场景
需要实现在安卓端将一段文字进行语音合成并播报。
此过程可离线不需要网络,不用借助第三方形如科大讯飞或者百度等语音合成SDK或者相关工具等。
注:
博客:
https://blog.csdn.net/badao_liumang_qizhi
关注公众号
霸道的程序猿
获取编程相关电子书、教程推送与免费下载。
实现
TextToSpeech
TextToSpeech能将一段文字转换为语音。
TextToSpeech是Android系统自带的类,不用导入别的包
实现效果
https://files.cnblogs.com/files/badaoliumangqizhi/%E8%AF%AD%E9%9F%B3%E6%92%AD%E6%8A%A5.rar
页面实现
为了搭建测试demo首先在layout中某页面上添加一个PlainText和一个Button实现页面布局如下

并给这两个组件添加Id属性。
然后在对应的activity中的onCreate方法中
Button button = (Button)findViewById(R.id.button); EditText editText = (EditText )findViewById(R.id.editTextTextPersonName2); button.setOnClickListener(new View.OnClickListener(){ @Override public void onClick(View v) { SpeechUtils.getInstance(LoginActivity.this).speakText(editText.getText().toString()); } });
获取到两个控件,并获取到PlainText控件的Text和设置Button按钮的点击事件。
可以看到在点击事件中调用了一个工具类SpeechUtils的一个方法speakText。
这个方法就是为了进行语音合成播放方便封装的工具类。只需要给工具类方法中传入要进行语音合成的String字符串内容即可。
这里将工具类设计成单例模式。
在项目某目录下新建一个工具类的包,并新建一个SpeechUtils,代码如下
import android.content.Context; import android.speech.tts.TextToSpeech; import android.util.Log; import android.widget.Toast; import java.util.Locale; public class SpeechUtils { private Context context; private static final String TAG = "SpeechUtils"; private static SpeechUtils singleton; private TextToSpeech textToSpeech; // TTS对象 public static SpeechUtils getInstance(Context context) { if (singleton == null) { synchronized (SpeechUtils.class) { if (singleton == null) { singleton = new SpeechUtils(context); } } } return singleton; } public SpeechUtils(Context context) { this.context = context; textToSpeech = new TextToSpeech(context, new TextToSpeech.OnInitListener() { @Override public void onInit(int i) { if (i == TextToSpeech.SUCCESS) { //textToSpeech.setLanguage(Locale.US); textToSpeech.setLanguage(Locale.CHINA); textToSpeech.setPitch(1.5f);// 设置音调,值越大声音越尖(女生),值越小则变成男声,1.0是常规 textToSpeech.setSpeechRate(0.5f); } } }); } public void speakText(String text) { if (textToSpeech != null) { textToSpeech.speak(text, TextToSpeech.QUEUE_FLUSH, null); } } }
注意:
1.以上代码设计为单例模式,在调用时直接使用
SpeechUtils.getInstance(LoginActivity.this).speakText(editText.getText().toString());
去调用,其中第一个参数是Context对象,如果是在Activity中,必须使用Activity的名字.this,不能直接使用this。
2.在工具类中
import android.speech.tts.TextToSpeech;
可以看到TextToSpeech是直接在android包下引入的是自带的,没有引入其他第三方的依赖。
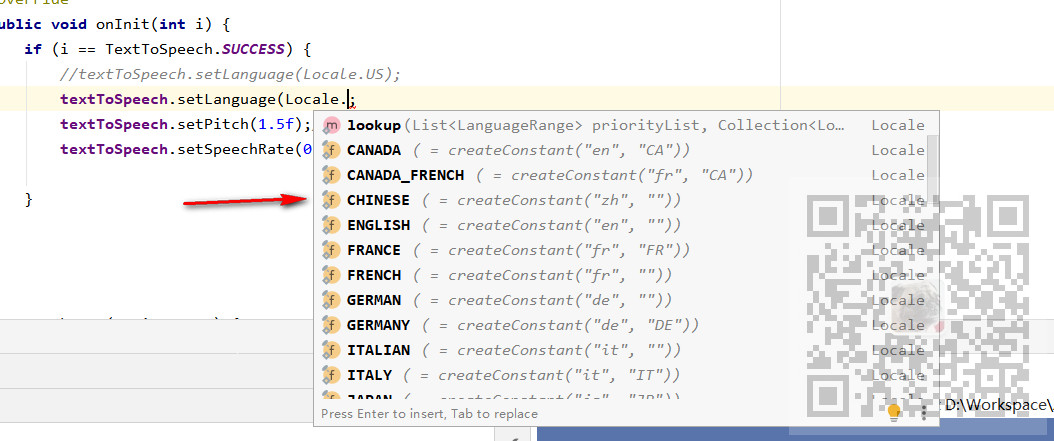
3.关于设置语言支持的问题,此前网络上大多说不支持中文,应该是很老的版本不支持中文,修改语言的位置在如下,
可以看到支持的语言种类很多,并且已经支持中文。所以只需要设置
textToSpeech.setLanguage(Locale.CHINA);
4.其他设置的属性
textToSpeech.setPitch(1.5f);// 设置音调,值越大声音越尖(女生),值越小则变成男声,1.0是常规 textToSpeech.setSpeechRate(0.5f);//设置速度
5.更多属性API可以参照Android官方文档:
https://developer.android.google.cn/reference/android/speech/tts/TextToSpeech
官方文档部分:
TextToSpeech
public class TextToSpeechextends Object
| android.speech.tts.TextToSpeech |
Synthesizes speech from text for immediate playback or to create a sound file.
