软件在发布后,收到了各方朋友的反馈和提问。此处统一对一部分问题作出回复。
感谢你使用Hawk,软件是我写的,坑是我挖的。做爬虫本来就比较复杂,一些公司有专门的程序员做爬虫工程师。因此如果你很沮丧,很有可能是网站做了不少策略,确实很难爬。哎,这也是没有办法的事情。
闲话不说,进入正题。
1.自动嗅探失败
网页采集器具备自动嗅探功能,本质上是替换掉了底层的代理。因此,所有的请求都通过Hawk内部,自然就能根据需求筛选出所需的请求。
但有些系统中安装了类似360等工具,会拒绝这类操作。导致嗅探失败。目前原因还没有找到。一些网站做了加密,因此即使输入检索字段,内容也不一定能检索得到。
即使嗅探失败也没有关系,如果你使用Chrome等浏览器,进入开发者工具(F12):
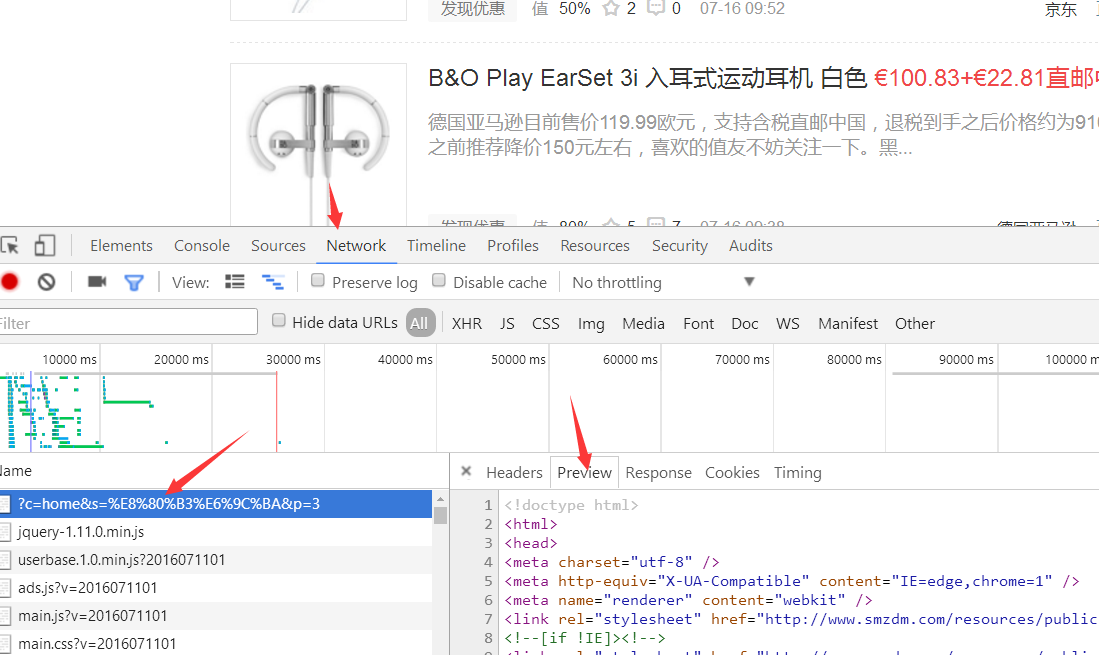
选择最上角的network卷展栏,之后刷新网页,chrome会列出所有的请求,一般最上面的就是真实请求:

点击view source,将所有文本,拷贝到网页采集器,对应的高级设置-请求参数里即可。其实,Hawk做的也是类似的操作。
2.被封锁问题
被封锁有几个原因:
2.1 被网站识别为非浏览器
出现这种情况的原因是请求参数为空,没有模拟为浏览器(user-agent),如大众点评只防此类爬虫。
最新改进的版本中,Hawk默认请求参数已经加入了user-agent,因此能解决掉一大部分初级问题。
2.2 频繁访问
这取决于网站如何认定是同一个使用者。
- 有的网站认为同一台机器的不同浏览器也是不同的用户。
- 有的网站认为只要IP相同,则使用者一定相同
对前一种情况,可以随机在一大批User-agent列表中挑选一条,模拟为不同的浏览器,就能大大降低被PB的概率。典型的例子如豆瓣。
对后一种情况,很不幸需要使用真正的代理,或使用分布式方案。免费代理通常都不稳定,而付费代理则需要付费,很少有人愿意为了爬虫付钱(一脸黑线)。
因此,Hawk会考虑提供第一种情况的解决方案,但不会自动开启,而是在用户需要的时候手工开启。
而自动代理切换,目前Hawk不会提供支持。原因更多考虑的是技术之外的因素。
3.抓取动态请求
这是被问的最多的问题。加载一个完整的网页,可能需要几十次请求,不少请求是ajax和动态的,而不少数据都保存在这些请求之中。
最早版本的Hawk内置了一个IE内核的浏览器,后来取消了这个功能。原因很简单:
- 内置浏览器,导致过分复杂
- 无法多线程抓取
- 大量无用的请求,导致抓取速度变慢
- 即使内置浏览器,也不见得能抓取所有动态请求
因此,纯HttpClient能够精确并只抓取你想要的内容,只要正确构造它即可。
如何使用?你需要配置一个网页采集器。
将它的行为,模拟到和浏览器一致。
第一种方法,查看浏览器的请求,参考本文的第一条方法,将请求详情复制过来,注意选择GET和POST。
之后,将嗅探到的地址拷贝到网页采集器的URL输入框中,查看是否能正确获取内容。
如果是POST请求,就更复杂一些。在数据清洗模块中,网页采集器拖入的列需要是对应的URL,你还需要构造出每次访问的post数据,单独作为一列。在网页采集器中如下配置:
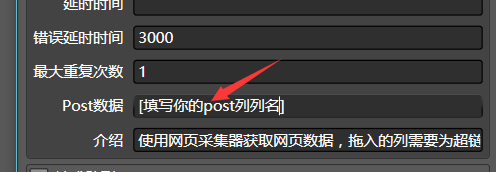
注意列名需要用方括号括起来,否则每次POST数据都会是所填的数据。
第二种方法,自动嗅探,下一篇文章我们去抓淘宝,该文章会详细介绍如何使用自动嗅探来模拟动态请求。
