起因
前几天在弄Hubble连接Oracle数据库,然后在mongodb中建立一个镜像数据库;
发现一个问题,原本数据是11W,但是镜像库中只有6w多条;
刚开始以为是没运行好,又rebuild了一下
结果变成了7w多,又rebuild,又变成了6w了............
rebuild了N次,基本上每次结果都是不一样的
准备调试
没办法只能下载源码调试一下;
先把所有的dll都输出到同一个目录

然后把Hubble的服务停止了,再把Hubble的所有文件拷贝到dll的输出目录
然后编译生成一下,将HubbleTask设为启动项目,直接启动

这样就相当于启动服务器了
然后进入Hubble的安装目录,启动QueryAnalyzer.exe
开始调试
因为是建立mongodb的镜像,所以找到Hubble.Code项目中的DBAdapter文件夹中的MongoAdapter.cs
找到方法public void MirrorInsert(IList<Document> docs) 插入镜像数据
设置断点,就可以了,然后找到QueryAnalyzer.exe中的rebuild,执行

其中的docs就是需要插入到monogodb的数据,每次5000个,运行几次后就发现了,每到5,6w左右数据的时候,就会传入一个1000多的数据,然后就没有下次了
就是后面的数据查询不到了,每次只能查到6w左右的数据,现在可以排除是插入数据失败的原因了
排除了monogodb插入错误的原因后,开始检查Oracle查询数据是否准确
然后推测是在从Orcale获取数据的时候有问题?
打开并行任务瞄一下...(这里只是习惯的看一下,不一定每次都有效)

不过这次很巧的,发现了一个熟悉的方法(因为Orcale的驱动是重新实现的,所以这部分比较熟)
刚好和猜测也吻合了,这个是获取Oracle数据的地方

点进去看一下
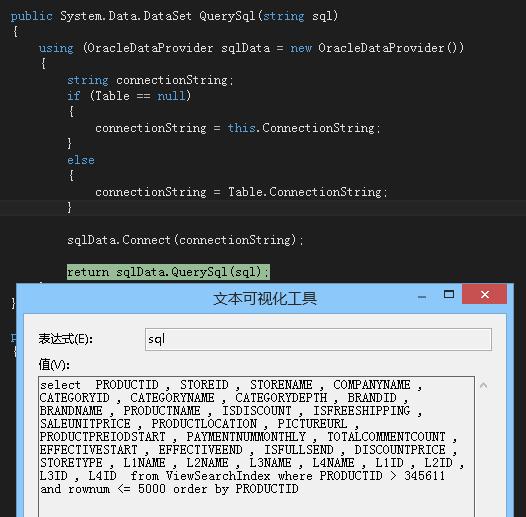
查询语句似乎有些问题看,这时还不确定
好吧 我承认这段时间搞Oracle比较多,也吃过不少亏,所以看到这段语句的时候就感觉不太对劲了
看看这个语句是什么时候,在什么情况下生成...

继续顺着代码的思路往下排查
仔细看这个代码就不难发现,他希望的效果是,按照索引键排序,然后查找出最小的5000个记录
并保存最后一个(最大一个)索引键的值到from这个变量上
再看GetSelectSql(from)方法


