1. Java安装与环境配置
Hadoop是基于Java的,所以首先需要安装配置好java环境。从官网下载JDK,我用的是1.8版本。 在Mac下可以在终端下使用scp命令远程拷贝到虚拟机linux中。
danieldu@daniels-MacBook-Pro-857 ~/Downloads scp jdk-8u121-linux-x64.tar.gz root@hadoop100:/opt/software root@hadoop100's password: danieldu@daniels-MacBook-Pro-857 ~/Downloads
其实我在Mac上装了一个神器-Forklift。 可以通过SFTP的方式连接到远程linux。然后在操作本地电脑一样,直接把文件拖过去就行了。而且好像配置文件的编辑,也可以不用在linux下用vi,直接在Mac下用sublime远程打开就可以编辑了 :)
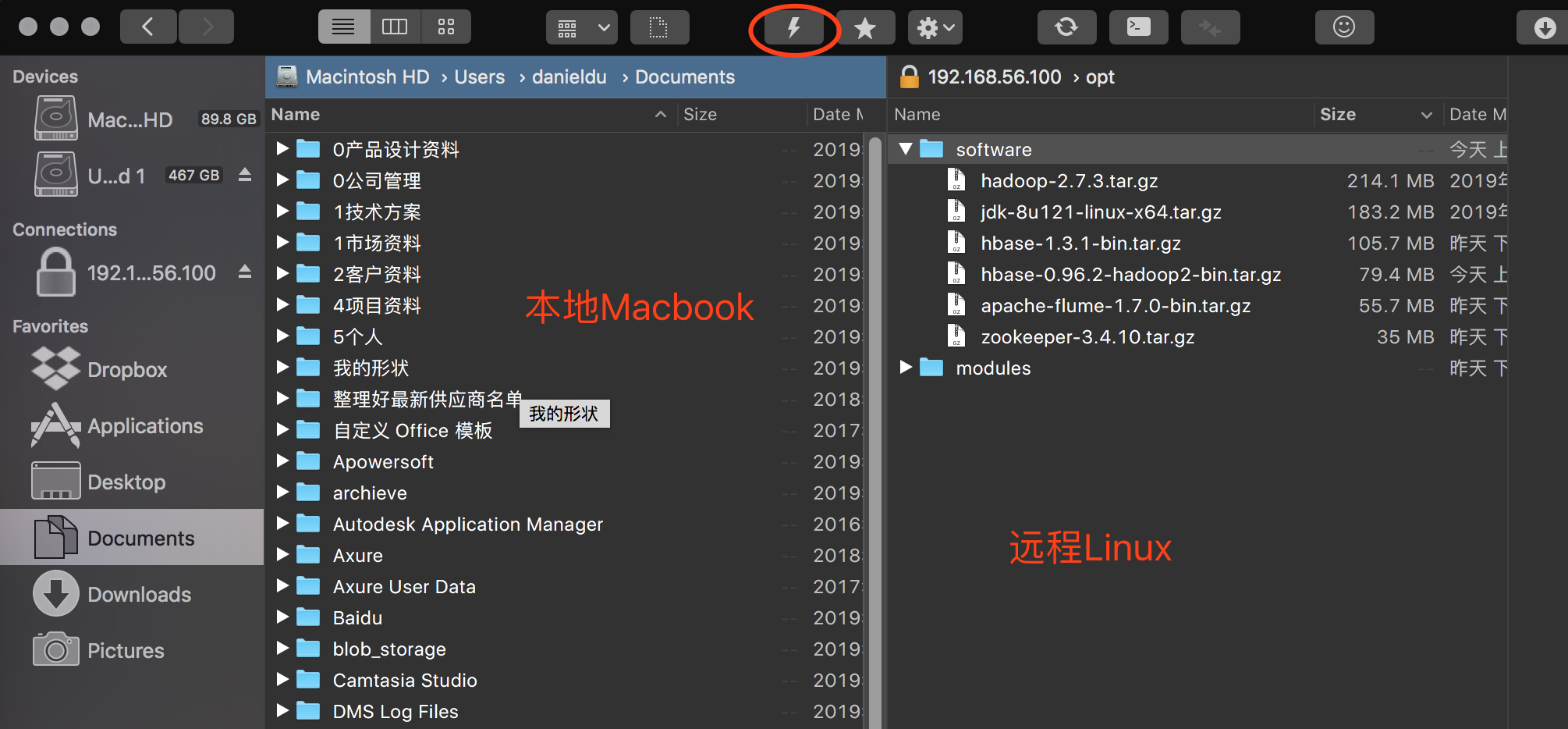
然后在linux虚拟机中(ssh 登录上去)解压缩到/opt/modules目录下
[root@hadoop100 include]# tar -zxvf /opt/software/jdk-8u121-linux-x64.tar.gz -C /opt/modules/
然后需要设置一下环境变量, 打开 /etc/profile, 添加JAVA_HOME并设置PATH用vi打开也行,或者如果你也安装了类似forklift这样的可以远程编辑文件的工具那更方便。
vi /etc/profile
按shift + G 跳到文件最后,按i切换到编辑模式,添加下面的内容,主要路径要搞对。
#JAVA_HOME export JAVA_HOME=/opt/modules/jdk1.8.0_121 export PATH=$PATH:$JAVA_HOME/bin
按ESC , 然后 :wq存盘退出。
执行下面的语句使更改生效
[root@hadoop100 include]# source /etc/profile
检查java是否安装成功。如果能看到版本信息就说明安装成功了。
[root@hadoop100 include]# java -version
java version "1.8.0_121"
Java(TM) SE Runtime Environment (build 1.8.0_121-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.121-b13, mixed mode)
[root@hadoop100 include]#
2. Hadoop安装与环境配置
Hadoop的安装也是只需要把hadoop的tar包拷贝到linux,解压,设置环境变量.然后用之前做好的xsync脚本,把更新同步到集群中的其他机器。如果你不知道xcall、xsync怎么写的。可以翻一下之前的文章。这样集群里的所有机器就都设置好了。
[root@hadoop100 include]# tar -zxvf /opt/software/hadoop-2.7.3.tar.gz -C /opt/modules/
