登录CM
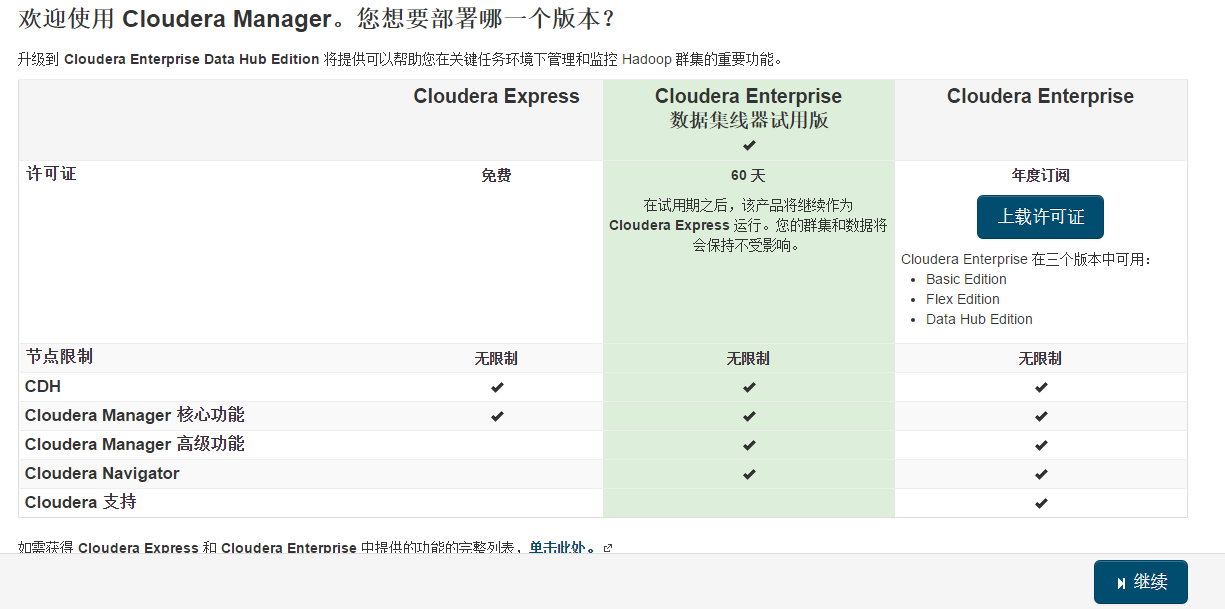
1、版本选择
免费版本的CM5已经去除50个节点数量的限制。
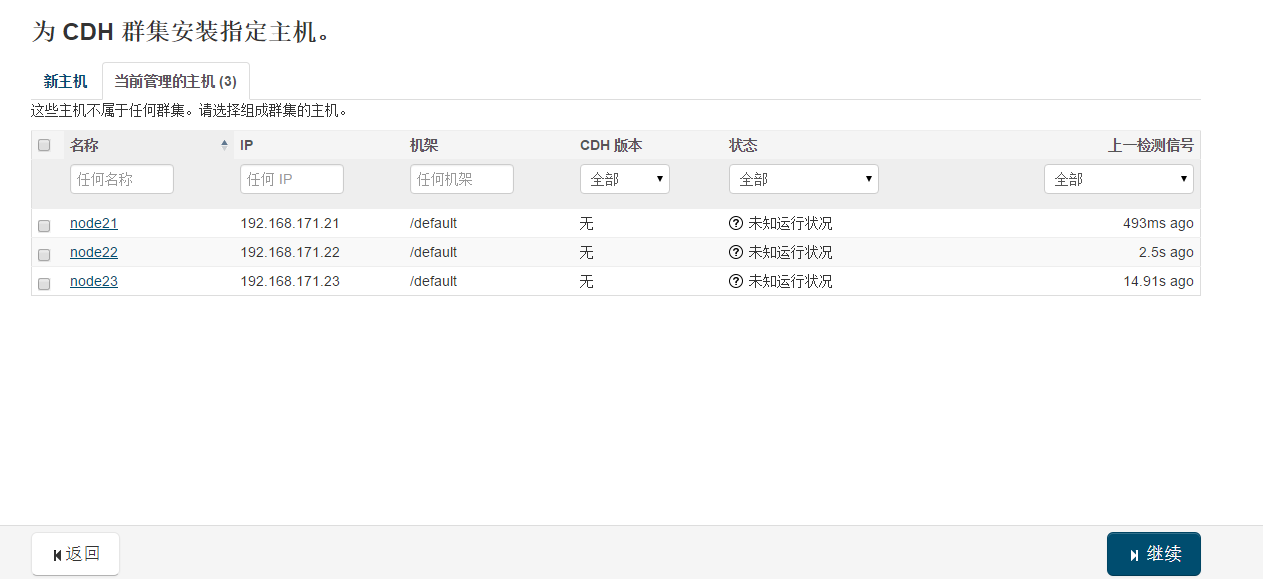
各个Agent节点正常启动后,可以在当前管理的主机列表中看到对应的节点。
选择要安装的节点,点继续。
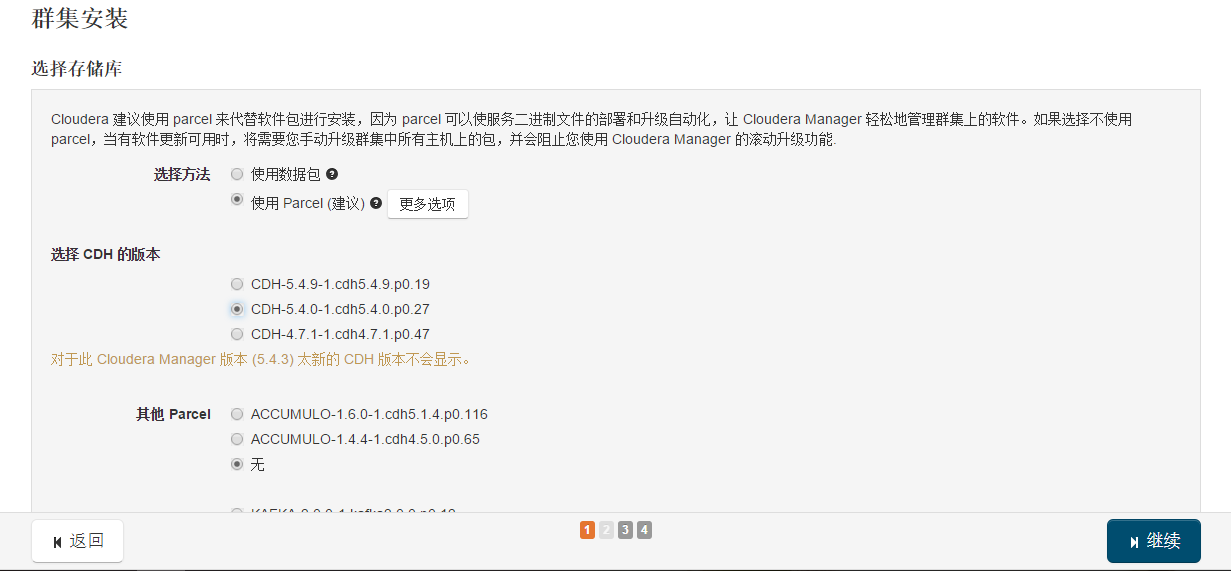
接下来,出现以下包名,说明本地Parcel包配置无误,直接点继续就可以了。
