1、Scrapy使用流程
1-1、使用Terminal终端创建工程,输入指令:scrapy startproject ProName

1-2、进入工程目录:cd ProName

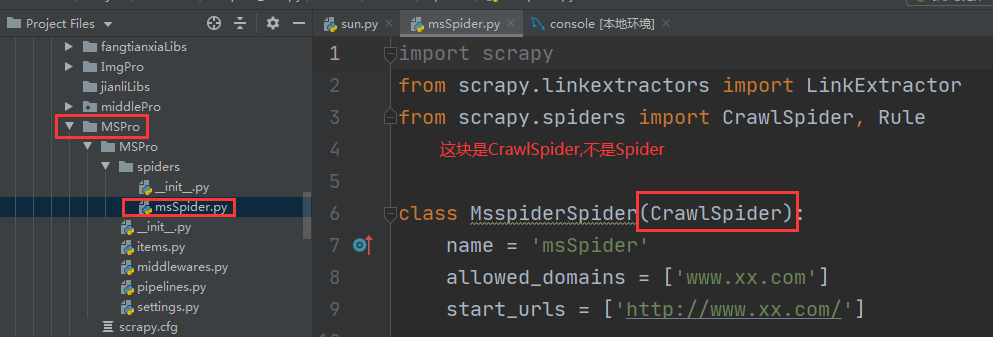
1-3、创建爬虫文件(此篇介绍使用spider下的Crawlspider 派生类新建爬虫文件 ),scrapy genspider -t craw spiderFile www.xxx.com

1-4、执行工程,scrapy crawl spiderFile (待编程结束执行此命名)
需到新建工程下执行

2、创建爬虫并编写代码
2-1、编写items.py
import scrapy
# title及状态类、时间
class MsproItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field() # 来信标题
AcceptTime = scrapy.Field() # 受理时间
status = scrapy.Field() # 受理状态
# 详情受理单位及内容
class DetailItem(scrapy.Item):
detailTitle = scrapy.Field() # 详情页标题
reviseUnit = scrapy.Field() # 受理单位
FromTime = scrapy.Field() # 来信时间
content = scrapy.Field() # 来信内容
2-2、编写Spider/msSpider.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from MSPro.items import MsproItem,DetailItem
class MsspiderSpider(CrawlSpider):
name = 'msSpider'
# allowed_domains = ['www.xx.com']
start_urls = ['http://wlwz.huizhou.gov.cn/wlwzlist.shtml?method=letters4bsznList3&reload=true&pager.offset=0']
# 链接提取器:根据指定规则(allow='正则')提取指定链接提取
link = LinkExtractor(allow=r'&pager.offset=d+')
# 提取详情页的链接
linkDetail = LinkExtractor(allow=r'&lid=d+')
# 规则提取器:将链接提取器提取的规则来进行callback解析操作
rules = (
Rule(link, callback='parse_item', follow=True),
# follow作用:可以继续将链接提取器作用到连接提取到所对应的页面中
Rule(linkDetail, callback='parse_detail')
)
# 如下两个请求方法中是不可以使用请求传参scrapy.Request
# 如何将两个方法解析的数据存储到item中,需实现两个存储items
# 在此方法中可以解析标题,受理状态
def parse_item(self, response):
# 注意:xpath中不可以存在tbody标签
trlist = response.xpath('/html/body/table//tr/td/table//tr[2]/td/table[2]//tr')
for tr in trlist:
# 标题
title = tr.xpath('./td[2]/a//text()').extract_first()
title = "".join(title).strip()
# 受理时间
AcceptTime = tr.xpath('./td[4]//text()').extract_first()
AcceptTime = "".join(AcceptTime).strip()
# 受理状态
status = tr.xpath('./td[5]//text()').extract_first().strip()
# print("来信标题:", title)
# print("受理状态:", status)
item = MsproItem()
item['title'] = title,
item['AcceptTime'] = AcceptTime,
item['status'] = status
# 提交item到管道
yield item
# 此方法解析详情页的内容及受理单位
def parse_detail(self, response):
tbodylist = response.xpath('/html/body/table//tr[2]/td/table//tr[2]/td/table[1]')
for tbody in tbodylist:
# 详情页来信主题
detailTitle = tbody.xpath('.//tr[2]/td[2]//text()').extract()
# 字符串拼接及去掉前后空格
detailTitle = "".join(detailTitle).strip()
# 受理单位
reviseUnit = tbody.xpath('.//tr[3]/td[2]//text()').extract()
# 字符串拼接及去掉前后空格
reviseUnit = "".join(reviseUnit).strip()
# 来信时间
FromTime = tbody.xpath('.//tr[3]/td[4]//text()').extract_first()
# 字符串拼接及去掉前后空格
FromTime = "".join(FromTime).strip()
# 来信内容
content = tbody.xpath('.//tr[5]/td[2]//text()').extract()
# 字符串拼接及去掉前后空格
content = "".join(content).strip()
# print("受文单位:",reviseUnit)
# print("来信内容:",content)
item = DetailItem()
item['detailTitle'] = detailTitle,
item['reviseUnit'] = reviseUnit,
item['FromTime'] = FromTime,
item['content'] = content
# 提交item到管道
yield item
2-3、编写pipelines.py
import pymysql
class MsproPipeline:
def process_item(self, item, spider):
# 如何判断item的类型
if item.__class__.__name__ == 'MsproItem':
print(item['title'][0],item['AcceptTime'][0],item['status'])
else:
print(item['detailTitle'][0],item['FromTime'][0],item['reviseUnit'][0],item['content'])
return item
# 数据写入到数据库中
class MysqlSpiderPipeline:
def __init__(self):
self.conn = None
self.cursor = None
def process_item(self, item, spider):
self.conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root', password="123456", db='qsbk',
charset='utf8')
self.cursor = self.conn.cursor()
try:
if item.__class__.__name__ == 'SunproItem':
sql = "insert into info(Title,Status,AcceptTime) values (%s,%s,%s)"
params = [(item['title'][0], item['status'], item['AcceptTime'][0])]
# 执行Sql
self.cursor.executemany(sql, params)
# 提交事物
self.conn.commit()
else:
sql = "UPDATE info Set ReviseUnit = %s,Content = %s, FromTime = %s where title = %s"
params = [(item['reviseUnit'][0],item['content'],item['FromTime'][0],item['detailTitle'][0])]
# 执行Sql
self.cursor.executemany(sql,params)
# 提交事物
self.conn.commit()
except Exception as msg:
print("插入数据失败:case%s" % msg)
self.conn.rollback()
finally:
return item
def close_sipder(self, spider):
# 关闭游标
self.cursor.close()
# 关闭数据库
self.conn.close()
2-4、编写settings文件
BOT_NAME = 'MSPro'
SPIDER_MODULES = ['MSPro.spiders']
NEWSPIDER_MODULE = 'MSPro.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'
LOG_LEVEL = 'ERROR'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
#开启管道~ 写入本地或写入数据库中
ITEM_PIPELINES = {
'MSPro.pipelines.MsproPipeline': 300,
'MSPro.pipelines.MysqlSpiderPipeline': 301,
}
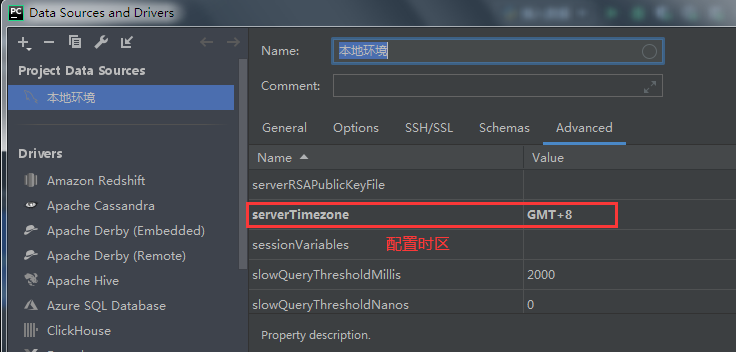
3、使用Pycharm连接MySQL数据库
3-1、连接数据库
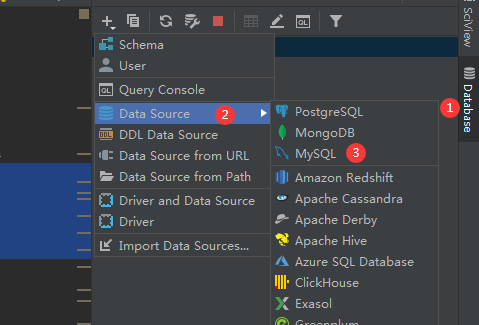
3-2、连接数据库界面操作

