>>> import random #随机小数 >>> random.random() # 大于0且小于1之间的小数 0.7664338663654585 >>> random.uniform(1,3) #大于1小于3的小数 1.6270147180533838 #恒富:发红包 #随机整数 >>> random.randint(1,5) # 大于等于1且小于等于5之间的整数 >>> random.randrange(1,10,2) # 大于等于1且小于10之间的奇数 #随机选择一个返回 >>> random.choice([1,'23',[4,5]]) # #1或者23或者[4,5] #随机选择多个返回,返回的个数为函数的第二个参数 >>> random.sample([1,'23',[4,5]],2) # #列表元素任意2个组合 [[4, 5], '23'] #打乱列表顺序 >>> item=[1,3,5,7,9] >>> random.shuffle(item) # 打乱次序 >>> item [5, 1, 3, 7, 9] >>> random.shuffle(item) >>> item [5, 9, 7, 1, 3]
collections模块
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
namedtuple


>>> from collections import namedtuple >>> Point = namedtuple('Point', ['x', 'y']) >>> p = Point(1, 2) >>> p.x 1 >>> p.y 2
deque
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
from collections import deque q = deque(['a','b','c']) q.append('x') q.appendleft('y') print(q)
deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
OrderedDict
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
>>> from collections import OrderedDict >>> d = dict([('a', 1), ('b', 2), ('c', 3)]) >>> d # dict的Key是无序的 {'a': 1, 'c': 3, 'b': 2} >>> od = OrderedDict([('a', 1), ('b', 2), ('c', 3)]) >>> od # OrderedDict的Key是有序的 OrderedDict([('a', 1), ('b', 2), ('c', 3)])
注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
>>> od = OrderedDict() >>> od['z'] = 1 >>> od['y'] = 2 >>> od['x'] = 3 >>> od.keys() # 按照插入的Key的顺序返回 ['z', 'y', 'x']
defaultdict
带有默认值的字典
有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
即: {'k1': 大于66 , 'k2': 小于66}from collections import defaultdict values = [11, 22, 33,44,55,66,77,88,99,90] my_dict = defaultdict(list) for value in values: if value>66: my_dict['k1'].append(value) else: my_dict['k2'].append(value)
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict:
>>> from collections import defaultdict >>> dd = defaultdict(lambda: 'N/A') >>> dd['key1'] = 'abc' >>> dd['key1'] # key1存在 'abc' >>> dd['key2'] # key2不存在,返回默认值 'N/A'
Counter
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。Counter类和其他语言的bags或multisets很相似。
c = Counter('abcdeabcdabcaba') print c 输出:Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
时间模块
和时间有关系的我们就要用到时间模块。在使用模块之前,应该首先导入这个模块。
#常用方法 1.time.sleep(secs) (线程)推迟指定的时间运行。单位为秒。 2.time.time() 获取当前时间戳
在Python中,通常有这三种方式来表示时间:时间戳、元组(struct_time)、格式化的时间字符串:
(1)时间戳(timestamp) :通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
(2)格式化的时间字符串(Format String): ‘1999-12-06’
%y 两位数的年份表示(00-99) %Y 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-23) %I 12小时制小时数(01-12) %M 分钟数(00=59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001-366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身
(3)元组(struct_time) :struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
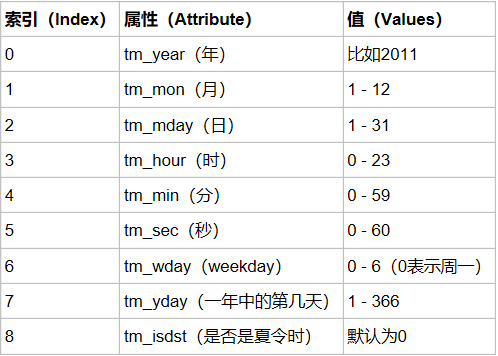