A TextToSpeech instance can only be used to synthesize text
once it has completed its initialization. Implement the TextToSpeech.OnInitListener to be notified of the completion of the
initialization.
When you are done using the TextToSpeech
instance, call the shutdown() method to release the native resources used by the
TextToSpeech engine. Apps targeting Android 11 that use text-to-speech should
declare TextToSpeech.Engine#INTENT_ACTION_TTS_SERVICE in the queries elements of their manifest:
<queries>
...
<intent>
<action android:name="android.intent.action.TTS_SERVICE" />
</intent>
</queries>
Summary
Nested classes | |
|---|---|
class |
TextToSpeech.Engine
Constants and parameter names for controlling text-to-speech. |
class |
TextToSpeech.EngineInfo
Information about an installed text-to-speech engine. |
interface |
TextToSpeech.OnInitListener
Interface definition of a callback to be invoked indicating the completion of the TextToSpeech engine initialization. |
interface |
TextToSpeech.OnUtteranceCompletedListener
This interface was deprecated in API level 18. Use |
Constants | |
|---|---|
String |
ACTION_TTS_QUEUE_PROCESSING_COMPLETED
Broadcast Action: The TextToSpeech synthesizer has completed processing of all the text in the speech queue. |
int |
ERROR
Denotes a generic operation failure. |
int |
ERROR_INVALID_REQUEST
Denotes a failure caused by an invalid request. |
int |
ERROR_NETWORK
Denotes a failure caused by a network connectivity problems. |
int |
ERROR_NETWORK_TIMEOUT
Denotes a failure caused by network timeout. |
int |
ERROR_NOT_INSTALLED_YET
Denotes a failure caused by an unfinished download of the voice data. |
int |
ERROR_OUTPUT
Denotes a failure related to the output (audio device or a file). |
int |
ERROR_SERVICE
Denotes a failure of a TTS service. |
int |
ERROR_SYNTHESIS
Denotes a failure of a TTS engine to synthesize the given input. |
int |
LANG_AVAILABLE
Denotes the language is available for the language by the locale, but not the country and variant. |
int |
LANG_COUNTRY_AVAILABLE
Denotes the language is available for the language and country specified by the locale, but not the variant. |
int |
LANG_COUNTRY_VAR_AVAILABLE
Denotes the language is available exactly as specified by the locale. |
int |
LANG_MISSING_DATA
Denotes the language data is missing. |
int |
LANG_NOT_SUPPORTED
Denotes the language is not supported. |
int |
QUEUE_ADD
Queue mode where the new entry is added at the end of the playback queue. |
int |
QUEUE_FLUSH
Queue mode where all entries in the playback queue (media to be played and text to be synthesized) are dropped and replaced by the new entry. |
int |
STOPPED
Denotes a stop requested by a client. |
int |
SUCCESS
Denotes a successful operation. |
Public constructors | |
|---|---|
TextToSpeech(Context context, TextToSpeech.OnInitListener listener)
The constructor for the TextToSpeech class, using the default TTS engine. |
|
TextToSpeech(Context context, TextToSpeech.OnInitListener listener, String engine)
The constructor for the TextToSpeech class, using the given TTS engine. |
|
Public methods | |
|---|---|
int |
addEarcon(String earcon, String packagename, int resourceId)
Adds a mapping between a string of text and a sound resource in a package. |
int |
addEarcon(String earcon, String filename)
This method was deprecated in API level 21. As of API level 21, replaced by |
int |
addEarcon(String earcon, File file)
Adds a mapping between a string of text and a sound file. |
int |
addSpeech(CharSequence text, File file)
Adds a mapping between a CharSequence (may be spanned with TtsSpans and a sound file. |
int |
addSpeech(String text, String packagename, int resourceId)
Adds a mapping between a string of text and a sound resource in a package. |
int |
addSpeech(CharSequence text, String packagename, int resourceId)
Adds a mapping between a CharSequence (may be spanned with TtsSpans) of text and a sound resource in a package. |
int |
addSpeech(String text, String filename)
Adds a mapping between a string of text and a sound file. |
boolean |
areDefaultsEnforced()
Checks whether the user's settings should override settings requested by the calling application. |
Set<Locale> |
getAvailableLanguages()
Query the engine about the set of available languages. |
String |
