注意:
- es版本至少6.1以上
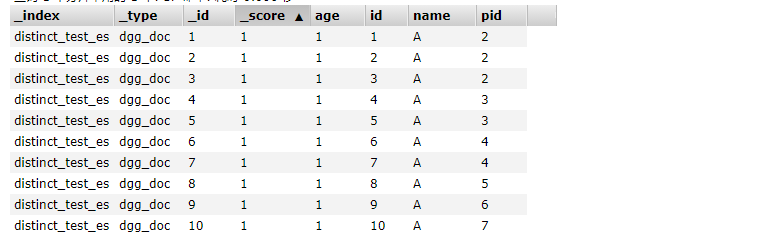
先看一下es存储的数据情况,我们需要通过pid去重并且实现分页
先贴出Es的代码
{
// 这里是对hits的数据进行限制只返回一条数据,因为我不要这里的数据,所以避免数据过多就直接返回最小
"from":0,
"size":1,
"query":{
"match_all":{
"boost":1
}
},
"aggregations":{
"agg":{
"terms":{
"field":"pid",
//这里代表聚合查询出多少条数据,注意这里的size要比最下面分页的size要大,因为是对聚合后的数据分页,如果不写的话默认是10
"size":10
},
"aggregations":{
"top":{
"top_hits":{
"from":0,
// 这里的size表示重复的返回几条,这里我们返回1
"size":1,
"version":false,
"seq_no_primary_term":false,
"explain":false,
"_source":{
"includes":[
// 这个是需要返回的字段
"pid"
],
"excludes":[
]
}
}
},
"bucket_field":{
"bucket_sort":{
"sort":[
],
// 这里是聚合分页从第几页开始,每页多少条(举个列子第一页(0,10),第二页就是(10,20))
"from":0,
"size":10
}
}
}
}
}
}
Java 代码
//构造查询器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//查询条件查询所有
QueryBuilder queryBuilders = QueryBuilders.matchAllQuery();
// 需要返回字段的集合
String[] param= {"pid"};
// 对需要返回的数据包括哪些,不包括哪些,重复的只返回1条
TopHitsAggregationBuilder top1 = AggregationBuilders.topHits("top").fetchSource(param, Strings.EMPTY_ARRAY).size(1);
// 通过pid聚合并且聚合后返回10条数据,注意这里的size(这里代表聚合查询出多少条数据,注意这里的size要比最下面分页的size要大,因为是对聚合后的数据分页,如果不写的话默认是10)
TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms("agg").field("pid").subAggregation(top1).size(10);
// 聚合分页
termsAggregationBuilder.subAggregation(new BucketSortPipelineAggregationBuilder("bucket_field",null).from(0).size(10));
// 这里的.from(0).size(1) 表示最外层hits返回的数据
searchSourceBuilder.query(queryBuilders).aggregation(termsAggregationBuilder).from(0).size(1);
//解析返回的数据
SearchResponse response = getSearchResponse(searchSourceBuilder);
Terms agg = response.getAggregations().get("agg");
for (Terms.Bucket bucket : agg.getBuckets()) {
TopHits top = bucket.getAggregations().get("top");
for (SearchHit searchHit : top.getHits()) {
System.out.println(searchHit.getSourceAsMap());
}
}
// 执行查询并且返回response
private SearchResponse getSearchResponse(SearchSourceBuilder searchSourceBuilder) {
// 注入自己的es进行查询
SearchResponse response = esTemplate.query("distinct_test_es","dgg_doc", searchSourceBuilder);
return response;
}
最后结果为已去重,并且可以分页