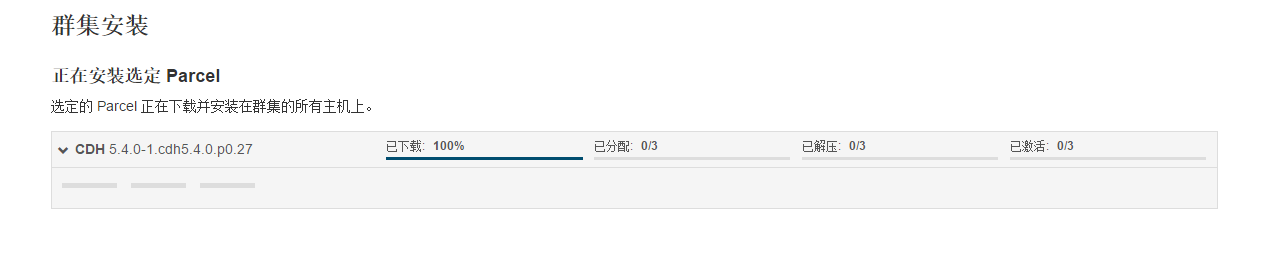
点击,继续,如果配置本地Parcel包无误,那么下图中的已下载,应该是瞬间就完成了,然后就是耐心等待分配过程就行了,大约10多分钟吧,取决于内网网速。
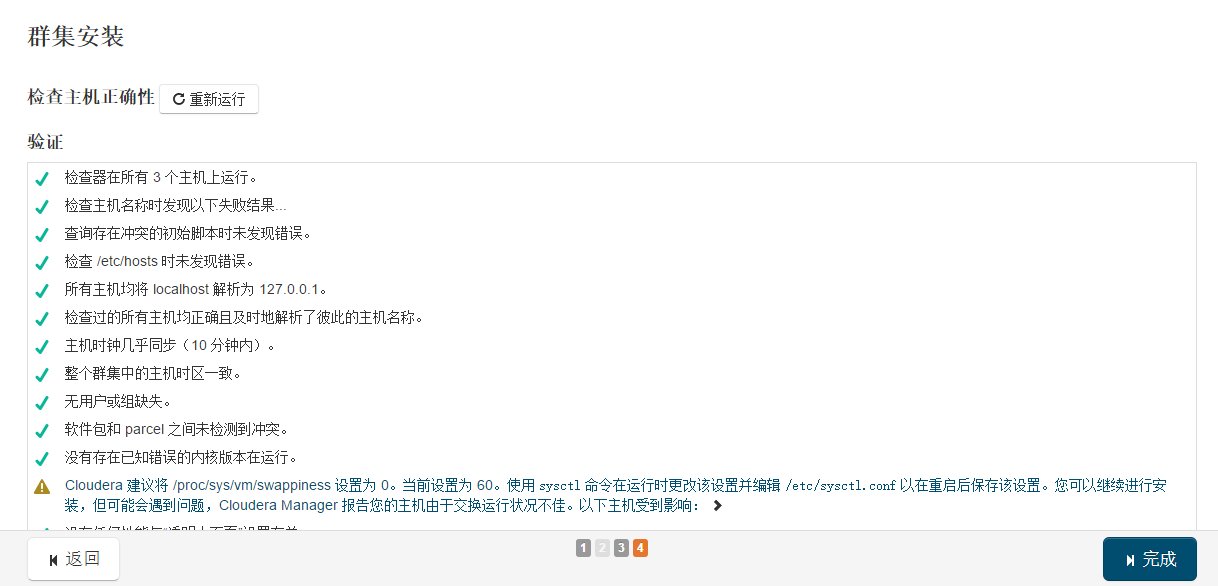
接下来是服务器检查,可能会遇到以下问题:
Cloudera 建议将 /proc/sys/vm/swappiness 设置为 0。当前设置为 60。使用 sysctl 命令在运行时更改该设置并编辑 /etc/sysctl.conf 以在重启后保存该设置。