10多年前的程序员对处理器乱序执行和内存屏障应该是很熟悉的,但随着计算机技术突飞猛进的发展,我们离底层原理越来越远,这并不是一件坏事,但在有些情况下了解一些底层原理有助于我们更好的工作,比如现代高级语言多提供了多线程并发技术,如果不深入下来,那么有些由多线程造成问题就很难排查和理解.
今天准备来聊聊乱序执行技术和内存屏障.为了能让大多数人理解,这里省略了很多不影响理解的旁枝末节,但由于我个人水平有限,如果不妥之处,希望各位指正.
按顺执行技术
在开始说乱序执行之前,得先把按序执行说一遍.在早期处理器中,处理器执行指令的顺序就是按照我们编写汇编代码的顺序执行的,换句话说此时处理器指令执行顺序和我们代码顺序一致,我们称之为按序执行(In Order Execution).我们以烧水泡茶为例来说明按序执行的过程(熟悉的同学会想起华罗庚的统筹学):
- 洗水壶
- 烧开水
- 洗茶壶
- 洗茶杯
- 拿茶叶
- 泡茶
我们假设每一步代表一条指令的执行,此时从指令1到指令6执行的过程就是我们所说的按序执行.整个过程可以表示为:

按序执行对于早期处理器而言是一种行之有效的方案,但随着对时间的要求,我们希望上述过程能够在最短的时间内执行完成,这就促使人们迫切希望找到一种优化指令执行过程的方案.考虑上述执行过程,我们发现洗茶壶这步完全没有必要等待烧开水完成,也就是说洗茶壶和洗水杯完全可以和烧开水同时进行,这么一来,优化过的流程如图:

这种通过改变原有执行顺序而减少时间的执行过程我们被称之为乱序执行,也称为重排.到现在为止,我们已经弄明白了什么是按序执行,什么是乱序.那接下来就看看处理器中的乱序执行技术.
乱序执行技术
处理器乱序执行
随着处理器流水线技术和多核技术的发展,目前的高级处理器通过提高内部逻辑元件的利用率来提高运行速度,通常会采用乱序执行技术.这里的乱序和上面谈到烧水煮茶的道理是一样的.
先来看一张处理器的简要结构图:
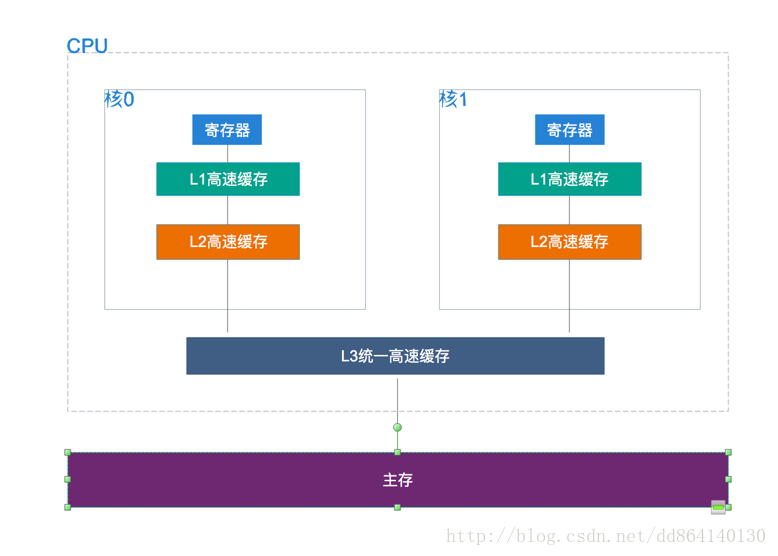
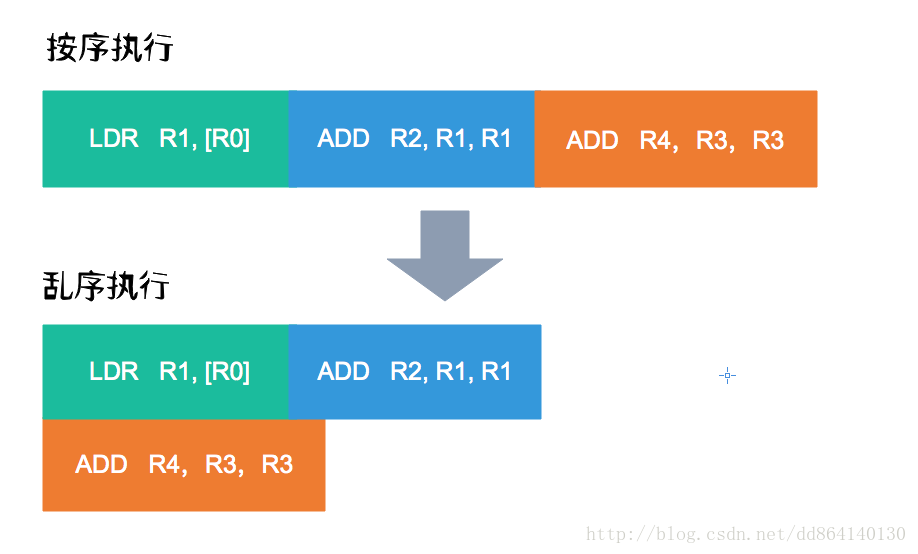
处理器从L1 Cache中取出一批指令,分析找出那些不存在相互依赖的指令,同时将其发射到多个逻辑单元执行,比如现在有以下几条指令:
