Flynn分类
处理器就是处理一系列指令和数据的设备,因此,从指令和数据这两个维度,可以对处理器的系统结构分类。1966年, Flynn将处理器系统结构分成了如下4类:
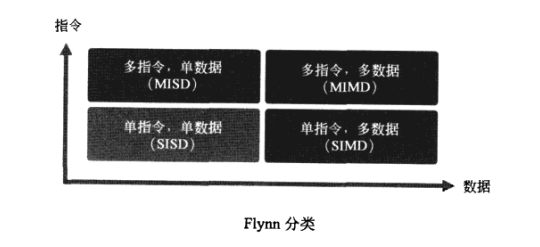
SISD( single instruction single data),一次处理一条指令,一条指令处理一份数据,早期的处理器都是这种形式。
SIMD( single instruction multiple data),-次处理一条指令,一条指令能处理多份数据,这种方式称为数据并行,现在性能稍微强一点的处理器都具备这种功能。
MISD( multiple instruction single data),一次处理多条指令,多条指令处理一份数据,这种结构没有实际意义。
MIMD( multiple instruction multiple data),一次处理多条指令,多条指令能处理多条数据,这种方式称为指令并行,高性能处理器都具备这个功能。
下图描述了指令并行性、数据并行性的示例:
并行,是提高处理器性能的不二法门,下面,我们就来详细介绍处理器的各种并行性。

指令并行( Instruction Level Parallelism)
指令并行的“绿营”和“蓝营
程序是由一系列指令组成的,如果要节省执行的时间,最直接的方法就是将指令并行起来执行。在处理器内部通常有很多的执行单元,如加法单元、乘法单元、内存访问单元、浮点运算单元等,每种执行单元负责一类具体的指令。在前面介绍的乱序执行内核中,每个Cycle最多只发射一条指令,即使有时很多指令并行执行,平均的指令执行效率也最多只有每个Cycle一条指令。如果发射单元一次能发射多条指令,那么就有更多指令能并行处理了,因此指令并行也称为multi-issue(多发射)。
哪些指令需要并行处理,这需要做判决,根据判决的地方不同,multi-Issue又分成了两个阵营:Superscalar和VLIW.
世上没有无缘无故的爱,也没有无缘无故的恨,没有无缘无故的Superscalar,也没有无缘无故的vLW.Superscalar和VLIW也是随着历史趋势慢慢发展起来的。
Superscalar是由 supeR(超)+ scalar(标量)组成,标量处理器时代的指令都是串行执行的,处理器为了兼容原有的程序,但同时又要提高程序执行效率,就在处理器内部做了指令的并行化处理。这就是超标量处理器的基本原型。

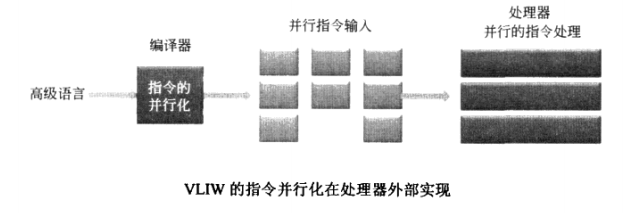
如果将指令的并行化显示的声明在指令格式中,处理器只是傻呼呼的执行,这种方式称为VLIW( Very Long Instruction Word)。指令的并行化可由编译器完成,也可以由程序员手工写并行汇编代码实现.
VLIW的典型代表是DSP。 TI DSP所使用的汇编代码格式如下:

指令前面的“||”表示这条指令和上条指令在同一个Cycle执行,如果没有“||”,则表示这条指令在下一个Cycle执行。在机器码中,每条指令占32bit,“‖”在第0bit表示,处理器只需按照指令规则执行即可。
早期的汇编语言都没有单独的字段描述当前指令是否和其他指令并行执行,处理器在发展时,为了保证指令集的兼容性,都采用了Superscalar结构,如x86、MIPS、ARM等。Superscalar的代价是处理器内部有不少的资源用于将串行的指令序列转换成可以并行的指令序列,这大大的增加了处理器的功耗和面积。而后来产生的新的指令集的处理器,大都采用了ⅤLIW结构,如 Tilera和Tensilica公司的处理器。
在 Multi-Issue结构中,不乱序也能实现一定程度的并行。例如,处理器内部有两条执行路径,一条路径执行浮点指令,一条路径执行整数指令,由于浮点指令和整数指令分别使用不同的寄存器,它们没有相关性,可以并行执行。不过,乱序执行的结构,更能提高指令的并行性,当然也需要更多的硬件资源。