1. P4 CPU 结构
奔4处理器是Intel的经典之作,它是采用乱序执行内核的超标量处理器。P4采用的微架构称为 Net Burst,基本结构如下:
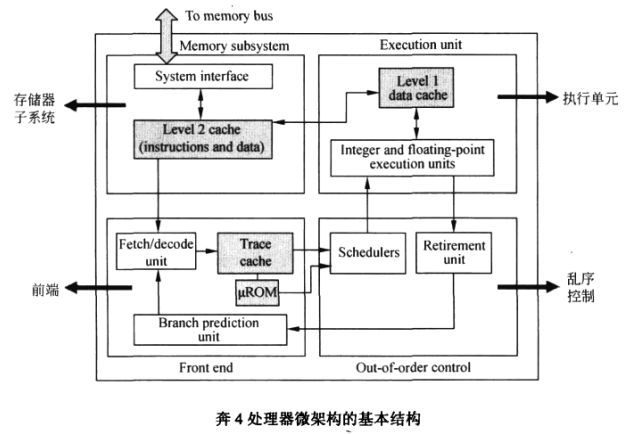
奔4处理器微架构被分成了4大部分:
(1)存储子系统( Memory subsystem)。
(2)前端( Front end)
(3)乱序控制( Out-of-order control)
(4)执行单元( Execution unit)。
存储子系统包含了片内的 Cache,Cache是处理器内部的存储单元,存储指令和数据。Cache也是微架构的重要组成部分,不过相对比较独立,留待下章细说。
指令在处理器内部的执行过程,可以分为前端和后端,前端准备指令,后端执行指令。前端包括取指、译码、分支预测等单元,后端包括执行单元和乱序控制。
执行单元的工作就是傻呼呼的运算,而指令的乱序调度交给了乱序控制部分。
2.译码:
在x86处理器中,译码单元的工作就是将x86指令翻译成类似RIsC的 micro operations(微操作),简称uop。
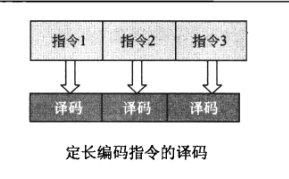
P4是超标量处理器,一次能处理多条指令,自然也要一次对多条指令进行译码。对于定长编码的指令,每条指令的bit数是固定的,多增加几套译码电路就能实现多条指令并行的译码,如下图所示:
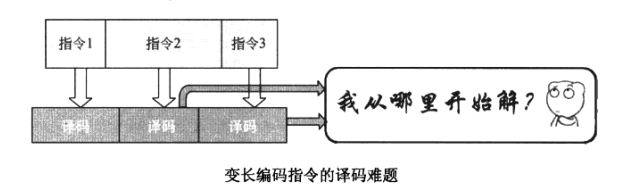
不过,x86指令是变长编码的,指令长度从1~15 bytes不等,根本就不知道哪几个bytes是第一条指令的,哪几个 bytes是第二条指令的,也就无从解起。
在AMD的处理器中,通常采用预译码( Predecode)的方式来解决这个难题,指令从内存读入到 Cache中时,就开始预解码,得出预译码标识,预译码标识包括指令的起始位置、需要译出的uop数目、操作码等信息。预译码标识连同指令一起存储在指令 Cache中,在正式译码时工作难度就减轻了。
Inte的处理器则采用多级译码流水线的方式来实现译码。第一级先检测出指令的起始和结束位置,第二级将指令解码为uop。
一条x86 CISC指令通常对应多条uop。当一条CISC指令生成的uop数目多于4条时,就将这些CISC指令对应的uop存储在 micro-ROM(uROM)中,解码时使用査表的方式从 micro-ROM中得到,这样就简化了复杂指令的译码过程。
3. Trace cache
在P4处理器中,解码后的uop被存储在 Trace Cache中。这个 Trace Cache和一般的Cache有点不一样,在一般的 Cache中,指令的存储顺序和内存中的指令顺序是一样的,而 Trace Cache中的指令顺序是指令的执行顺序,而不是指令的地址顺序。
下面这个程序中,包含有跳转指令:

指令在普通 Cache上存放的位置根据程序地址决定,指令这样存储:
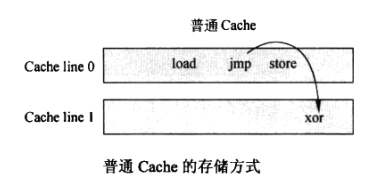
而在Trace Cache中,指令的存储方式如下:

在P4中,一个 Trace Cache line包含6条uop。
Trace Cache与传统 Cache有两点不同:
(1) Trace Cache存储的是译码之后的微操作,而不是x86指令。这样执行循环代码时,就省了指令的译码过程。
(2) Trace Cache存储的微操作是按照执行顺序存储的,而不是指令顺序。在超标量处理器中一次取多条指令时,减少了 Cache line的访问。
4.前端流水线
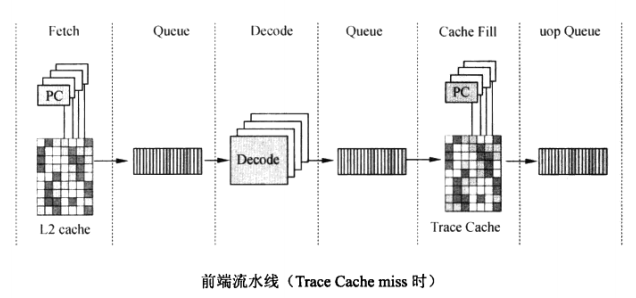