getDefaultEngine()
Gets the package name of the default speech synthesis engine. |
Locale |
getDefaultLanguage()
This method was deprecated in API level 21. As of API level 21, use |
Voice |
getDefaultVoice()
Returns a Voice instance that's the default voice for the default Text-to-speech language. |
List<TextToSpeech.EngineInfo> |
getEngines()
Gets a list of all installed TTS engines. |
Set<String> |
getFeatures(Locale locale)
This method was deprecated in API level 21. As of API level 21, please use voices. In order to query features of the voice, call |
Locale |
getLanguage()
This method was deprecated in API level 21. As of API level 21, please use |
static int |
getMaxSpeechInputLength()
Limit of length of input string passed to speak and synthesizeToFile. |
Voice |
getVoice()
Returns a Voice instance describing the voice currently being used for synthesis requests sent to the TextToSpeech engine. |
Set<Voice> |
getVoices()
Query the engine about the set of available voices. |
int |
isLanguageAvailable(Locale loc)
Checks if the specified language as represented by the Locale is available and supported. |
boolean |
isSpeaking()
Checks whether the TTS engine is busy speaking. |
int |
playEarcon(String earcon, int queueMode, HashMap<String, String> params)
This method was deprecated in API level 21. As of API level 21, replaced by |
int |
playEarcon(String earcon, int queueMode, Bundle params, String utteranceId)
Plays the earcon using the specified queueing mode and parameters. |
int |
playSilence(long durationInMs, int queueMode, HashMap<String, String> params)
This method was deprecated in API level 21. As of API level 21, replaced by |
int |
playSilentUtterance(long durationInMs, int queueMode, String utteranceId)
Plays silence for the specified amount of time using the specified queue mode. |
int |
setAudioAttributes(AudioAttributes audioAttributes)
Sets the audio attributes to be used when speaking text or playing back a file. |
int |
setEngineByPackageName(String enginePackageName)
This method was deprecated in API level 15. This doesn't inform callers when the TTS engine has been initialized. |
int |
setLanguage(Locale loc)
Sets the text-to-speech language. |
int |
setOnUtteranceCompletedListener(TextToSpeech.OnUtteranceCompletedListener listener)
This method was deprecated in API level 15. Use |
int |
setOnUtteranceProgressListener(UtteranceProgressListener listener)
Sets the listener that will be notified of various events related to the synthesis of a given utterance. |
int |
setPitch(float pitch)
Sets the speech pitch for the TextToSpeech engine. |
int |
setSpeechRate(float speechRate)
Sets the speech rate. |
int |
setVoice(Voice voice)
Sets the text-to-speech voice. |
void |
shutdown()
Releases the resources used by the TextToSpeech engine. |
int |
speak(CharSequence text, int queueMode, Bundle params, String utteranceId)
Speaks the text using the specified queuing strategy and speech parameters, the text may be spanned with TtsSpans. |
int |
speak(String text, int queueMode, HashMap<String, String> params)
This method was deprecated in API level 21. As of API level 21, replaced by |
int |
stop()
Interrupts the current utterance (whether played or rendered to file) and discards other utterances in the queue. |
int |
synthesizeToFile(CharSequence text, Bundle params, ParcelFileDescriptor fileDescriptor, String utteranceId)
Synthesizes the given text to a ParcelFileDescriptor using the specified parameters. |
int |
synthesizeToFile(CharSequence text, Bundle params, File file, String utteranceId)
Synthesizes the given text to a file using the specified parameters. |
int |
synthesizeToFile(String text, HashMap<String, String> params, String filename)
This method was deprecated in API level 21. As of API level 21, replaced by |
Inherited methods | |
|---|---|
Constants
ACTION_TTS_QUEUE_PROCESSING_COMPLETED
public static final String ACTION_TTS_QUEUE_PROCESSING_COMPLETED
Broadcast Action: The TextToSpeech synthesizer has completed processing of all the text in the speech queue. Note that this notifies callers when the engine has finished has processing text data. Audio playback might not have completed (or even started) at this point. If you wish to be notified when this happens, see OnUtteranceCompletedListener.