LDR R1, [R0];
ADD R2, R1, R1;
ADD R4,R3,R3;
通过分析发现第二条指令和第一条指令存在依赖关系,但是和第3条指令无关,那么处理器就可能将其发送到两个逻辑单元去执行,因此上述的指令执行流程可能如下:
可以说乱序执行技术是处理器为提高运算速度而做出违背代码原有顺序的优化.在单核时代,处理器保证做出的优化不会导致执行结果远离预期目标,但在多核环境下却并非如此.
首先多核时代,同时会有多个核执行指令,每个核的指令都可能被乱序;另外,处理器还引入了L1,L2等缓存机制,每个核都有自己的缓存,这就导致逻辑次序上后写入内存的数据未必真的最后写入.最终带来了这么一个问题:如果我们不做任何防护措施,处理器最终得出的结果和我们逻辑得出的结果大不相同.比如我们在一个核上执行数据的写入操作,并在最后写一个标记用来表示之前的数据已经准备好,然后从另一个核上通过判断这个标志来判定所需要的数据已经就绪,这种做法存在风险:标记位先被写入,但是之前的数据操作却并未完成(可能是未计算完成,也可能是数据没有从处理器缓存刷新到主存当中),最终导致另一个核中使用了错误的数据.
编译器指令重排
除了上述由处理器和缓存引起的乱序之外,现代编译器同样提供了乱序优化.之所以出现编译器乱序优化其根本原因在于处理器每次只能分析一小块指令,但编译器却能在很大范围内进行代码分析,从而做出更优的策略,充分利用处理器的乱序执行功能.
乱序的分类
现在来总结下所有可能发生乱序执行的情况:
- 现代处理器采用指令并行技术,在不存在数据依赖性的前提下,处理器可以改变语句对应的机器指令的执行顺序来提高处理器执行速度
- 现代处理器采用内部缓存技术,导致数据的变化不能及时反映在主存所带来的乱序.
- 现代编译器为优化而重新安排语句的执行顺序
小结
尽管我们看到乱序执行初始目的是为了提高效率,但是它看来其好像在这多核时代不尽人意,其中的某些”自作聪明”的优化导致多线程程序产生各种各样的意外.因此有必要存在一种机制来消除乱序执行带来的坏影响,也就是说应该允许程序员显式的告诉处理器对某些地方禁止乱序执行.这种机制就是所谓内存屏障.不同架构的处理器在其指令集中提供了不同的指令来发起内存屏障,对应在编程语言当中就是提供特殊的关键字来调用处理器相关的指令.
