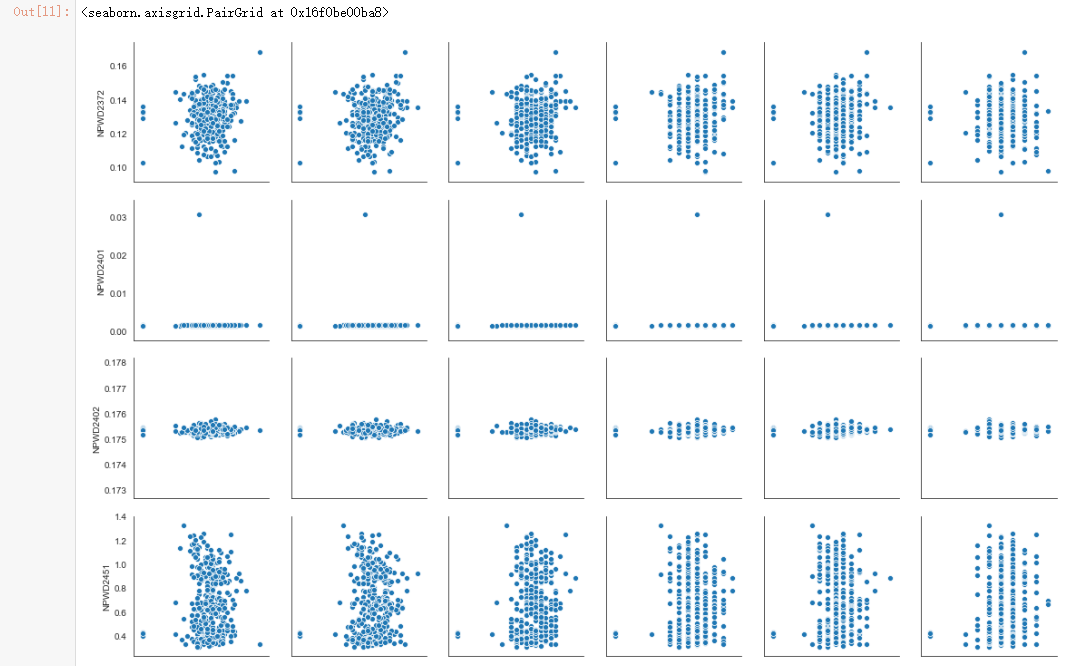
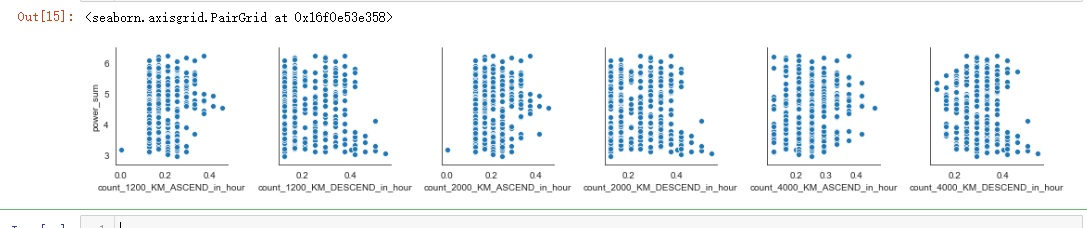
sns.pairplot(dmop_with_power_data, x_vars=dmop_commands_by_hour.columns[0:6], y_vars="power_sum")
sns.pairplot(dmop_with_power_data, x_vars=dmop_commands_by_hour.columns[0:6], y_vars=power_raw.columns[0:6])
important_event_names = list(filter(lambda name: (not("_START" in name) and not("_END" in name)), important_events(evtf_raw)))
important_evtf = evtf_raw[evtf_raw["description"].isin(important_event_names)]
important_evtf["description"].value_counts()
important_evtf_with_count = important_evtf.copy()
important_evtf_with_count["count"] = 1
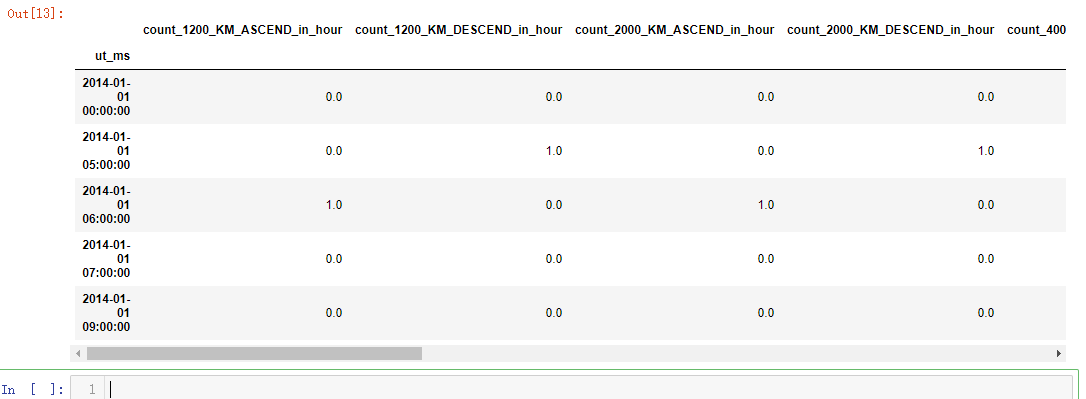
important_evtf_data_per_hour = generate_count_in_hour_from_raw_data(important_evtf_with_count, "description")
important_evtf_data_per_hour.head()
evtf_data = important_evtf_data_per_hour.reindex(power_raw_with_sum.index, method="nearest")
evtf_with_power_data = pd.concat([power_raw_with_sum, evtf_data])
evtf_with_power_data.columns

