数据压缩
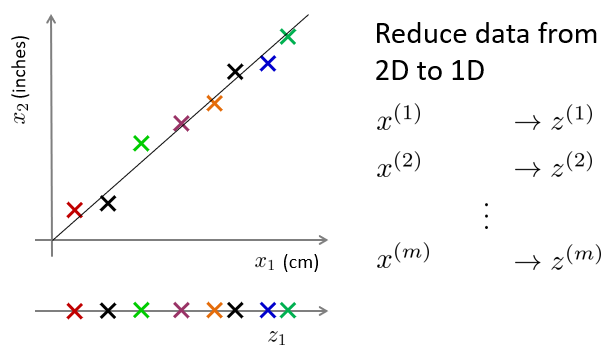
将二维数据降低到一维数据的方法,有直接替换的方法。下图中,将数据条目的二维特征x1,x2,转化为了一维特征z1。其中,x1和x2是直接相关的(因为四舍五入出现了一些偏差),而z1等于x1。
但是更通用的方法,应该是建立一个直线,该直线到所有特征点的距离平方和是最小的。以该直线建立坐标轴z,以数据投影作为z值,将二维数据降低到一维吧。
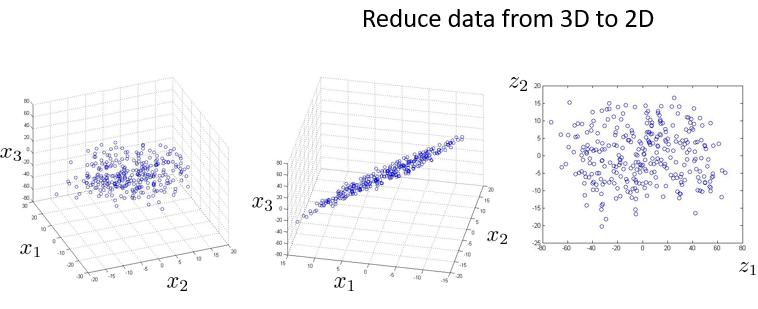
从本质的方法是,三维数据降低到二维数据的方法,将三维数据投射到一个二维平面上,该二维平面与所有数据点的距离平方和,应该要求最小。
最后,使用该二维平面所组建的新的坐标,将数据的在平面的投影作为坐标值,将三维数据降低到二维。如下图。
数据可视化
将高维数据降维到三维以下,可以实现可视化效果。但是降维后的数据中,每个维表示的意义,则需要自己定义。
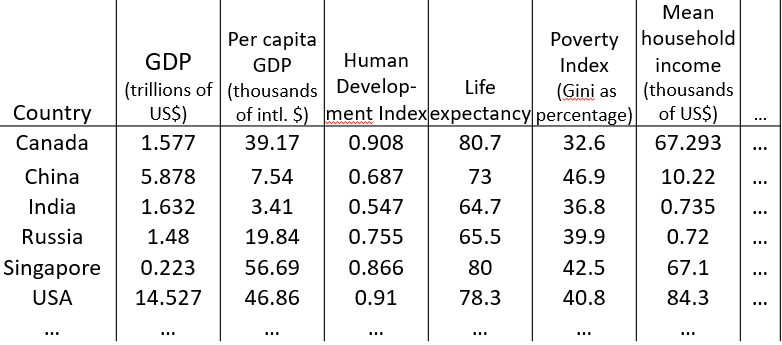
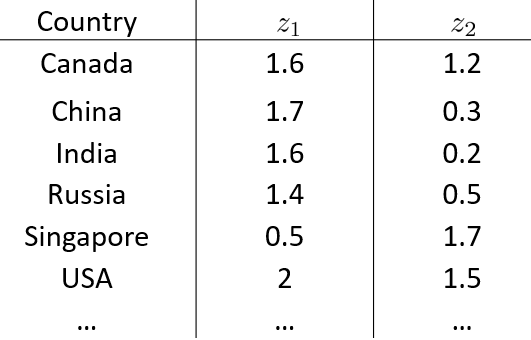
如下,是将国家之间的一些数据,每条数据有50维,最后降低到二维z1,z2,然后绘制出来的数据可视化效果。而通过观察,认为z1与国家规模或者GDP总量有关,而z2则与个人GDP有关。
主成分分析(Principal Component Analysis)问题阐述
主成分分析的方法原理,和之前所述数据降维基本一致,即,找到一个新的坐标轴、平面、或者超平面,使得数据到这些坐标轴、平面、或者超平面的距离平方和最小。
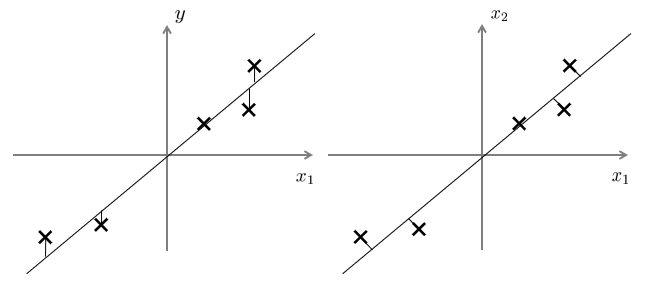
和机器学习中的有监督训练的,线性回归方法,不同的是,主成分分析法使用的为投影的距离平方和最小化,而线性回归要求,由输入x到模型产生的数据值,到标签y的距离平方和,最小化。这是针对不同领域的,两种不同的方法。
下图中,左为线性回归,右为主成分分析法。
主成分分析算法
首先需要进行数据表示的说明:
数据为X的矩阵(大小n*m,m条数据,n列特征)。每一行表示不同数据条目的相同特征。其中每条数据xi,大小为n行1列。
这是和之前数据表示方面,可能有不同的地方。
算法第一步是进行数据预处理。
在不同数据条目的相同特征下,进行归一化处理:求得特征均值,并将特征进行替换。(必要的吧,可能与协方差的定义有关)
在所有数据条目的不同特征下,将影响过大的特征值进行缩放,使得不同的特征表示出的数据具有可比性。(可选的)