[root@hadoop100 include]# vi /etc/profile 继续添加HADOOP_HOME
#JAVA_HOME
export JAVA_HOME=/opt/modules/jdk1.8.0_121
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/modules/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
[root@hadoop100 include]# source /etc/profile
把更改同步到集群中的其他机器
[root@hadoop100 include]# xsync /etc/profile
[root@hadoop100 include]# xcall source /etc/profile
[root@hadoop100 include]# xsync hadoop-2.7.3/
3. Hadoop分布式配置
然后需要对Hadoop集群环境进行配置。对于集群的资源配置是这样安排的,当然hadoop100显得任务重了一点 :)
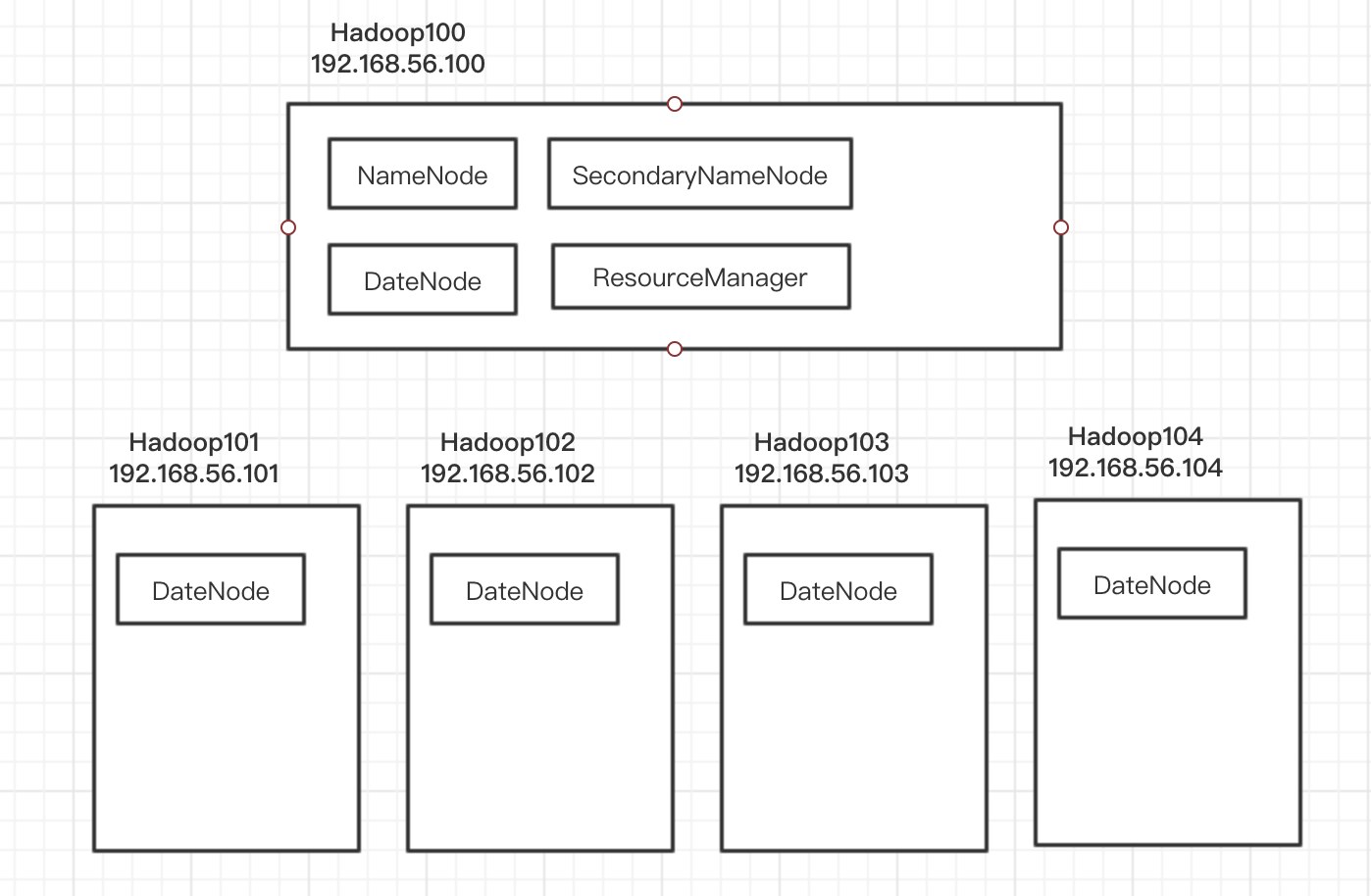
编辑0/opt/modules/hadoop-2.7.3/etc/hadoop/mapred-env.sh、yarn-env.sh、hadoop-env.sh 这几个shell文件中的JAVA_HOME,设置为真实的绝对路径。
export JAVA_HOME=/opt/modules/jdk1.8.0_121
打开编辑 /opt/modules/hadoop-2.7.3/etc/hadoop/core-site.xml, 内容如下
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop100:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/modules/hadoop-2.7.3/data/tmp</value> </property> </configuration>
编辑/opt/modules/hadoop-2.7.3/etc/hadoop/hdfs-site.xml, 指定让dfs复制5份,因为我这里有5台虚拟机组成的集群。每台机器都担当DataNode的角色。暂时也把secondary name node也放在hadoop100上,其实这里不太好,最好能和主namenode分开在不同机器上。
<configuration> <property> <name>dfs.replication</name> <value>5</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop100:50090</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>