#导入时间模块 >>>import time #时间戳 >>>time.time() 1500875844.800804 #时间字符串 >>>time.strftime("%Y-%m-%d %X") '2017-07-24 13:54:37' >>>time.strftime("%Y-%m-%d %H-%M-%S") '2017-07-24 13-55-04' #时间元组:localtime将一个时间戳转换为当前时区的struct_time time.localtime() time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=13, tm_min=59, tm_sec=37, tm_wday=0, tm_yday=205, tm_isdst=0)
小结:时间戳是计算机能够识别的时间;时间字符串是人能够看懂的时间;元组则是用来操作时间的
几种格式之间的转换
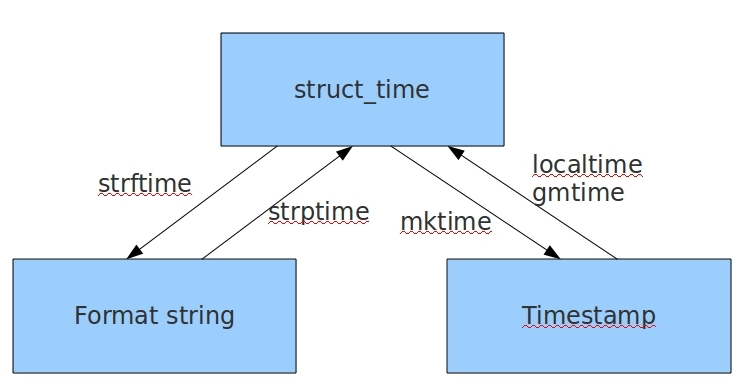
#时间戳-->结构化时间 #time.gmtime(时间戳) #UTC时间,与英国伦敦当地时间一致 #time.localtime(时间戳) #当地时间。例如我们现在在北京执行这个方法:与UTC时间相差8小时,UTC时间+8小时 = 北京时间 >>>time.gmtime(1500000000) time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=2, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) >>>time.localtime(1500000000) time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=10, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) #结构化时间-->时间戳 #time.mktime(结构化时间) >>>time_tuple = time.localtime(1500000000) >>>time.mktime(time_tuple) 1500000000.0
#结构化时间-->字符串时间 #time.strftime("格式定义","结构化时间") 结构化时间参数若不传,则显示当前时间 >>>time.strftime("%Y-%m-%d %X") '2017-07-24 14:55:36' >>>time.strftime("%Y-%m-%d",time.localtime(1500000000)) '2017-07-14' #字符串时间-->结构化时间 #time.strptime(时间字符串,字符串对应格式) >>>time.strptime("2017-03-16","%Y-%m-%d") time.struct_time(tm_year=2017, tm_mon=3, tm_mday=16, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=75, tm_isdst=-1) >>>time.strptime("07/24/2017","%m/%d/%Y") time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=0, tm_yday=205, tm_isdst=-1)
import time true_time=time.mktime(time.strptime('2017-09-11 08:30:00','%Y-%m-%d %H:%M:%S')) time_now=time.mktime(time.strptime('2017-09-12 11:00:00','%Y-%m-%d %H:%M:%S')) dif_time=time_now-true_time struct_time=time.gmtime(dif_time) print('过去了%d年%d月%d天%d小时%d分钟%d秒'%(struct_time.tm_year-1970,struct_time.tm_mon-1, struct_time.tm_mday-1,struct_time.tm_hour, struct_time.tm_min,struct_time.tm_sec))
random模块
>>> import random #随机小数 >>> random.random() # 大于0且小于1之间的小数 0.7664338663654585 >>> random.uniform(1,3) #大于1小于3的小数 1.6270147180533838 #恒富:发红包 #随机整数 >>> random.randint(1,5) # 大于等于1且小于等于5之间的整数 >>> random.randrange(1,10,2) # 大于等于1且小于10之间的奇数 #随机选择一个返回 >>> random.choice([1,'23',[4,5]]) # #1或者23或者[4,5] #随机选择多个返回,返回的个数为函数的第二个参数 >>> random.sample([1,'23',[4,5]],2) # #列表元素任意2个组合 [[4, 5], '23'] #打乱列表顺序 >>> item=[1,3,5,7,9] >>> random.shuffle(item) # 打乱次序 >>> item [5, 1, 3, 7, 9] >>> random.shuffle(item) >>> item [5, 9, 7, 1, 3]
os模块
os.makedirs('dirname1/dirname2') 可生成多层递归目录 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","newname") 重命名文件/目录 os.stat('path/filename') 获取文件/目录信息 os.system("bash command") 运行shell命令,直接显示 os.popen("bash command).read() 运行shell命令,获取执行结果 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.path os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间 os.path.getsize(path) 返回path的大小
注意:os.stat('path/filename') 获取文件/目录信息 的结构说明
stat 结构: st_mode: inode 保护模式 st_ino: inode 节点号。 st_dev: inode 驻留的设备。 st_nlink: inode 的链接数。 st_uid: 所有者的用户ID。 st_gid: 所有者的组ID。 st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。 st_atime: 上次访问的时间。 st_mtime: 最后一次修改的时间。 st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。
