这个项目主要是一个小demo.
gzbg.txt中主要包含的是汉字中的文件,

image中存放词云展示的词云展示的样式,我们用的是个小狗的图片。templates文件中方的是我们的前端页面。upload放的是我们获取到的文件又生成的新的文件。
wordCloud_images 放入的生成的最终词云图片。test1.py是
import os import string import time import base64 import random import jieba.analyse import numpy as np import matplotlib.pyplot as plt from wordcloud import WordCloud from PIL import Image from flask import Flask, render_template, request, jsonify app = Flask(__name__) UPLOAD_FOLDER = 'upload' app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER # 设置文件上传的目标文件夹 IMAGE_FOLDER = 'wordCloud_images' app.config['IMAGE_FOLDER'] = IMAGE_FOLDER # 设置图片生成的文件 basedir = os.path.abspath(os.path.dirname(__file__)) # 获取当前项目的绝对路径 ALLOWED_EXTENSIONS = set(['txt', 'png', 'jpg', 'xls', 'JPG', 'PNG', 'xlsx', 'gif', 'GIF']) # 允许上传的文件后缀 # 生成四位随机数+文件名(路径) random_str = random.choices(string.digits, k=4) image_file = os.path.join(basedir, app.config['IMAGE_FOLDER']) new_ciyun_name = str("".join(random_str)) + str('dream.png') random_str_new = os.path.join(image_file, new_ciyun_name) print(random_str_new) # 判断文件是否合法 def allowed_file(filename): return '.' in filename and filename.rsplit('.', 1)[1] in ALLOWED_EXTENSIONS # 读取文件,返回字符串 def fileTostring(filename): with open(filename, 'r', encoding='utf-8') as f: # 文字来源 txt = f.read() # 文章内容读取为字符串 return txt # 返回读取文件内容得到的字符串 # 对字符串进行分析,应用jieba.analyse.textrank()的方法分词 def textAnalysis(txt): # 统计分析文章中每个词出现的次数 result = jieba.analyse.textrank(txt, topK=50, withWeight=True) keywords = dict() for i in result: # 遍历列表,生成字典 keywords[i[0]] = i[1] return keywords # 返回关键字与权值字典 # 绘制词云 def draw(keywords, image): graph = np.array(image) # 图片转数组 wc = WordCloud(font_path='D:/AppData/msyh.ttc', # 中文字体,未指定中文字体时词云的汉字显示为方框,可修改字体名 background_color='White', # 设置背景颜色 mask=graph, # 设置背景图片 max_font_size=240, # 设置字体最大值 scale=1.5) # 按照比例进行放大画布,如设置为1.5,则长和宽都是原来画布的1.5倍。 wc.generate_from_frequencies(keywords) plt.imshow(wc) # 负责对图像进行处理,并显示其格式,但是不能显示。 plt.axis("off") # 不显示坐标轴 #wc.to_file('dream.png') # 词云保存为图片 wc.to_file(random_str_new) # 词云保存为图片 plt.show() # 显示图像 #获取本地图片流 def return_img_stream(img_local_path): img_stream = '' with open(img_local_path, 'rb') as img_f: img_stream = img_f.read() img_stream = base64.b64encode(img_stream).decode() return img_stream @app.route("/test/upload")#定义方法 用jinjia2引擎来渲染页面,并返回一个index.html页面 def upload_test(): return render_template("index.html") @app.route('/api/upload', methods=['POST'], strict_slashes=False) def api_upload(): file_dir = os.path.join(basedir, app.config['UPLOAD_FOLDER']) # 拼接成合法文件夹地址 print(file_dir) if not os.path.exists(file_dir): os.makedirs(file_dir) # 文件夹不存在就创建 f = request.files['myfile'] # 从表单的file字段获取文件,myfile为该表单的name值 print(f.filename) if f and allowed_file(f.filename): fname = f.filename ext = fname.rsplit('.', 1)[1] # 获取文件后缀 # date_time =int(time.strftime('%Y%m%d', time.localtime(time.time())) ) # 把获取的时间转换成"年月日格式” unix_time = int(time.time()) new_filename = str(unix_time) + '.' + ext # 修改文件名 f.save(os.path.join(file_dir, new_filename)) # 保存文件到upload目录 txt = fileTostring(os.path.join(file_dir, new_filename)) # 读取文件中的文本,生成字符串 keywords = textAnalysis(txt) # 利用jieba对文本进行分词,并统计词频 image_file_three=os.path.join(basedir,'images/9.14 ball.jpg') print(image_file_three) image = Image.open(image_file_three) # 设置读取背景图片,方便修改,放当前路径images下 draw(keywords, image) # 绘制词云 img_path = random_str_new img_stream = return_img_stream(img_path) return render_template("wordCloud.html",img_stream=img_stream) else: return jsonify({"errno": 1001, "errmsg": "生成词云失败"}) if __name__ == '__main__': #定义app在8080端口运行 app.run(host='0.0.0.0',port=8080)
templates文件中的前端页面比较简单和丑,但够用了,后面可以优化。主要用到index.html和wordCloud.html
index.html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <form id="form1" method="post" action="/api/upload" enctype="multipart/form-data"> <div> <input id="File1" type="file" name="myfile"/> <!--后台代码中获取文件是通过form的name来标识的--> <input type="submit">提交</input> </div> </form> </body> </html>> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <form id="form1" method="post" action="/api/upload" enctype="multipart/form-data"> <div> <input id="File1" type="file" name="myfile"/> <!--后台代码中获取文件是通过form的name来标识的--> <input type="submit">提交</input> </div> </form> </body> </html>
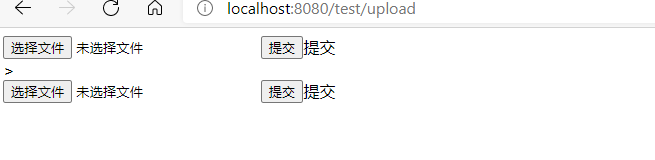
效果图
wordCloud.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Flask Show Image</title>
</head>
<body>
<img style="180px" src="data:;base64,{{ img_stream }}">
</body>
</html>
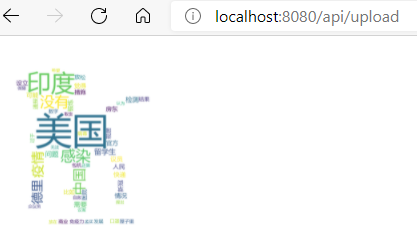
最终的效果图
注意包的引入,包如果引入错误会造成麻烦的。