YARN 是hadoop的集中资源管理服务,放在hadoop100上。 编辑/opt/modules/hadoop-2.7.3/etc/hadoop/yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop100</value> </property> <property> <name>yarn.log-aggregation-enbale</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration>
为了让集群能一次启动,编辑slaves文件(/opt/modules/hadoop-2.7.3/etc/hadoop/slaves),把集群中的几台机器都加入到slave文件中,一台占一行。
hadoop100
hadoop101
hadoop102
hadoop103
hadoop104
最后,在hadoop100上全部做完相关配置更改后,把相关的修改同步到集群中的其他机器
xsync hadoop-2.7.3/
在启动Hadoop之前需要format一下hadoop设置。
hdfs namenode -format
然后就可以启动hadoop了。从下面的输出过程可以看到整个集群从100到104的5台机器都已经启动起来了。通过jps可以查看当前进程。
[root@hadoop100 sbin]# ./start-dfs.sh
Starting namenodes on [hadoop100]
hadoop100: starting namenode, logging to /opt/modules/hadoop-2.7.3/logs/hadoop-root-namenode-hadoop100.out
hadoop101: starting datanode, logging to /opt/modules/hadoop-2.7.3/logs/hadoop-root-datanode-hadoop101.out
hadoop102: starting datanode, logging to /opt/modules/hadoop-2.7.3/logs/hadoop-root-datanode-hadoop102.out
hadoop100: starting datanode, logging to /opt/modules/hadoop-2.7.3/logs/hadoop-root-datanode-hadoop100.out
hadoop103: starting datanode, logging to /opt/modules/hadoop-2.7.3/logs/hadoop-root-datanode-hadoop103.out
hadoop104: starting datanode, logging to /opt/modules/hadoop-2.7.3/logs/hadoop-root-datanode-hadoop104.out
Starting secondary namenodes [hadoop100]
