应用机器学习的建议
如何改进算法
- 更多的训练数据不一定有效
- 尝试更小的特征
- 增加特征
- 增加多项式特征
- 尝试不同的正则化系数
以上方法可能并不是一些很有效的方法
如何评价和诊断一个机器学习系统,可以极大地提高改进算法的效率。
评估假设
如何防止过拟合与欠拟合的问题
将数据分割为训练集与测试集,统计测试集的预测错误以此对假设进行评估
模型选择和训练、验证、测试集
如何确定模型中参数以及KaTeX parse error: Undefined control sequence: d at position 1: ̲d̲(表示特征的最大维数)
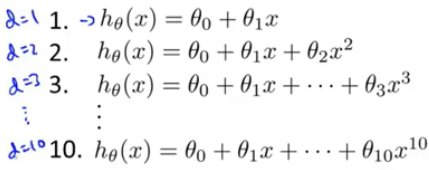
将以上10个模型的在测试集上进行评估,选择最好的哪个模型即确定模型的参数,但方式中模型的参数是由测试集选择出来的,不能依然用该测试集评估该模型的泛化能力。
解决方式:将数据由2类分为3类,即训练集、验证集(交叉验证集)与测试集,比例为0.6 :0.2 : 0.2.
当需要选择模型时,使用验证集来对模型选择,测试集用于评价模型的泛化能力。
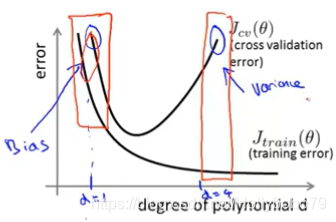
诊断偏差与方差
弄清楚是过拟合问题还是欠拟合问题,还是与两个都存在关系,这一点很重要。
两种错误:
- Training error
- Cross validation error
欠拟合与过拟合
- Training error 与 Cross validation error都高时,可能为欠拟合
- Training error 低,但Cross validation error高时,可能为过拟合
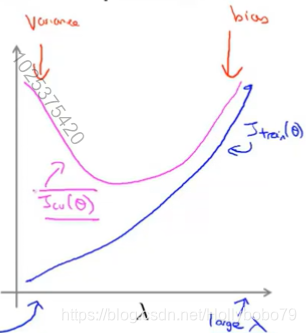
正则化和偏差、方差
训练误差/交叉验证误差与正则化系数的关系。
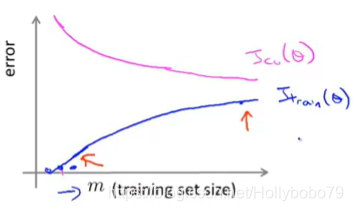
学习曲线
测试样本大小与测试误差/交叉验证误差
- 测试误差随样本大小增大而增大
- 交叉验证误差随样本大小增加而减小
决定接下来做什么
哪些改进方式是有效的,而哪些是效率低下的。
改进方式:
- Get more training example -> fix high variance(高方差,泛化能力差)
- Try smaller sets of features -> fix high variance
- Try getting additional features -> fix high bias
- Try adding polynomial features -> fix high bias
- Try decrease -> fix high bias
- Try increasing -> fix high variance
Neural networks and overfitting
通过交叉验证集选择variance更低的神经网络模型。