内存屏障
处理器乱序规则
上面我们说了处理器会发生指令重排,现在来简单的看看常见处理器允许的重排规则,换言之就是处理器可以对那些指令进行顺序调整:
| 处理器 | Load-Load | Load-Store | Store-Store | Store-Load | 数据依赖 |
|---|---|---|---|---|---|
| x86 | N | N | N | Y | N |
| PowerPC | Y | Y | Y | Y | N |
| ia64 | Y | Y | Y | Y | N |
表格中的Y表示前后两个操作允许重排,N则表示不允许重排.与这些规则对应是的禁止重排的内存屏障.
注意:处理器和编译都会遵循数据依赖性,不会改变存在数据依赖关系的两个操作的顺序.所谓的数据依赖性就是如果两个操作访问同一个变量,且这两个操作中有一个是写操作,那么久可以称这两个操作存在数据依赖性.举个简单例子:
a=100;//write
b=a;//read
或者
a=100;//write
a=2000;//write
或者
a=b;//read
b=12;//write
以上所示的,两个操作之间不能发生重排,这是处理器和编译所必须遵循的.当然这里指的是发生在单个处理器或单个线程中.
内存屏障的分类
在开始看一下表格之前,务必确保自己了解Store和Load指令的含义.简单来说,Store就是将处理器缓存中的数据刷新到内存中,而Load则是从内存拷贝数据到缓存当中.
| 屏障类型 | 指令示例 | 说明 |
|---|---|---|
| LoadLoad Barriers | Load1;LoadLoad;Load2 | 该屏障确保Load1数据的装载先于Load2及其后所有装载指令的的操作 |
| StoreStore Barriers | Store1;StoreStore;Store2 | 该屏障确保Store1立刻刷新数据到内存(使其对其他处理器可见)的操作先于Store2及其后所有存储指令的操作 |
| LoadStore Barriers | Load1;LoadStore;Store2 | 确保Load1的数据装载先于Store2及其后所有的存储指令刷新数据到内存的操作 |