Constant Value: "android.speech.tts.TTS_QUEUE_PROCESSING_COMPLETED"
ERROR
public static final int ERROR
Denotes a generic operation failure.
Constant Value: -1 (0xffffffff)
ERROR_INVALID_REQUEST
public static final int ERROR_INVALID_REQUEST
Denotes a failure caused by an invalid request.
Constant Value: -8 (0xfffffff8)
ERROR_NETWORK
public static final int ERROR_NETWORK
Denotes a failure caused by a network connectivity problems.
Constant Value: -6 (0xfffffffa)
ERROR_NETWORK_TIMEOUT
public static final int ERROR_NETWORK_TIMEOUT
Denotes a failure caused by network timeout.
Constant Value: -7 (0xfffffff9)
ERROR_NOT_INSTALLED_YET
public static final int ERROR_NOT_INSTALLED_YET
Denotes a failure caused by an unfinished download of the voice data.
Constant Value: -9 (0xfffffff7)
ERROR_OUTPUT
public static final int ERROR_OUTPUT
Denotes a failure related to the output (audio device or a file).
Constant Value: -5 (0xfffffffb)
ERROR_SERVICE
public static final int ERROR_SERVICE
Denotes a failure of a TTS service.
Constant Value: -4 (0xfffffffc)
ERROR_SYNTHESIS
public static final int ERROR_SYNTHESIS
Denotes a failure of a TTS engine to synthesize the given input.
Constant Value: -3 (0xfffffffd)
LANG_AVAILABLE
public static final int LANG_AVAILABLE
Denotes the language is available for the language by the locale, but not the country and variant.
Constant Value: 0 (0x00000000)
LANG_COUNTRY_AVAILABLE
public static final int LANG_COUNTRY_AVAILABLE
Denotes the language is available for the language and country specified by the locale, but not the variant.
Constant Value: 1 (0x00000001)
LANG_COUNTRY_VAR_AVAILABLE
public static final int LANG_COUNTRY_VAR_AVAILABLE
Denotes the language is available exactly as specified by the locale.
Constant Value: 2 (0x00000002)
LANG_MISSING_DATA
public static final int LANG_MISSING_DATA
Denotes the language data is missing.
Constant Value: -1 (0xffffffff)
LANG_NOT_SUPPORTED
public static final int LANG_NOT_SUPPORTED
Denotes the language is not supported.
Constant Value: -2 (0xfffffffe)
QUEUE_ADD
public static final int QUEUE_ADD
Queue mode where the new entry is added at the end of the playback queue.
Constant Value: 1 (0x00000001)
QUEUE_FLUSH
public static final int QUEUE_FLUSH
Queue mode where all entries in the playback queue (media to be played and text to be synthesized) are dropped and replaced by the new entry. Queues are flushed with respect to a given calling app. Entries in the queue from other callees are not discarded.
Constant Value: 0 (0x00000000)
STOPPED
public static final int STOPPED
Denotes a stop requested by a client. It's used only on the service side of the API, client should never expect to see this result code.
Constant Value: -2 (0xfffffffe)
SUCCESS
public static final int SUCCESS
Denotes a successful operation.