evtf_with_power_data = evtf_with_power_data.resample("24h").mean()
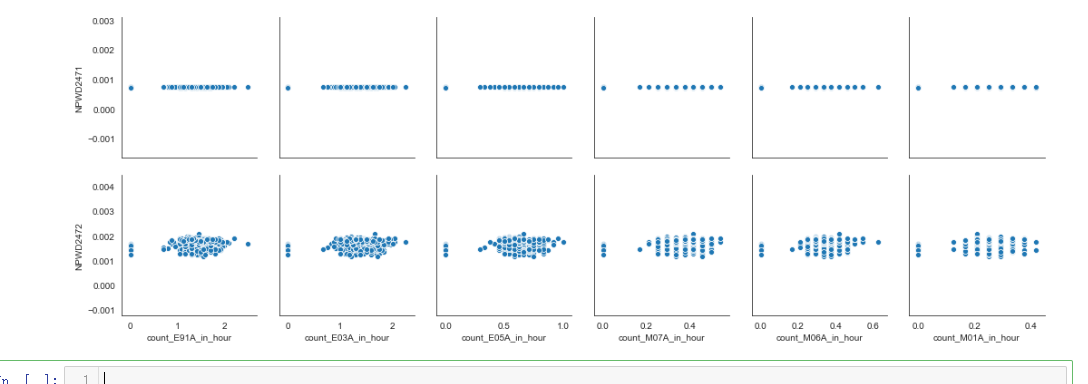
sns.pairplot(evtf_with_power_data, x_vars=important_evtf_data_per_hour.columns[0:6], y_vars="power_sum")
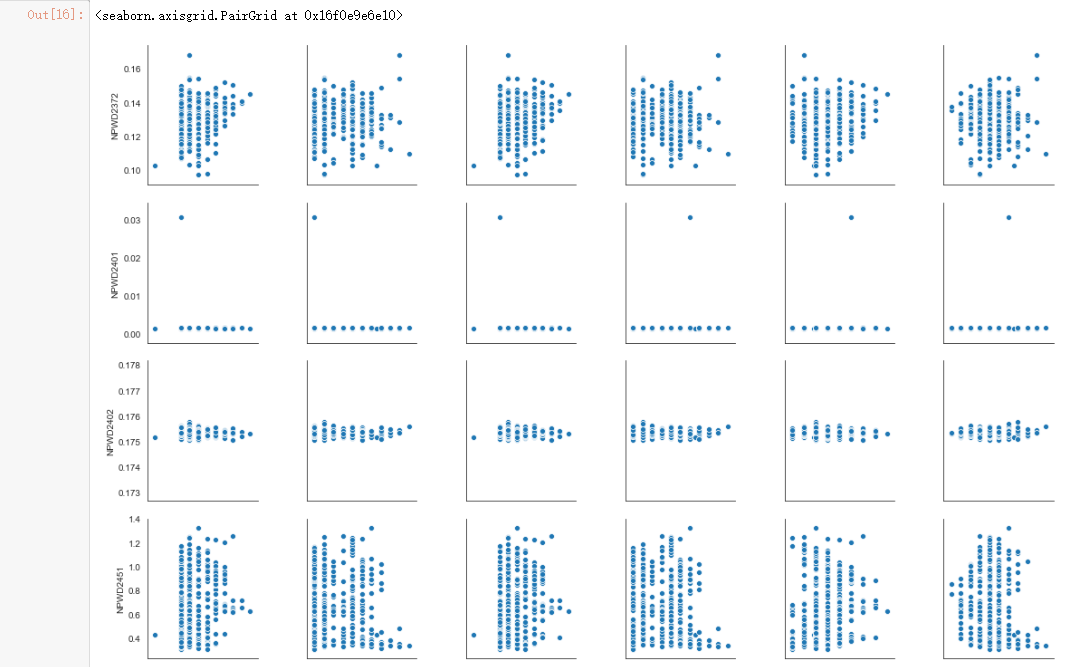
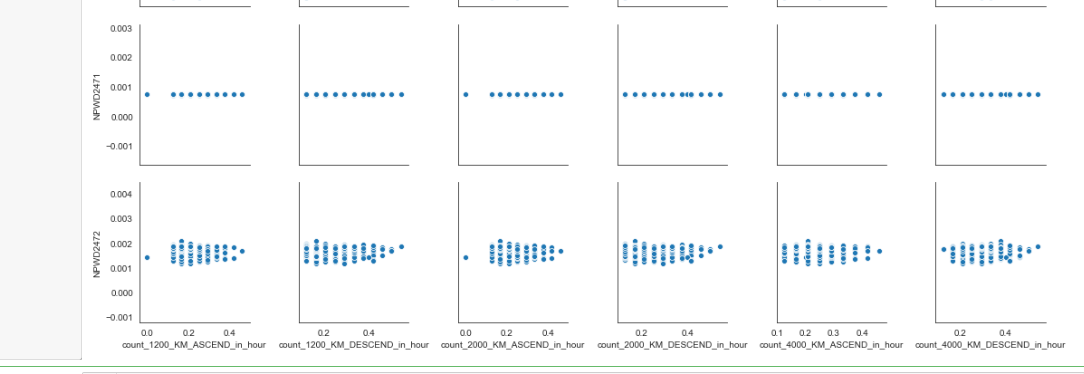
sns.pairplot(evtf_with_power_data, x_vars=important_evtf_data_per_hour.columns[0:6], y_vars=power_raw.columns[0:6])
def is_start_event(description, event_type):
return int((event_type in description) and ("START" in description))
msl_events = ["MSL_/_RANGE_06000KM_START", "MSL_/_RANGE_06000KM_END"]
mrb_events = ["MRB_/_RANGE_06000KM_START", "MRB_/_RANGE_06000KM_END"]
penumbra_events = ["MAR_PENUMBRA_START", "MAR_PENUMBRA_END"]
umbra_events = ["MAR_UMBRA_START", "MAR_UMBRA_END"]
msl_events_df = evtf_raw[evtf_raw["description"].isin(msl_events)].copy()
msl_events_df["in_msl"] = msl_events_df["description"].map(lambda row: is_start_event(row, "MSL"))
msl_events_df = msl_events_df["in_msl"]