private string GetSelectSql(long from) { if (_DBProvider.Table.DBAdapterTypeName.IndexOf("sqlserver", StringComparison.CurrentCultureIgnoreCase) == 0) { return GetSqlServerSelectSql(from); } else if (_DBProvider.Table.DBAdapterTypeName.IndexOf("mongodb", StringComparison.CurrentCultureIgnoreCase) == 0) { return GetMongoDBSelectSql(from); } else if (_DBProvider.Table.DBAdapterTypeName.IndexOf("oracle", StringComparison.CurrentCultureIgnoreCase) == 0) { return GetOracleSelectSql(from); } else if (_DBProvider.Table.DBAdapterTypeName.IndexOf("mysql", StringComparison.CurrentCultureIgnoreCase) == 0) { return GetMySqlSelectSql(from); } else if (_DBProvider.Table.DBAdapterTypeName.IndexOf("sqlite", StringComparison.CurrentCultureIgnoreCase) == 0) { return GetSqliteSelectSql(from); } else { return GetSqlServerSelectSql(from); } }
private string GetOracleSelectSql(long from) { string fields = GetOracleFieldNameList(from); StringBuilder sb = new StringBuilder(); sb.AppendFormat("select {0} from {1} where {4} > {2} and rownum <= {3} order by {4} ", fields, _DBProvider.Table.DBTableName, from, _Step, Oracle8iAdapter.GetFieldName(_DBProvider.Table.DocIdReplaceField)); return sb.ToString(); }
猜想已经得到验证了, 下一次查询的时候 使用上次得到的from作为条件,继续搜索前5000条记录
现在如果接触过Oracle的应该知道了,Orcale中的rownum+orderby的效果和sqlserver中的top+orderby是完全不一样的
Oracle中orderby是等rownum执行完之后才执行的
产生bug的原因
也就是说 orderby 搜索出前5000条记录,然后对这5000条记录排序!而不是对全表排序,取出前5000条记录
假设我有数据 5,8,4,3,10,2,9,1,6,7
每次取出5条 5,8,4,3,10 然后排序 3,4,5,8,10 ,得到最后一个记录的id=10
下次搜索的时候获取比10大的5条记录..结果就是0 所以2,9,1,6,7数据丢失了......
开始修改代码
第一次修改:
private string GetOracleSelectSql(long from) { string fields = GetOracleFieldNameList(from); StringBuilder sb = new StringBuilder(); sb.AppendFormat("select * from (select {0} from {1} where {4} > {2} order by {4}) where rownum <= {3}", fields, _DBProvider.Table.DBTableName, from, _Step, Oracle8iAdapter.GetFieldName(_DBProvider.Table.DocIdReplaceField)); return sb.ToString(); }
测试得到的结果就是 数据是正确的,但是效率很低
第二次修改
所以进过第二次修改:
private string GetOracleSelectSql(long from) { string fields = GetOracleFieldNameList(from); string indexerField = Oracle8iAdapter.GetFieldName(_DBProvider.Table.DocIdReplaceField); string table = _DBProvider.Table.DBTableName; string where = indexerField + " > " + from; string sql = Oracle8iAdapter.GetOracleSelectSql(table, fields, indexerField, _Step, where); return sql; }
/// <summary> /// 组成Oracle可用的Sql语句 /// </summary> /// <param name="table">操作表</param> /// <param name="fields">返回列列名</param> /// <param name="indexerField">索引列列名</param> /// <param name="rowsCount">返回条数</param> /// <param name="where">额外的where条件,不包含where关键字</param> /// <returns></returns> public static string GetOracleSelectSql(string table, string fields, string indexerField, System.Decimal rowsCount, string where) { string sql = @" SELECT {1} FROM {0} A WHERE EXISTS (SELECT 1 FROM (SELECT {2} FROM (SELECT B.{2} FROM {0} B {4}{5} ORDER BY B.{2}) WHERE ROWNUM <= {3}) C WHERE C.{2} = A.{2}) ORDER BY {2} "; if (where == null) { return string.Format(sql, table, fields, indexerField, rowsCount, null, null, null); } else { return string.Format(sql, table, fields, indexerField, rowsCount, " WHERE ", where, " AND "); } }
虽然还是有一些不合理的地方,不过我们讲究的是最小的改动
关联改动
一共有4个方法是需要改动的
Hubble.Core.Service.SynchronizeCanUpdate.GetOracleSelectSql
Hubble.Core.Service.SynchronizeCanUpdate.GetOracleTriggleSql
Hubble.Core.Service.SynchronizeAppendOnly.GetOracleSelectSql
QueryAnalyzer.FormRebuildTableOld.GetOracleSelectSql
另外之前的方法也有一定的修改
private List<Document> GetDocumentsForInsert(IDBAdapter dbAdapter, ref long from) { List<Document> result = new List<Document>(); dbAdapter.DBProvider = this._DBProvider; System.Data.DataSet ds = dbAdapter.QuerySql(GetSelectSql(from)); StringBuilder sb = new StringBuilder(); foreach (System.Data.DataRow row in ds.Tables[0].Rows) { result.Add(GetOneRowDocument(row)); from = long.Parse(row[_DBProvider.Table.DocIdReplaceField].ToString()); } return result; }
改为
private List<Document> GetDocumentsForInsert(IDBAdapter dbAdapter, ref long from) { List<Document> result = new List<Document>(); dbAdapter.DBProvider = this._DBProvider; System.Data.DataSet ds = dbAdapter.QuerySql(GetSelectSql(from)); if (ds.Tables[0].Rows.Count <= 0) { return result; } var table = ds.Tables[0]; foreach (System.Data.DataRow row in table.Rows) { result.Add(GetOneRowDocument(row)); } from = Convert.ToInt64(table.Rows[table.Rows.Count - 1][_DBProvider.Table.DocIdReplaceField]); return result; }
结束了
至此就基本结束了,其实看了表层实现来说,还是有很多地方可以优化的,但是Hubble真正的性能优势在于他的高效的搜索算法,所以表层的这些都不是瓶颈点
就不做过多的改动了