Constant Value: 0 (0x00000000)
Public constructors
TextToSpeech
public TextToSpeech (Context context, TextToSpeech.OnInitListener listener)
The constructor for the TextToSpeech class, using the default TTS engine. This will also initialize the associated TextToSpeech engine if it isn't already running.
| Parameters | |
|---|---|
context |
Context: The context this instance is running in.
|
listener |
TextToSpeech.OnInitListener: The TextToSpeech.OnInitListener that will be called when the TextToSpeech engine has initialized. In a case of a failure the listener may be called immediately, before TextToSpeech instance is fully constructed.
|
TextToSpeech
public TextToSpeech (Context context, TextToSpeech.OnInitListener listener, String engine)
The constructor for the TextToSpeech class, using the given TTS engine. This will also initialize the associated TextToSpeech engine if it isn't already running.
| Parameters | |
|---|---|
context |
Context: The context this instance is running in.
|
listener |
TextToSpeech.OnInitListener: The TextToSpeech.OnInitListener that will be called when the TextToSpeech engine has initialized. In a case of a failure the listener may be called immediately, before TextToSpeech instance is fully constructed.
|
engine |
String: Package name of the TTS engine to use.
|
Public methods
addEarcon
public int addEarcon (String earcon, String packagename, int resourceId)
Adds a mapping between a string of text and a sound resource in a package. Use this to add custom earcons.
| Parameters | |
|---|---|
earcon |
String: The name of the earcon. Example: "[tick]" |
packagename |
String: the package name of
the application that contains the resource. This can for instance be the package
name of your own application. Example: "com.google.marvin.compass"The package name can be found in the AndroidManifest.xml of the application containing the resource.
|
resourceId |
int: Example: R.raw.tick_snd
|
See also:
addEarcon
Deprecated in API level 21
public int addEarcon (String earcon, String filename)
This method was deprecated in API level 21.
As of API level 21, replaced by addEarcon(java.lang.String,
java.io.File).
Adds a mapping between a string of text and a sound file. Use this to add custom earcons.
| Parameters | |
|---|---|
earcon |
String: The name of the
earcon. Example: "[tick]"
|
filename |
String: The full path to the
sound file (for example: "/sdcard/mysounds/tick.wav")
|
See also:
addEarcon
public int addEarcon (String earcon, File file)
Adds a mapping between a string of text and a sound file. Use this to add custom earcons.
| Parameters | |
|---|---|
earcon |
String: The name of the earcon. Example: "[tick]"
|
file |
File: File object pointing to the sound file.
|
See also:
addSpeech
public int addSpeech (CharSequence text, File file)
Adds a mapping between a CharSequence (may be spanned with TtsSpans and a sound file. Using this, it is possible to add custom pronounciations for a string of text. After a call to this method, subsequent calls to speak(java.lang.CharSequence, int, android.os.Bundle, java.lang.String) will play the specified sound resource if it is available, or synthesize the text it is missing.
| Parameters | |
|---|---|
text |
CharSequence: The string of text. Example: "south_south_east"
|
file |
File: File object pointing to the sound file.
|
addSpeech
public int addSpeech (String text, String packagename, int resourceId)
Adds a mapping between a string of text and a sound resource in a package. After a call to this method, subsequent calls to speak(java.lang.CharSequence, int, android.os.Bundle, java.lang.String) will play the specified sound resource if it is available, or synthesize the text it is missing.
| Parameters | |
|---|---|
text |
String: The string of text. Example: "south_south_east"
|
packagename |
String: Pass the packagename of the application that contains the resource. If the resource is in your own application (this is the most common case), then put the packagename of your application here.Example: "com.google.marvin.compass" The packagename can be found in the AndroidManifest.xml of your application.
|
resourceId |
int: Example: R.raw.south_south_east
|
addSpeech
public int addSpeech (CharSequence text, String packagename, int resourceId)
Adds a mapping between a CharSequence (may be spanned with TtsSpans) of text and a sound resource in a package. After a call to this method, subsequent calls to speak(java.lang.CharSequence, int, android.os.Bundle, java.lang.String) will play the specified sound resource if it is available, or synthesize the text it is missing.
| Parameters | |
|---|---|
text |
CharSequence: The string of text. Example: "south_south_east"
|
packagename |
String: Pass the packagename of the application that contains the resource. If the resource is in your own application (this is the most common case), then put the packagename of your application here.Example: "com.google.marvin.compass" The packagename can be found in the AndroidManifest.xml of your application.
