前言:
做一个简单的scrapy爬虫,带大家认识一下创建scrapy的大致流程。我们就抓取扇贝上的单词书,python的高频词汇。
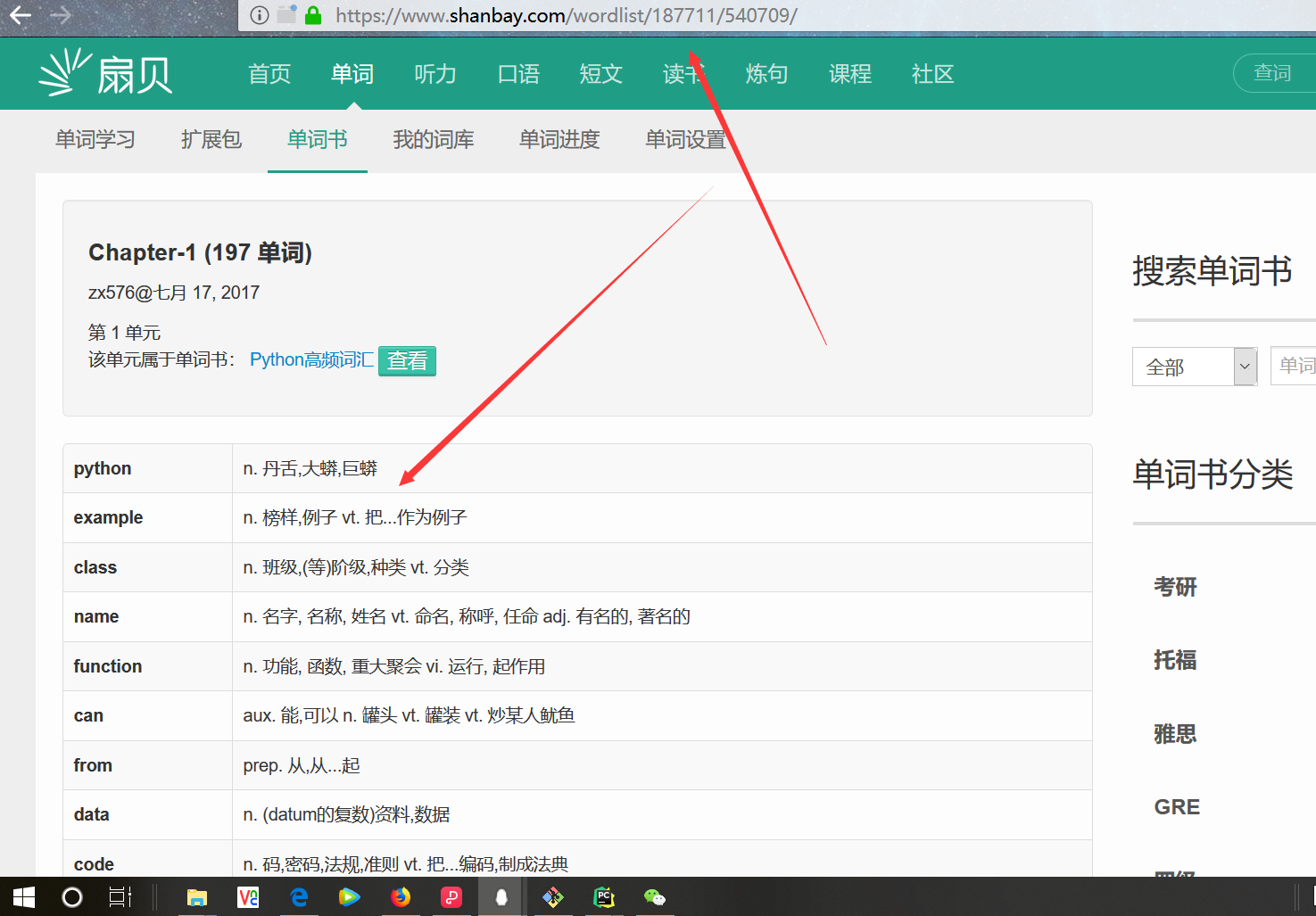
步骤:
一,新建一个工程scrapy_shanbay
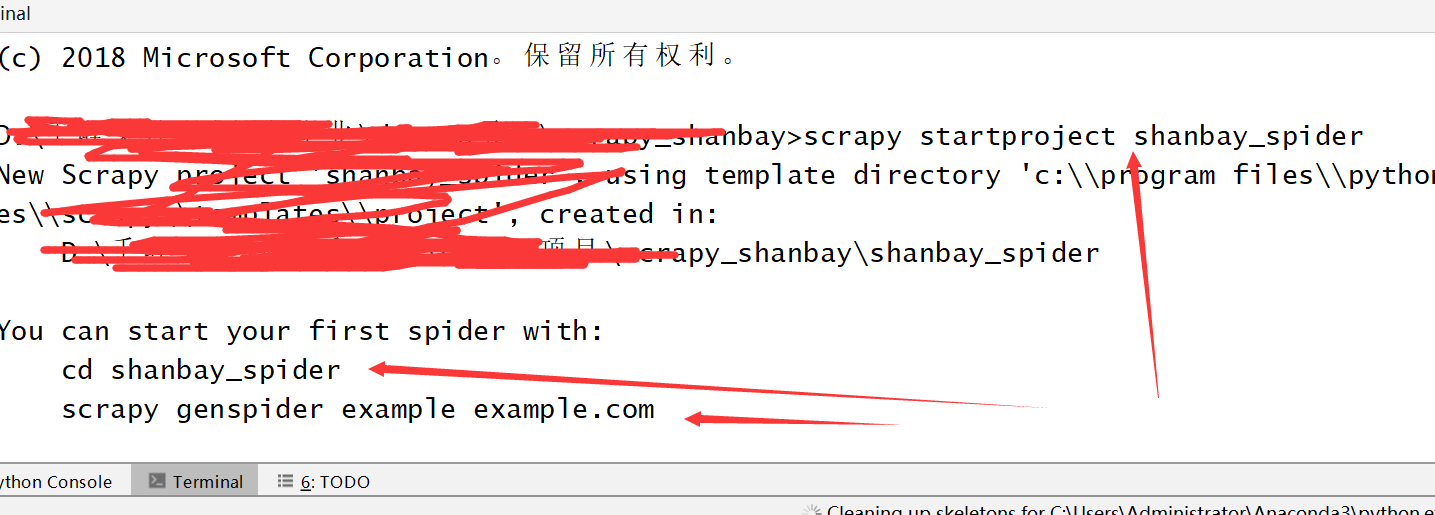
二,在工程中中新建一个爬虫项目,scrapy startproject shanbei_spider
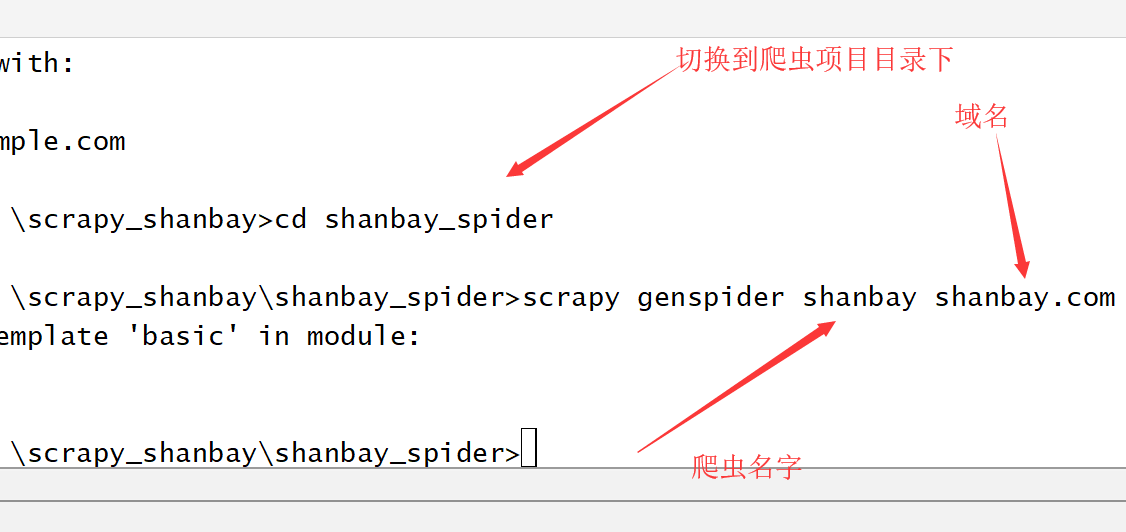
三,切入到项目目录下,然后在项目中,新建一个爬虫spider。scrapy crawl shanbay shanbay.com
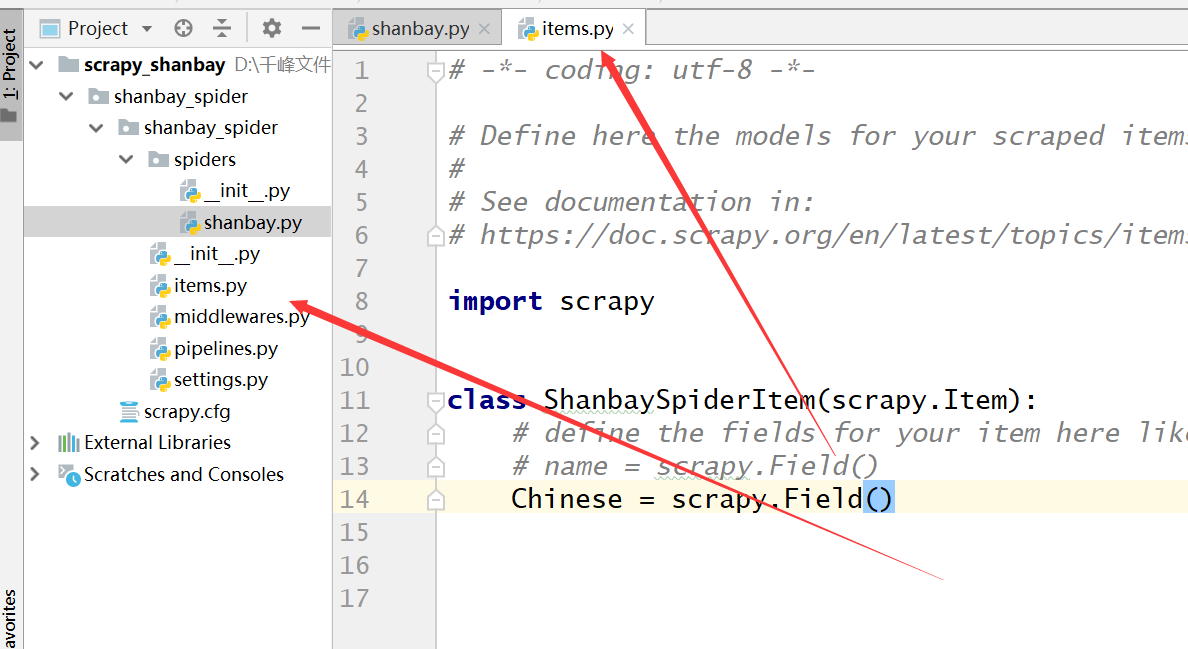
四,在item中,新建一个字段,既要获取的字段。
五,开始书写spider,里面分两部分,第一部分 start_request()主要是获取所有的url,第二部分是解析页面,获取所需要的字段,并存储。
import scrapy from scrapy.http import Request from shanbay_spider.items import ShanbaySpiderItem class ShanbaySpider(scrapy.Spider): name = 'shanbay' allowed_domains = ['shanbay.com'] # start_urls = ['http://shanbay.com/'] def start_requests(self): for i in range(29): page = 540709 + i * 3 url_base = 'https://www.shanbay.com/wordlist/187711/' + str(page) + '/?page={}' for x in range(10): url = url_base.format(x+ 1) yield Request(url,self.parse) def parse(self, response): html_contents = response.xpath('/html/body/div[3]/div/div[1]/div[2]/div/table/tbody/tr//*/text()') item = ShanbaySpiderItem() for result in html_contents: item['Chinese'] = result.extract() yield item
六,执行运行保存命令,scrapy crawl shanbay -o shanbay.csv

七,东西都保存在shanbay.csv中了
总结,其实这个非常简单,但是你用scrapy你会明显感觉到比requests快的很多。而且相比于requests库,你发现用scrapy会很简单。比较明显的一点就是你用request的话,你需要自己写个列表存放url,存进去再一个一个拿出来。再scrapy中,你只需要把url生成,然后yield request就行了,非常之方便。