| StoreLoad Barriers | Store1;StoreLoad;Load1 | 该屏障确保Store1立刻刷新数据到内存的操作先于Load2及其后所有装载装载指令的操作.它会使该屏障之前的所有内存访问指令(存储指令和访问指令)完成之后,才执行该屏障之后的内存访问指令 |
StoreLoad Barriers同时具备其他三个屏障的效果,因此也称之为全能屏障,是目前大多数处理器所支持的,但是相对其他屏障,该屏障的开销相对昂贵.在x86架构的处理器的指令集中,lock指令可以触发StoreLoad Barriers.
现在我们综合重排规则和内存屏障类型来说明一下.比如x86架构的处理器中允许处理器对Store-Load操作进行重排,与之对应有StoreLoad Barriers禁止其重排.
as-if-serial语义
无论是处理器还是编译器,不管怎么重排都要保证(单线程)程序的执行结果不能被改变,这就是as-if-serial语义.比如烧水煮茶的最终结果永远是煮茶,而不能变成烧水.为了遵循这种语义,处理器和编译器不能对存在数据依赖性的操作进行重排,因为这种重排会改变操作结果,比如对:
a=100;//write
b=a;//read
重排为:
b=a;
a=100;
此时b的值就是不正确的.如果不存在操作之间不存在数据依赖,那么这些操作就可能被处理器或编译器进行重排,比如:
a=10;
b=200;
result=a*b;
它们之间的依赖关系如图:
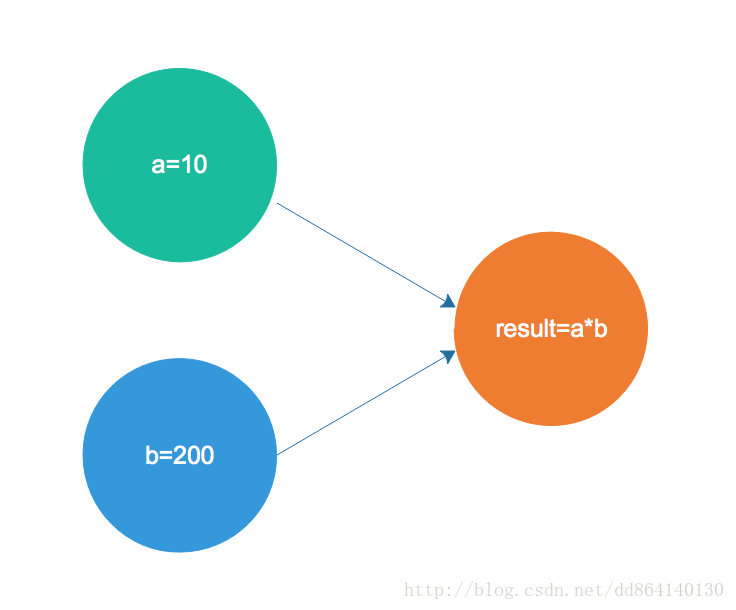
由于a=10和b=200之间不存在依赖关系,因此编译器或处理可以这两两个操作进行重排,因此最终执行顺序可能有以下两种情况:
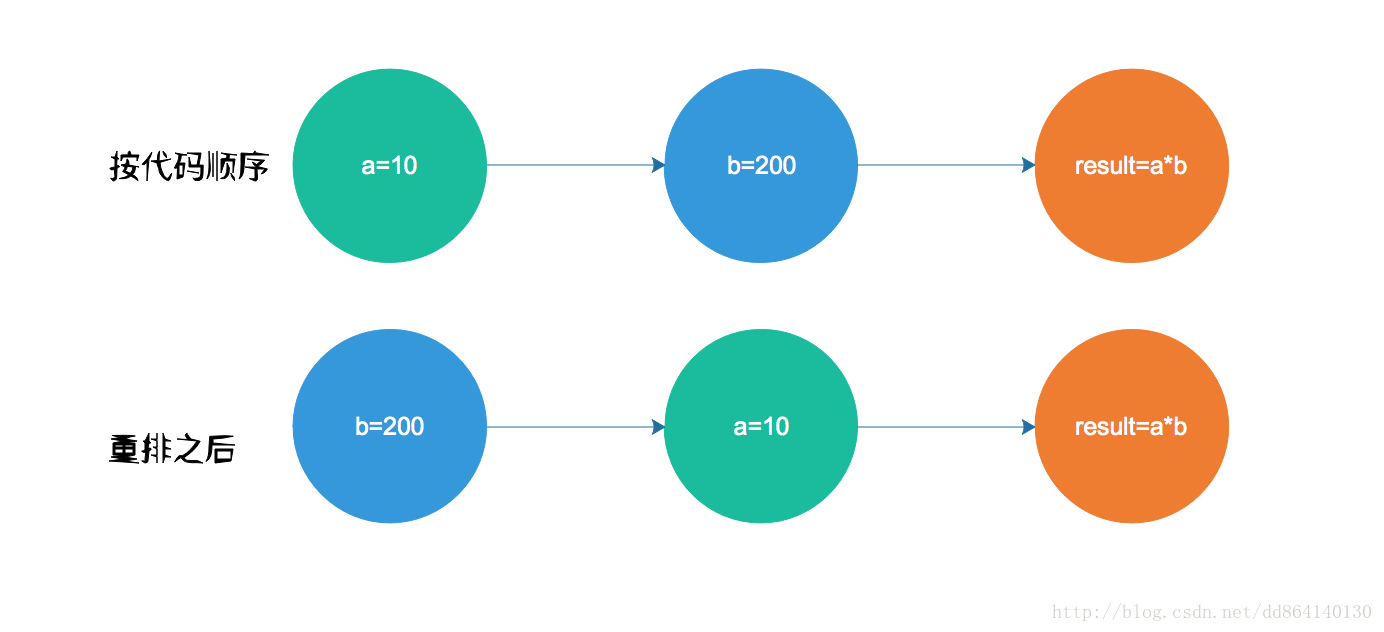
但无论哪种执行顺序,最终的结果都是对的.
正是因为as-if-serial的存在,我们在编写单线程程序时会觉得好像它就是按代码的顺序执行的,这让我们可以不必关心重排的影响.换句话说,如果你从来没有编写多线程程序的需求,那就不需要关注今天我所说的一切.