算法的第二步是计算协方差矩阵sigma。协方差的计算方法如下图中公式的第一个。但是注意,其中的xi,表示的是所有样本的某一个特征值的向量。
即,在m个数据,每个数据n个特征,最终要将m个数据的特征降低到k个特征的过程中,xi,为n*1的向量。最终得到的大sigma,即为n*n大小的协方差矩阵。
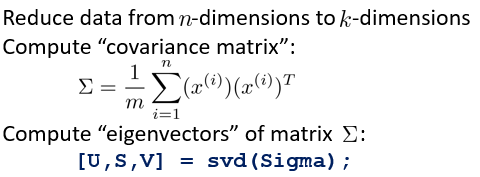
算法的第三步是使用大sigma作为参数,通过svd(singular value decomposition)奇异值分解函数(另外eig函数也有类似效果,但是svd可能更好用一点吧),获取特征向量U。如上图
从特征向量U中,取得前k列特征向量,得到Ureduce(大小为n*k)。转秩后,通过与每个数据x(规模n*1)相乘,得到该条数据的k个特征。
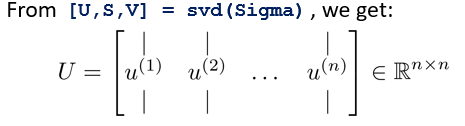
总结如下:其中,Sigma可以使用X的矩阵乘法,获取到n*n的协方差矩阵。

选择主成分的数量
选择数量时,根据PCA的方法,得到投影的均方差,当均方差和原始数据的均方差,比值最小,则有最小的数据量损失比例。误差为0,则投影均方差为0,误差比例为1,则Xapprox为0。
如下图,分子为投影均方差,分母为总均方差。通过k的增长,测试如下公式,选择最小的k,并满足误差损失比例,得到选择的k。其中:Xapprox为近似的原有特征,该特征使用投影Ureduce(n*k)与降维后的数据z(k*1)的乘积,得到近似的原始的n维数据,为Xapprox(n*1)。
![]()

或者,使用svd函数的计算结果中的S,由于该矩阵为对角矩阵,容易计算,得到结果。也容易编程吧。

重建的压缩表示
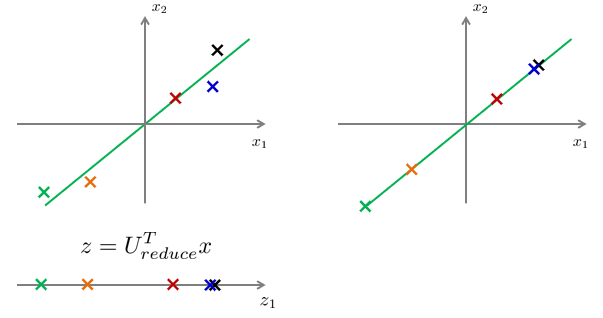
数据重构的方法如下所示,已经说明过。其含义是将低维数据,通过Ureduce特征向量,重新投射到高维数据的世界中。
如下图中,表示降维前数据的位置(左),降维后的数据位置(下),恢复后的数据位置(右)。
主成分分析法的应用建议
PCA可以压缩数据,可视化数据,加速神经网络训练等。
在图像识别方面,使用PCA,将原始的100*100像素进行降维做预处理,是可行的。在训练集过程中使用Ureduce,同样也应该使用训练集中的Ureduce,以获取验证集和测试集的,降维后的数据。
PCA可以用来加速神经网络的训练过程,但是并不是一个必要的部分。在可以不需要使用PCA的时候,就不应该使用降维损失数据。
另外,使用PCA方法,降低过拟合效果是不可取的。过拟合是由于泛化能力差,样本量不够导致,在m个样本n个特征情况下,虽然降低特征似乎可以降低过拟合,但是不可取(没有从根本上解决问题??)。应该使用正则化降低过拟合。
下图为原始材料:另外的一些关于过拟合、欠拟合材料:https://zhuanlan.zhihu.com/p/72038532