您可以继续进行安装,但可能会遇到问题,Cloudera Manager 报告您的主机由于交换运行状况不佳。以下主机受到影响:
通过echo 0 > /proc/sys/vm/swappiness即可解决。
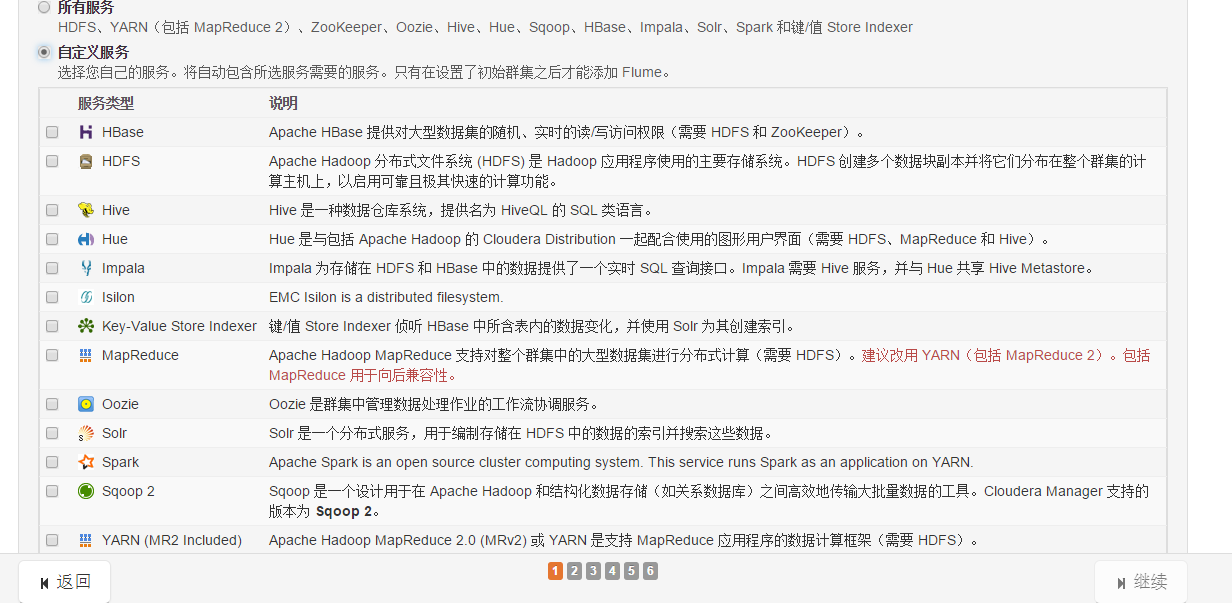
接下来是选择安装服务
服务配置,一般情况下保持默认就可以了(Cloudera Manager会根据机器的配置自动进行配置,如果需要特殊调整,自行进行设置就可以了):