os.sep 输出操作系统特定的路径分隔符,win下为"\",Linux下为"/" os.linesep 输出当前平台使用的行终止符,win下为" ",Linux下为" " os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为: os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
sys模块
sys模块是与python解释器交互的一个接口
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1) sys.version 获取Python解释程序的版本信息 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称
序列化模块
什么叫序列化——将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化。
比如,我们在python代码中计算的一个数据需要给另外一段程序使用,那我们怎么给? 现在我们能想到的方法就是存在文件里,然后另一个python程序再从文件里读出来。 但是我们都知道,对于文件来说是没有字典这个概念的,所以我们只能将数据转换成字典放到文件中。 你一定会问,将字典转换成一个字符串很简单,就是str(dic)就可以办到了,为什么我们还要学习序列化模块呢? 没错序列化的过程就是从dic 变成str(dic)的过程。现在你可以通过str(dic),将一个名为dic的字典转换成一个字符串, 但是你要怎么把一个字符串转换成字典呢? 聪明的你肯定想到了eval(),如果我们将一个字符串类型的字典str_dic传给eval,就会得到一个返回的字典类型了。 eval()函数十分强大,但是eval是做什么的?e官方demo解释为:将字符串str当成有效的表达式来求值并返回计算结果。 BUT!强大的函数有代价。安全性是其最大的缺点。 想象一下,如果我们从文件中读出的不是一个数据结构,而是一句"删除文件"类似的破坏性语句,那么后果实在不堪设设想。 而使用eval就要担这个风险。 所以,我们并不推荐用eval方法来进行反序列化操作(将str转换成python中的数据结构)
序列化的目的
1、以某种存储形式使自定义对象持久化;

import json dic = {'k1':'v1','k2':'v2','k3':'v3'} str_dic = json.dumps(dic) #序列化:将一个字典转换成一个字符串 print(type(str_dic),str_dic) #<class 'str'> {"k3": "v3", "k1": "v1", "k2": "v2"} #注意,json转换完的字符串类型的字典中的字符串是由""表示的 dic2 = json.loads(str_dic) #反序列化:将一个字符串格式的字典转换成一个字典 #注意,要用json的loads功能处理的字符串类型的字典中的字符串必须由""表示 print(type(dic2),dic2) #<class 'dict'> {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'} list_dic = [1,['a','b','c'],3,{'k1':'v1','k2':'v2'}] str_dic = json.dumps(list_dic) #也可以处理嵌套的数据类型 print(type(str_dic),str_dic) #<class 'str'> [1, ["a", "b", "c"], 3, {"k1": "v1", "k2": "v2"}] list_dic2 = json.loads(str_dic) print(type(list_dic2),list_dic2) #<class 'list'> [1, ['a', 'b', 'c'], 3, {'k1': 'v1', 'k2': 'v2'}]
import json f = open('json_file','w') dic = {'k1':'v1','k2':'v2','k3':'v3'} json.dump(dic,f) #dump方法接收一个文件句柄,直接将字典转换成json字符串写入文件 f.close() f = open('json_file') dic2 = json.load(f) #load方法接收一个文件句柄,直接将文件中的json字符串转换成数据结构返回 f.close() print(type(dic2),dic2)
import json f = open('file','w') json.dump({'国籍':'中国'},f) ret = json.dumps({'国籍':'中国'}) f.write(ret+' ') json.dump({'国籍':'美国'},f,ensure_ascii=False) ret = json.dumps({'国籍':'美国'},ensure_ascii=False) f.write(ret+' ') f.close()
pickle
json & pickle 模块
用于序列化的两个模块
json,用于字符串 和 python数据类型间进行转换
pickle,用于python特有的类型 和 python的数据类型间进行转换
pickle模块提供了四个功能:dumps、dump(序列化,存)、loads(反序列化,读)、load (不仅可以序列化字典,列表...可以把python中任意的数据类型序列化)
import pickle dic = {'k1':'v1','k2':'v2','k3':'v3'} str_dic = pickle.dumps(dic) print(str_dic) #一串二进制内容 dic2 = pickle.loads(str_dic) print(dic2) #字典 import time struct_time = time.localtime(1000000000) print(struct_time) f = open('pickle_file','wb') pickle.dump(struct_time,f) f.close() f = open('pickle_file','rb') struct_time2 = pickle.load(f) print(struct_time2.tm_year)