mrb_events_df = evtf_raw[evtf_raw["description"].isin(mrb_events)].copy()
mrb_events_df["in_mrb"] = mrb_events_df["description"].map(lambda row: is_start_event(row, "MRB"))
mrb_events_df = mrb_events_df["in_mrb"]
penumbra_events_df = evtf_raw[evtf_raw["description"].isin(penumbra_events)].copy()
penumbra_events_df["in_penumbra"] = penumbra_events_df["description"].map(lambda row: is_start_event(row, "PENUMBRA"))
penumbra_events_df = penumbra_events_df["in_penumbra"]
umbra_events_df = evtf_raw[evtf_raw["description"].isin(umbra_events)].copy()
umbra_events_df["in_umbra"] = umbra_events_df["description"].map(lambda row: is_start_event(row, "UMBRA"))
umbra_events_df = umbra_events_df["in_umbra"]

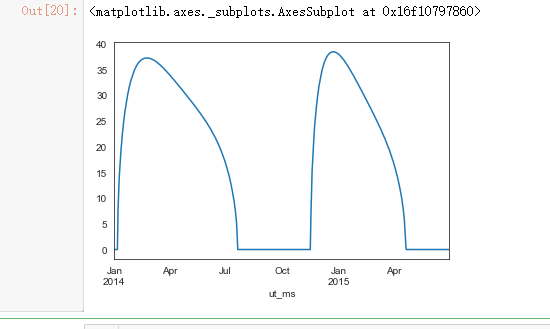
ltdata_raw["eclipseduration_min"].plot()
dmop_data = dmop_data_per_hour.reindex(power_raw.index, method="nearest")
evtf_events_data = important_evtf_data_per_hour.reindex(power_raw.index, method="nearest")
msl_period_events_data = msl_events_df.reindex(power_raw.index, method="pad").fillna(0)