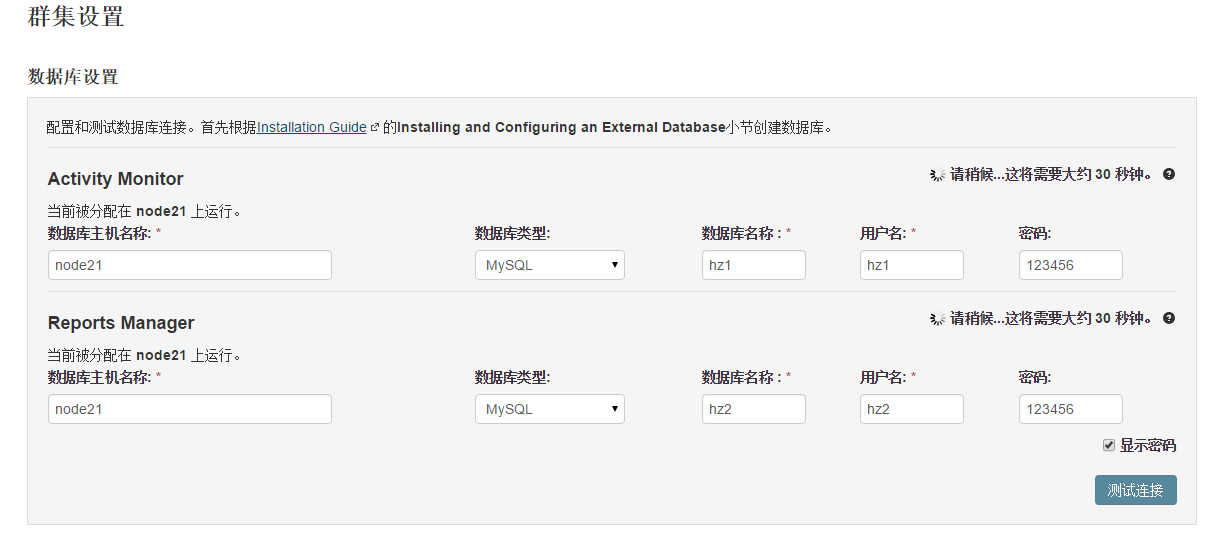
接下来是数据库的设置,检查通过后就可以进行下一步的操作了
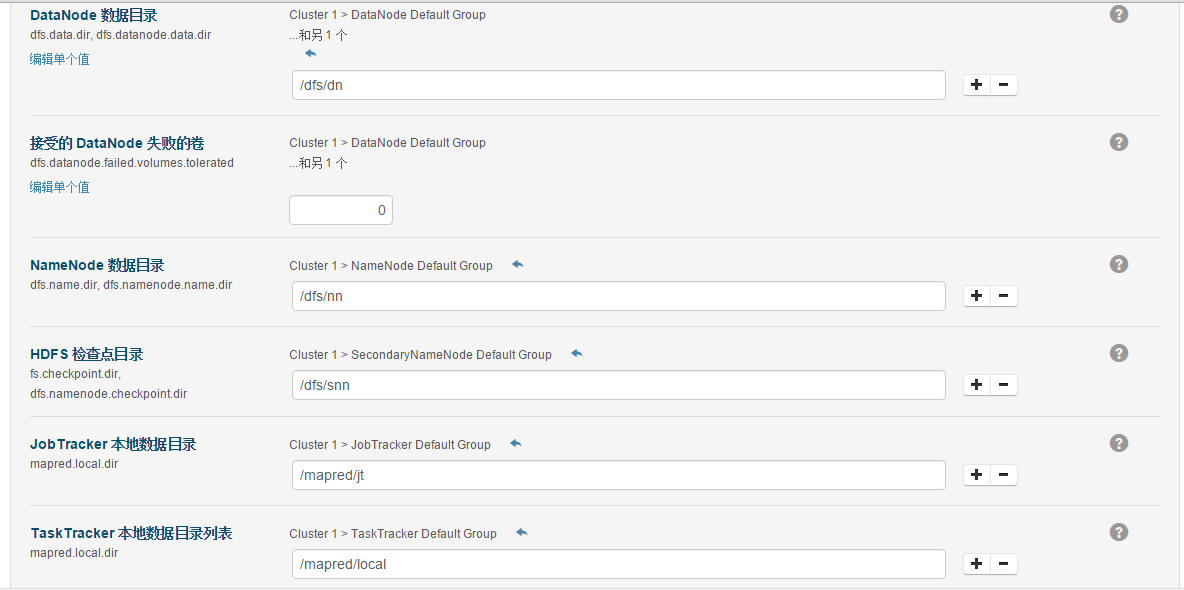
下面是集群设置的审查页面,我这里都是保持默认配置的
终于到安装各个服务的地方了,注意,如果采用其他数据库安装Hive等组件的时候报错,检查之前配置CM Server数据库时,jar包拷贝位置及名称是否修改
服务的安装过程大约半小时内就可以完成
安装完成后,就可以进入集群界面看一下集群的当前状况了。
这里可能会出现无法发出查询:对 Service Monitor 的请求超时的错误提示,如果各个组件安装没有问题,一般是因为服务器比较卡导致的,过一会刷新一下页面就好了

目前企业首先有一套关系数据库组成的数仓,久而久之,将历史数据迁入大数据平台进行统计分析。
spark并不是完全的内存计算,如果要完全发挥spark的效能,需要物理机有足够大的内存才行:
一般会有以下几类集群:
离线计算集群-hadoop集群
实时计算集群-spark集群
流式计算集群-storm集群
查询集群-hbase集群
参考: