Bitcask 存储模型
Bitcask 是一个日志型、基于hash表结构的key-value存储模型,以Bitcask为存储模型的K-V系统有 Riak 和 beansdb 新版本。
日志型数据存储
何谓日志型?就是append only,所有写操作只追加而不修改老的数据,就像我们的各种服务器日志一样。在Bitcask模型中,数据文件以日志型只增不减的写入文件,而文件有一定的大小限制,当文件大小增加到相应的限制时,就会产生一个新的文件,老的文件将只读不写。在任意时间点,只有一个文件是可写的,在Bitcask模型中称其为active data file,而其他的已经达到限制大小的文件,称为older data file,如下图:

文件中的数据结构非常简单,是一条一条的数据写入操作,每一条数据的结构如下:
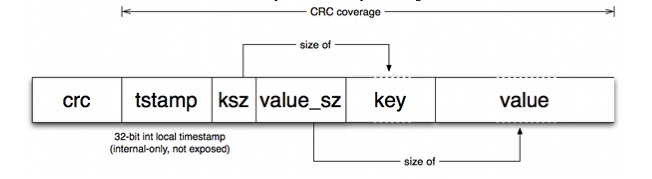
上面数据项分别为key,value,key的大小,value的大小,时间戳(应该是),以及对前面几项做的crc校验值。(数据删除操作也不会删除旧的条目,而是将value设定为一个特殊的值以作标示)
数据文件中就是连续一条条上面格式的数据,如下图:
上面就是日志型的数据文件,但文件这样持续的存下去,肯定是会无限膨胀的,为了解决个问题,和其他日志型存储系统一样Bitcask也有一个定期的merge操作。
merge操作,即定期将所有older data file中的数据扫描一遍并生成新的data file(没有包括active data file 是因为它还在不停写入),这里的merge其实就是将对同一个key的多个操作以只保留最新一个的原则进行删除。每次merge后,新生成的数据文件就不再有冗余数据了。
事实上,Bitcask 中有两类文件:
- xxx.w:即上面说的数据文件,xxx 是一个数值,写满1G后将新建文件,数值自增,程序往数值最大的一个文件 Append 数据;
- write.pos:记录当前数值最大的 xxx.w 文件(FileNo),以及该文件的写位移(Offset),方便在写数据的时候快速定位;
定义了数据文件和记录写位移的文件后,我们通过以下方式实现数据写:
- 检查当前 xxx.w 文件写位移 + 当前要写入的数据长度是否大于MAX_FILE_SIZE(即一个数据文件的最大size,这里我们定义为1G);如果大于则创建一个序号增 1 的 .w 文件;
- 调用 open、write 函数将数据追加到当前 .w 文件结尾;
- 更新 write.pos 中 FileNo、Offset 的值;
基于hash表的索引数据
写操作有 write.pos 文件指明要写入的 FileNo 和 Offset;但对于读操作,如何快速地从浩瀚的数据中,找到某个 key 对应数据所在的文件和文件位移呢?这要依赖于内存中的hash表数据索引,如下图

hash表对应的这个结构中包括了三个用于定位数据value的信息,分别是文件id号(file_id),value值在文件中的位置(value_pos),value值的大小(value_sz),于是我们通过读取file_id对应文件的value_pos开始的value_sz个字节,就得到了我们需要的value值。整个过程如下图所示:

由于多了一个hash表的存在,我们的写操作就需要多更新一块内容,即这个hash表的对应关系。于是一个写操作就需要进行一次顺序的磁盘写入和一次内存操作。
另外,由于索引hash表是存放在内存中的,每次进程重启时需要重建hash表,这需要整个扫描一遍所有的数据文件,如果数据文件很大,这将是一个非常耗时的过程。因此Bitcask模型中包含了一个称作hint file的部分,目的在于提高重建hash表的速度。
上面讲到在old data file进行merge操作时,会产生新的data file,而Bitcask模型实际还鼓励生成一个hint file,这个hint file中每一项的数据结构,与data file中的数据结构非常相似,不同的是他并不存储具体的value值,而是存储value的位置,这样,在重建hash表时,就不需要再扫描所有data file文件,而仅仅需要将hint file中的数据一行行读取并重建即可。大大提高了利用数据文件重启数据库的速度。