mrb_period_events_data = mrb_events_df.reindex(power_raw.index, method="pad").fillna(0)
penumbra_period_events_data = penumbra_events_df.reindex(power_raw.index, method="pad").fillna(0)
umbra_period_events_data = umbra_events_df.reindex(power_raw.index, method="pad").fillna(0)
ltdata_data = ltdata_raw.reindex(power_raw.index, method="nearest")
saaf_data = saaf_raw.reindex(power_raw.index, method="nearest")
all_data = pd.concat([power_raw, dmop_data, evtf_events_data, msl_period_events_data, mrb_period_events_data, penumbra_period_events_data, umbra_period_events_data, ltdata_data, saaf_data], axis=1)
print(all_data.columns, all_data.shape)

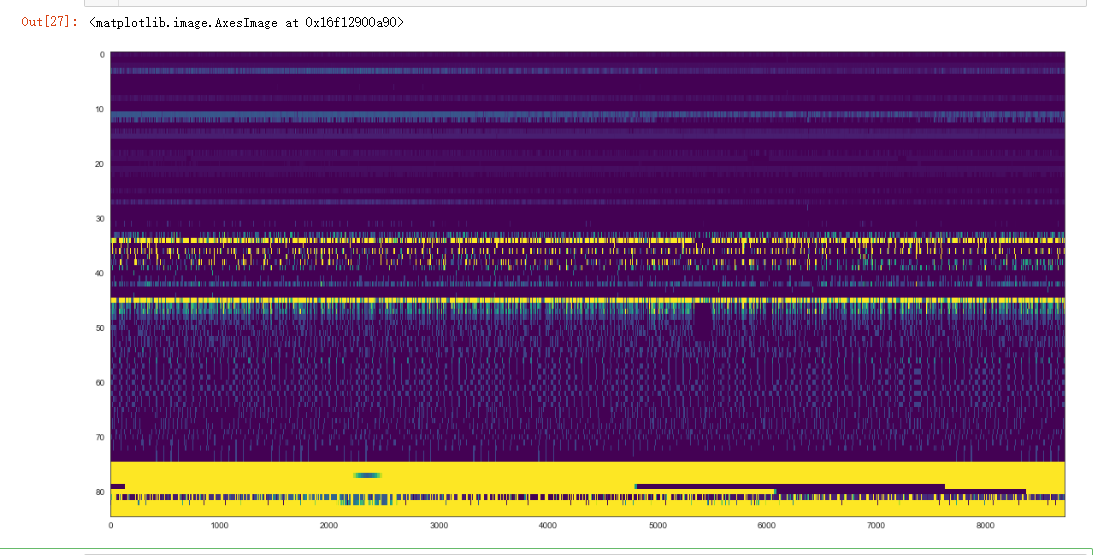
plt.figure(figsize=(20, 10))
plt.imshow(all_data.values.T, aspect='auto', vmin=0, vmax=5, cmap="viridis")

train_set_start_date, train_set_end_date = power_train_raw.index[0], power_train_raw.index[-1]
train_data = all_data[all_data.index <= train_set_end_date].copy()
test_data = all_data.loc[power_test_raw.index].copy()