|
resourceId |
int: Example: R.raw.south_south_east
|
addSpeech
public int addSpeech (String text, String filename)
Adds a mapping between a string of text and a sound file. Using this, it is possible to add custom pronounciations for a string of text. After a call to this method, subsequent calls to speak(java.lang.CharSequence, int, android.os.Bundle, java.lang.String) will play the specified sound resource if it is available, or synthesize the text it is missing.
| Parameters | |
|---|---|
text |
String: The string of text. Example: "south_south_east"
|
filename |
String: The full path to the sound file (for example: "/sdcard/mysounds/hello.wav")
|
areDefaultsEnforced
Deprecated in API level 21
public boolean areDefaultsEnforced ()
Checks whether the user's settings should override settings requested by the calling application. As of the Ice cream sandwich release, user settings never forcibly override the app's settings.
| Returns | |
|---|---|
boolean |
|
getAvailableLanguages
public Set<Locale> getAvailableLanguages ()
Query the engine about the set of available languages.
getDefaultEngine
public String getDefaultEngine ()
Gets the package name of the default speech synthesis engine.
| Returns | |
|---|---|
String |
Package name of the TTS engine that the user has chosen as their default. |
getDefaultLanguage
Deprecated in API level 21
public Locale getDefaultLanguage ()
This method was deprecated in API level 21.
As of API level 21, use getDefaultVoice().getLocale() (getDefaultVoice())
Returns a Locale instance describing the language currently
being used as the default Text-to-speech language. The locale object returned by
this method is NOT a valid one. It has identical form to the one in getLanguage().
Please refer to getLanguage() for more information.
| Returns | |
|---|---|
Locale |
language, country (if any) and variant (if
any) used by the client stored in a Locale instance, or null on error.
|
getDefaultVoice
public Voice getDefaultVoice ()
Returns a Voice instance that's the default voice for the default Text-to-speech language.
| Returns | |
|---|---|
Voice |
The default voice instance for the default language, or null if not set or on error.
|
getEngines
public List<TextToSpeech.EngineInfo> getEngines ()
Gets a list of all installed TTS engines.
| Returns | |
|---|---|
List<TextToSpeech.EngineInfo> |
A list of engine info objects. The list can be empty, but never null.
|
getFeatures
Deprecated in API level 21
public Set<String> getFeatures (Locale locale)
This method was deprecated in API level 21.
As of API level 21, please use voices. In order to query
features of the voice, call getVoices() to retrieve the list of available voices and Voice#getFeatures() to retrieve the set of features.
Queries the engine for the set of features it supports for
a given locale. Features can either be framework defined, e.g. TextToSpeech.Engine#KEY_FEATURE_NETWORK_SYNTHESIS or engine specific. Engine specific keys must be
prefixed by the name of the engine they are intended for. These keys can be used
as parameters to TextToSpeech#speak(String,
int, java.util.HashMap) and TextToSpeech#synthesizeToFile(String,
java.util.HashMap, String). Features values are strings and their
values must meet restrictions described in their documentation.
| Parameters | |
|---|---|
locale |
Locale: The locale to query
features for.
|
getLanguage
Deprecated in API level 21
public Locale getLanguage ()
This method was deprecated in API level 21.
As of API level 21, please use getVoice().getLocale() (getVoice()).
Returns a Locale instance describing the language currently
being used for synthesis requests sent to the TextToSpeech engine. In Android
4.2 and before (API <= 17) this function returns the language that is
currently being used by the TTS engine. That is the last language set by this or
any other client by a TextToSpeech#setLanguage call to the same engine. In Android versions after
4.2 this function returns the language that is currently being used for the
synthesis requests sent from this client. That is the last language set by
a TextToSpeech#setLanguage call on this instance. If a voice is set (by setVoice(android.speech.tts.Voice)),
getLanguage will return the language of the currently set voice. Please note
that the Locale object returned by this method is NOT a valid Locale object. Its
language field contains a three-letter ISO 639-2/T code (where a proper Locale
would use a two-letter ISO 639-1 code), and the country field contains a
three-letter ISO 3166 country code (where a proper Locale would use a two-letter
ISO 3166-1 code).
| Returns | |
|---|---|
Locale |
language, country (if any) and variant (if
any) used by the client stored in a Locale instance, or null on error.
|
getMaxSpeechInputLength
public static int getMaxSpeechInputLength ()
Limit of length of input string passed to speak and synthesizeToFile.
| Returns | |
|---|---|
int |
|
getVoice
public Voice getVoice ()
Returns a Voice instance describing the voice currently being used for synthesis requests sent to the TextToSpeech engine.
| Returns | |
|---|---|
Voice |
Voice instance used by the client, or null if not set or on error.
|
See also:
getVoices
public Set<Voice> getVoices ()
Query the engine about the set of available voices. Each TTS Engine can expose multiple voices for each locale, each with a different set of features.