一开始,前端从L2 Cache中读指令,一次读64bit,取好的指令放在一个队列( Queue)中,也即Buffer中,前面我们有谈到Buer的作用,它隔离了前后两个步骤,并对速度进行了平滑。Decode单元从队列中取指令进行译码,译码后的指令也放在一个队列中,然后
再按照uop的执行顺序放在 Trace Cache中,然后再从 Trace Cache中取出uop放在 uop Queue中, uop queue为连接前端和后端的桥梁。
当uop已经在 Trace Cache中时,就不需要再从L2中取指令了,直接从Trace Cache中取uop即可。所需的指令在 Trace Cache中时,称为 Trace Cache hit(命中),所需的指令不在Trace Cache中时,称为 Trace Cache miss(未命中)。 Trace Cache hit时的前端流水线就简化为:
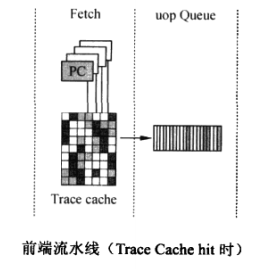
除了这些基本的模块之外,处理器在根据地址取指令时,需要进行虚地址、实地址转换,使用到TLB( Translation Lookaside Buffer);P4处理器中,有两个分支预测单元,一个用于预测指令的执行路径;另一个用于预测uop的执行路径。
5. 后端流水线
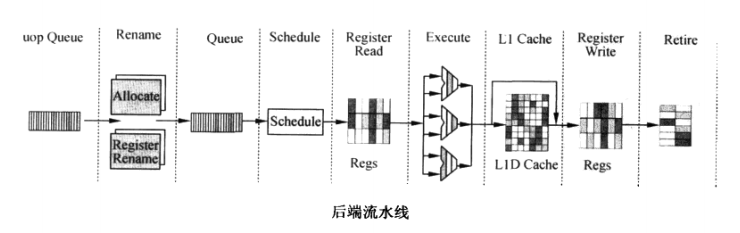
后端和前端的桥梁就是 uop Queue,当uop进入后端时,首先要进行资源的分配( Allocate),处理器内部拥有大量的 Buffer用于调度,每条进来的uoop要占一个位置,如它需要在ROB( Re-order Buffer)中有一个位置,逻辑寄存器需要使用到物理寄存器,内存操作需要使用到Load/ Store Buffer等,如果资源不可用,Allocate就处于等待。然后uop会被寄存器重命名,在p4处理器中,8个通用寄存器能使用128个物理寄存器,逻辑寄存器和物理寄存器之间的映射关系被保存在RAT( Register Alias Table)中。
指令的调度(Schedule)是乱序执行内核的核心,调度器根据uop操作数的准备情况和执行单元的准备情况决定uop什么时候开始执行。内存的访问和ALU指令的运算分别放在不同的队列中。
调度器连接了4个 Dispatch Ports(分派口),不同类型的指令由不同的 Dispatch Port分派,如下图所示:
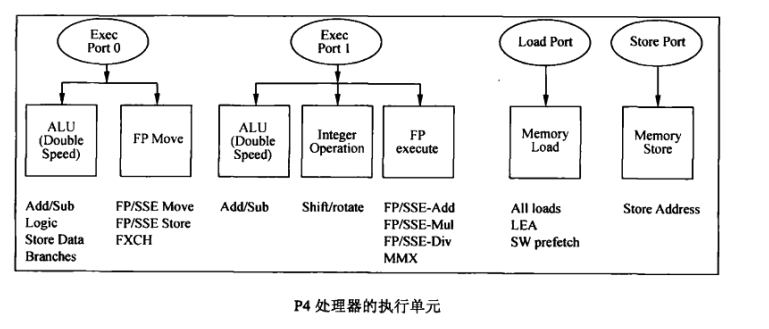
Exec Port0和 Exec Port1用于分派 ALU uop, Load Port用于分派 Load uop, Store Port用于分派 Store uop。ALU( double speed)表示 Exec Port每半个Cycle就能分派1个简单的ALU uop,于是在最理想的情况下, Exec Port0和 Exec Port 11每个 Cycle分别发射两条uoop, Load Port和 Store port每个Cycle分别发射1条uop,所以1个Cyle最多能发射6条uop。不过这只是理论上的情况,实际情况由于指令的依赖性,远远达不到6条uoop并行。实时上,处理器流水线每个阶段能并行处理的最大指令数都不一样,如 Trace Cache一个 Cycle输出3条uop,因此 Intel处理器几乎在每个阶段都有 Buffer来隔离它们之间的速率偏差。
后面的 Register Read、 Execute、 LI Cache(MEM)、 Register Write和经典的MIPS5级流水线类似。
乱序执行内核的最后一步,就是 Retire(退出),它负责更新IsA寄存器状态,指令按照顺序退出乱序执行内核。 Allocate、 Register Rename、 Schedule、 Retire组成了乱序控制。
P4处理器实际的流水线达到了20级,比上面的介绍要更为复杂。