hadoop100: starting secondarynamenode, logging to /opt/modules/hadoop-2.7.3/logs/hadoop-root-secondarynamenode-hadoop100.out
[root@hadoop100 sbin]# jps
2945 NameNode
3187 SecondaryNameNode
3047 DataNode
3351 Jps
[root@hadoop100 sbin]# ./start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/modules/hadoop-2.7.3/logs/yarn-root-resourcemanager-hadoop100.out
hadoop103: starting nodemanager, logging to /opt/modules/hadoop-2.7.3/logs/yarn-root-nodemanager-hadoop103.out
hadoop102: starting nodemanager, logging to /opt/modules/hadoop-2.7.3/logs/yarn-root-nodemanager-hadoop102.out
hadoop104: starting nodemanager, logging to /opt/modules/hadoop-2.7.3/logs/yarn-root-nodemanager-hadoop104.out
hadoop101: starting nodemanager, logging to /opt/modules/hadoop-2.7.3/logs/yarn-root-nodemanager-hadoop101.out
hadoop100: starting nodemanager, logging to /opt/modules/hadoop-2.7.3/logs/yarn-root-nodemanager-hadoop100.out
[root@hadoop100 sbin]# jps
3408 ResourceManager
2945 NameNode
3187 SecondaryNameNode
3669 Jps
3047 DataNode
3519 NodeManager
[root@hadoop100 sbin]#
4. Hadoop的使用
使用hadoop可以通过API调用,这里先看看使用命令调用,确保hadoop环境已经正常运行了。
这中间有个小插曲,我通过下面的命令查看hdfs上面的文件时,发现连接不上。
[root@hadoop100 ~]# hadoop fs -ls ls: Call From hadoop100/192.168.56.100 to hadoop100:9000 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
后来发现,是我中间更改过前面提到的xml配置文件,忘记format了。修改配置后记得要format。