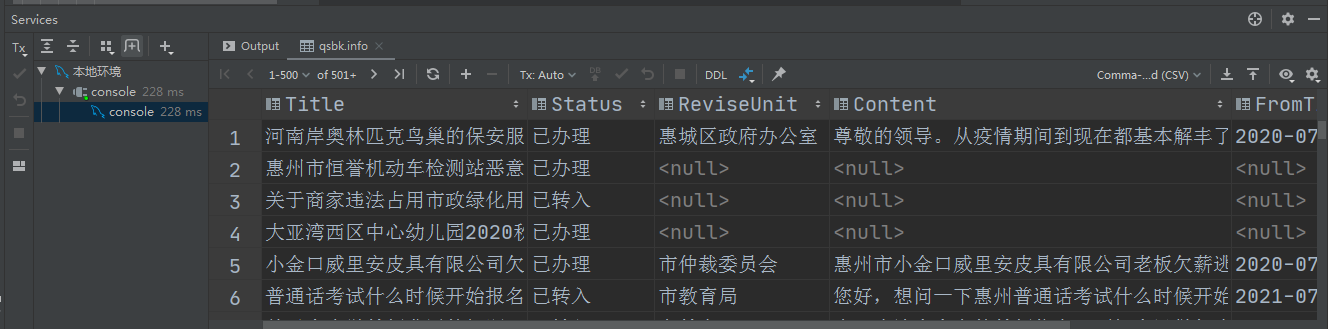
4、创建爬虫项目对应表及执行爬虫工程
4-1、创建数据库表

drop table MSBasic;
CREATE TABLE `MSBasic`
(
`id` int(100) NOT NULL AUTO_INCREMENT,
`Title` varchar(200) DEFAULT NULL,
`Status` varchar(100) DEFAULT NULL,
`ReviseUnit` varchar(200) DEFAULT NULL,
`Content` text(0) DEFAULT NULL,
`FromTime` varchar(100) DEFAULT NULL,
`AcceptTime` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`)
) engine = InnoDB
default charset = utf8mb4;
4-2、执行爬虫文件

4-3、验证爬虫结果