4.分布式方案
真正的爬虫是分布式的。用客户端去抓取,只适合于小打小闹的场合。后来的实际情况也证明了这点,分布式能够充分利用网络带宽,将任务分配到不同地域的计算机上,还能避免被封锁。
Hawk当然没有支持分布式方案,但我完成的etlpy已经初步具备了这个功能。但是因为恼人的Python和C#的XPath兼容性问题,我一直不能保证Hawk生成的xml一定被etlpy解析。
同样,etlpy做了非常大的变动,之前为了节省几行代码而使用的诡异的FP的风格被我改成了OO。etlpy是我重点发展的方向,Hawk在未来的发展并不明朗,也许不会继续做大的维护了。因为目前来看,C#可能在我之后的工作生涯中都不会使用了。
5.验证码问题
这也是问的非常多的问题,很不幸,不支持。验证码各种各样,简单到纯数字,复杂到12306,图像转文本涉及到太多的不确定因素。
解决方案也有,一些网站提供识别验证码的接口API,因此你可以让Hawk去模拟网站的API,将图片地址传递过去,API会自动返回验证码。坏消息是这个一般需要收费。
不过,能配置Hawk去做这样的请求的人,一定也能够写Python了,算了,他还是去写Python吧,别跳Hawk这个坑了。
6.XPath搜索相关问题
网页采集器中,填写关键字,却发现无法找到XPath。
可能的原因:
网页是动态网页
因此本链接不包含该关键字,建议考虑使用嗅探方案
关键字太长
是文本中包含不可见字符时经常出现。例如 340[制表符]万,但用户可能会直接输入340万。Hawk搜索是按照严格字符串匹配的,就会匹配不成功,因此输入短一些,如340
和 Chrome等浏览器得到的XPath不同
一方面,XPath的表示方法有很多种,这和正则类似。可能看起来不一样的XPath指代的都是同一个节点。
另一方面,Chrome会执行js代码,而js可能会改变网页的结构,因此XPath也就对应地发生变化了。这会通常会导致从Chrome拷贝出来的XPath在Hawk中不能使用。
Hawk未来不会考虑支持加入执行js代码的功能,因此,如果搜索XPath,还请以Hawk得到的结果为准。多搜多看,通常就能建立感觉。
7. 手气不错的问题
很多人使用手气不错会失败。这是因为:
不是所有的网页都支持直接点击【手气不错】
手气不错需要特定的网页结构(列表),如果整个网页没有显著的列表节点,则搜索失败,此时就会提示 手气不错失败。
手气不错会自动规约父节点
使用手气不错后,嗅探器会找到列表节点的父节点,以及挂载在父节点上的多个子节点,从而形成一个树状结构
有时候,父节点的xpath是不稳定的,举个例子,北京上海的二手房页面,上海会在列表上面增加一个广告banner,从而真正的父节点就会发生变化。为了应对这种变化,通常的做法是手工修改【父节点XPath】,继续举例子,父节点的id为house_list,且在网页中全局唯一,你就可以使用另外一种父节点表示法//*[@id='house_list'](写法可以参考其他XPath教程),而子节点表达式不变。
Hawk在【手气不错】得到【确定】后,会询问是否提取父节点XPath,此时Hawk会自动提取【父节点XPath】到属性对话框中,从而方便修改。
8.下一步计划
- 在右侧界面右键添加连接器,如果配置不正确可能会造成闪退,已经修复。
- 增加自动切换User-agent的功能
- 优化用户体验设计。
有任何问题,欢迎邮箱联系buptzym@qq.com