hdfs namenode -format
hdfs 文件操作
[root@hadoop100 sbin]# hadoop fs -ls / [root@hadoop100 sbin]# hadoop fs -put ~/anaconda-ks.cfg / [root@hadoop100 sbin]# hadoop fs -ls / Found 1 items -rw-r--r-- 5 root supergroup 1233 2019-09-16 16:31 /anaconda-ks.cfg [root@hadoop100 sbin]# hadoop fs -cat /anaconda-ks.cfg 文件内容 [root@hadoop100 ~]# mkdir tmp [root@hadoop100 ~]# hadoop fs -get /anaconda-ks.cfg ./tmp/ [root@hadoop100 ~]# ll tmp/ total 4 -rw-r--r--. 1 root root 1233 Sep 16 16:34 anaconda-ks.cfg
执行MapReduce程序
hadoop中指向示例的MapReduce程序,wordcount,数数在一个文件中出现的词的次数,我随便找了个anaconda-ks.cfg试了一下:
[root@hadoop100 ~]# hadoop jar /opt/modules/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /anaconda-ks.cfg ~/tmp 19/09/16 16:43:28 INFO client.RMProxy: Connecting to ResourceManager at hadoop100/192.168.56.100:8032 19/09/16 16:43:29 INFO input.FileInputFormat: Total input paths to process : 1 19/09/16 16:43:29 INFO mapreduce.JobSubmitter: number of splits:1 19/09/16 16:43:30 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1568622576365_0001 19/09/16 16:43:30 INFO impl.YarnClientImpl: Submitted application application_1568622576365_0001 19/09/16 16:43:31 INFO mapreduce.Job: The url to track the job: http://hadoop100:8088/proxy/application_1568622576365_0001/ 19/09/16 16:43:31 INFO mapreduce.Job: Running job: job_1568622576365_0001 19/09/16 16:43:49 INFO mapreduce.Job: Job job_1568622576365_0001 running in uber mode : false 19/09/16 16:43:49 INFO mapreduce.Job: map 0% reduce 0% 19/09/16 16:43:58 INFO mapreduce.Job: map 100% reduce 0% 19/09/16 16:44:10 INFO mapreduce.Job: map 100% reduce 100% 19/09/16 16:44:11 INFO mapreduce.Job: Job job_1568622576365_0001 completed successfully 19/09/16 16:44:12 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=1470 FILE: Number of bytes written=240535 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=1335 HDFS: Number of bytes written=1129 HDFS: Number of read operations=6 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Rack-local map tasks=1 Total time spent by all maps in occupied slots (ms)=6932 Total time spent by all reduces in occupied slots (ms)=7991 Total time spent by all map tasks (ms)=6932 Total time spent by all reduce tasks (ms)=7991 Total vcore-milliseconds taken by all map tasks=6932 Total vcore-milliseconds taken by all reduce tasks=7991 Total megabyte-milliseconds taken by all map tasks=7098368 Total megabyte-milliseconds taken by all reduce tasks=8182784 Map-Reduce Framework Map input records=46 Map output records=120 Map output bytes=1704 Map output materialized bytes=1470 Input split bytes=102 Combine input records=120 Combine output records=84 Reduce input groups=84 Reduce shuffle bytes=1470 