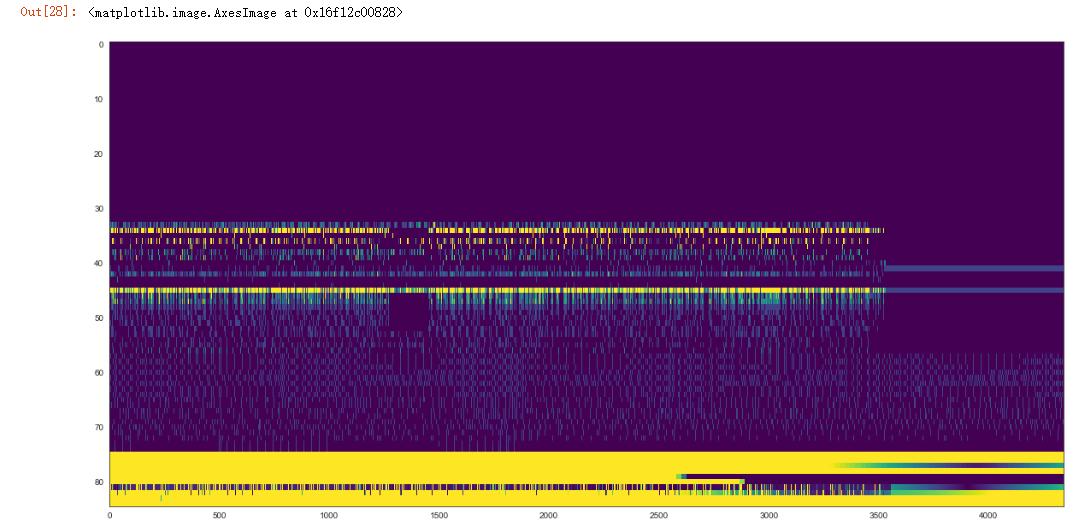
plt.figure(figsize=(20, 10))
plt.imshow(train_data.values.T, aspect='auto', vmin=0, vmax=5, cmap="viridis")
plt.figure(figsize=(20, 10))
plt.imshow(test_data.values.T, aspect='auto', vmin=0, vmax=5, cmap="viridis")
X_train = train_data[train_data.columns.difference(power_raw.columns)]
y_train = train_data[power_raw.columns]
from sklearn.model_selection import train_test_split
X_train, X_validation, y_train, y_validation = train_test_split(X_train, y_train, test_size=0.3, random_state=0)
from sklearn import linear_model
from sklearn.metrics import mean_squared_error
reg = linear_model.LinearRegression()
reg.fit(X_train, y_train)
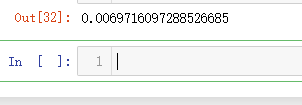
y_validation_predicted = reg.predict(X_validation)
mean_squared_error(y_validation, y_validation_predicted)
elastic_net = linear_model.ElasticNet()
elastic_net.fit(X_train, y_train)
y_validation_predicted = elastic_net.predict(X_validation)
mean_squared_error(y_validation, y_validation_predicted)