Reduce input records=84 Reduce output records=84 Spilled Records=168 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=169 CPU time spent (ms)=1440 Physical memory (bytes) snapshot=300003328 Virtual memory (bytes) snapshot=4159303680 Total committed heap usage (bytes)=141471744 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=1233 File Output Format Counters Bytes Written=1129 [root@hadoop100 ~]#
在web端管理界面中可以看到对应的application:
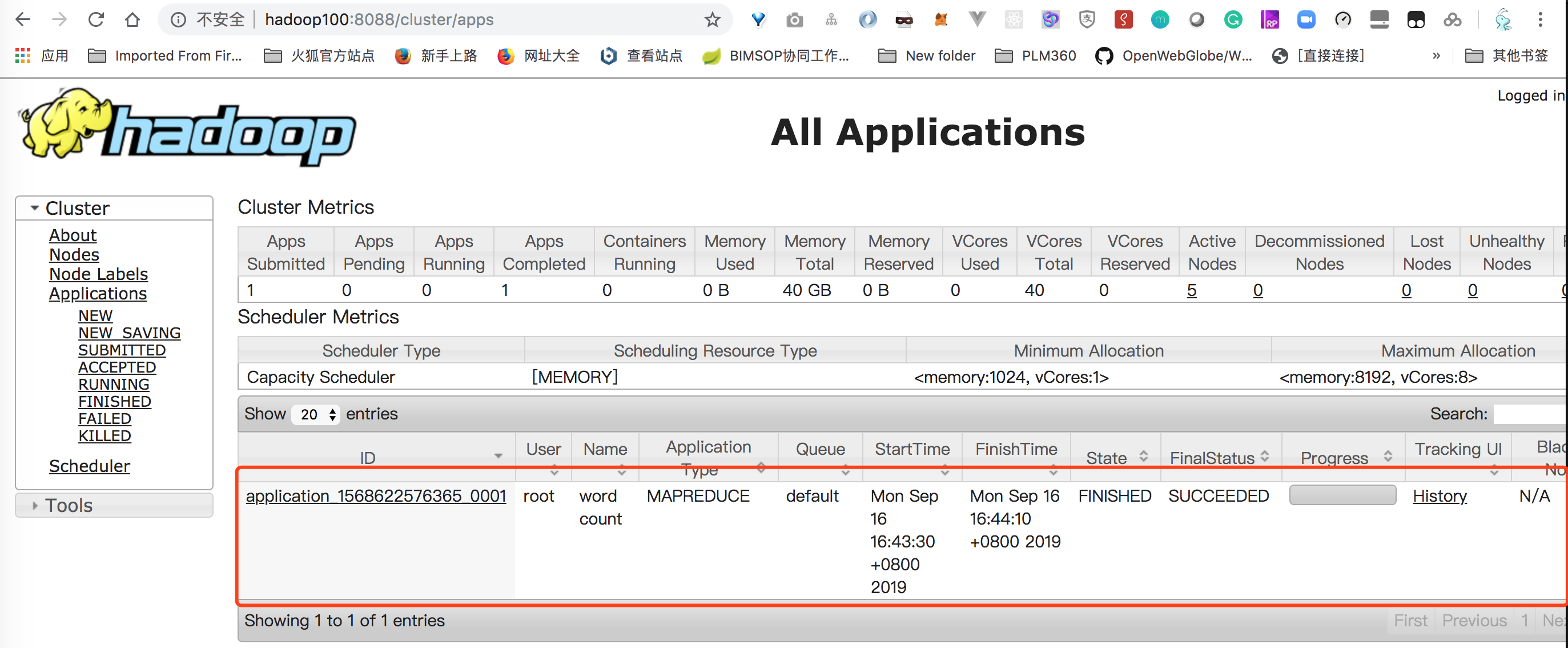
执行的结果,看到就是“#” 出现的最多,出现了12次,这也难怪,里面好多都是注释嘛。
[root@hadoop100 tmp]# hadoop fs -ls /root/tmp Found 2 items -rw-r--r-- 5 root supergroup 0 2019-09-16 16:44 /root/tmp/_SUCCESS -rw-r--r-- 5 root supergroup 1129 2019-09-16 16:44 /root/tmp/part-r-00000 [root@hadoop100 tmp]# hadoop fs -cat /root/tmp/part-r-0000 cat: `/root/tmp/part-r-0000': No such file or directory [root@hadoop100 tmp]# hadoop fs -cat /root/tmp/part-r-00000 # 12 #version=DEVEL 1 $6$JBLRSbsT070BPmiq$Of51A9N3Zjn/gZ23mLMlVs8vSEFL6ybkfJ1K1uJLAwumtkt1PaLcko1SSszN87FLlCRZsk143gLSV22Rv0zDr/ 1 %addon 1 %anaconda 1 %end 3 %packages 1 --addsupport=zh_CN.UTF-8 1 --boot-drive=sda 1 --bootproto=dhcp 1 --device=enp0s3 1 --disable 1 --disabled="chronyd" 1 --emptyok 1
。。。
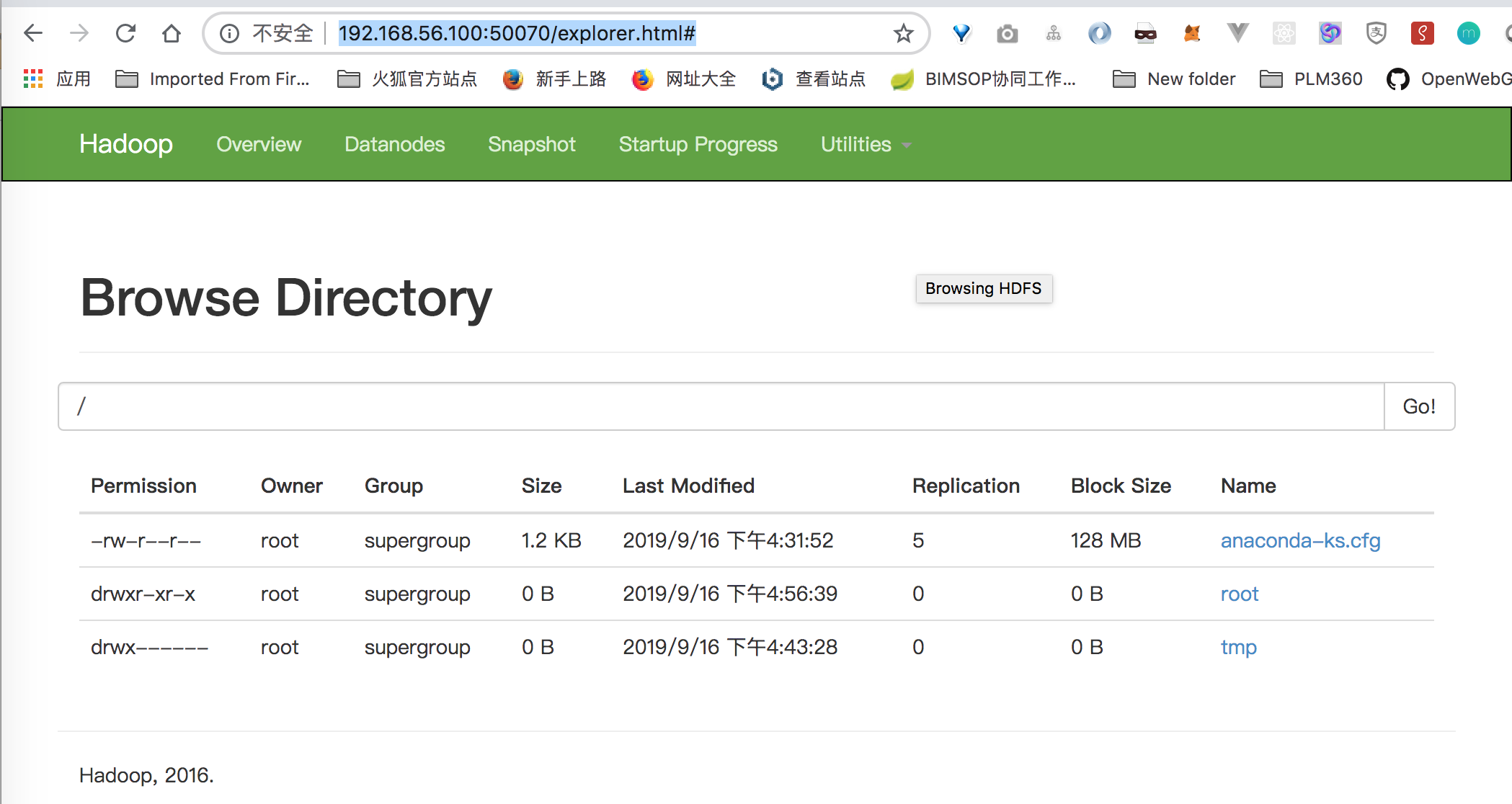
通过web 界面可以查看hdfs中的文件列表 http://192.168.56.100:50070/explorer.html#
hadoop还有好多好玩儿的东西,等待我去发现呢,过几天再来更新。