See also:
isLanguageAvailable
public int isLanguageAvailable (Locale loc)
Checks if the specified language as represented by the Locale is available and supported.
| Parameters | |
|---|---|
loc |
Locale: The Locale describing the language to be used.
|
| Returns | |
|---|---|
int |
Code indicating the support status for the locale. See LANG_AVAILABLE, LANG_COUNTRY_AVAILABLE, LANG_COUNTRY_VAR_AVAILABLE, LANG_MISSING_DATA and LANG_NOT_SUPPORTED.
|
isSpeaking
public boolean isSpeaking ()
Checks whether the TTS engine is busy speaking. Note that a speech item is considered complete once it's audio data has been sent to the audio mixer, or written to a file. There might be a finite lag between this point, and when the audio hardware completes playback.
| Returns | |
|---|---|
boolean |
true if the TTS engine is speaking.
|
playEarcon
Deprecated in API level 21
public int playEarcon (String earcon, int queueMode, HashMap<String, String> params)
This method was deprecated in API level 21.
As of API level 21, replaced by playEarcon(java.lang.String,
int, android.os.Bundle, java.lang.String).
Plays the earcon using the specified queueing mode and
parameters. The earcon must already have been added with addEarcon(java.lang.String,
java.lang.String) or addEarcon(java.lang.String,
java.lang.String, int). This method is asynchronous, i.e. the method
just adds the request to the queue of TTS requests and then returns. The
synthesis might not have finished (or even started!) at the time when this
method returns. In order to reliably detect errors during synthesis, we
recommend setting an utterance progress listener (see setOnUtteranceProgressListener(UtteranceProgressListener))
and using the Engine#KEY_PARAM_UTTERANCE_ID parameter.
| Parameters | |
|---|---|
earcon |
String: The earcon that
should be played
|
queueMode |
int: QUEUE_ADD or QUEUE_FLUSH.
|
params |
HashMap: Parameters for the
request. Can be null. Supported parameter names: Engine#KEY_PARAM_STREAM, Engine#KEY_PARAM_UTTERANCE_ID. Engine specific parameters may be passed in
but the parameter keys must be prefixed by the name of the engine they are
intended for. For example the keys "com.svox.pico_foo" and "com.svox.pico:bar"
will be passed to the engine named "com.svox.pico" if it is being used.
|
playEarcon
public int playEarcon (String earcon, int queueMode, Bundle params, String utteranceId)
Plays the earcon using the specified queueing mode and parameters. The earcon must already have been added with addEarcon(java.lang.String, java.lang.String) or addEarcon(java.lang.String, java.lang.String, int). This method is asynchronous, i.e. the method just adds the request to the queue of TTS requests and then returns. The synthesis might not have finished (or even started!) at the time when this method returns. In order to reliably detect errors during synthesis, we recommend setting an utterance progress listener (see setOnUtteranceProgressListener(UtteranceProgressListener)) and using the Engine#KEY_PARAM_UTTERANCE_ID parameter.
| Parameters | |
|---|---|
earcon |
String: The earcon that should be played
|
queueMode |
int: QUEUE_ADD or QUEUE_FLUSH.
|
params |
Bundle: Parameters for the request. Can be null. Supported parameter names: Engine#KEY_PARAM_STREAM, Engine specific parameters may be passed in but the parameter keys must be prefixed by the name of the engine they are intended for. For example the keys "com.svox.pico_foo" and "com.svox.pico:bar" will be passed to the engine named "com.svox.pico" if it is being used.
|
utteranceId |
String
|
playSilence
Deprecated in API level 21
public int playSilence (long durationInMs,
int queueMode,
HashMap<String, String> params)
This method was deprecated in API level 21.
As of API level 21, replaced by playSilentUtterance(long,
int, java.lang.String).
Plays silence for the specified amount of time using the
specified queue mode. This method is asynchronous, i.e. the method just adds the
request to the queue of TTS requests and then returns. The synthesis might not
have finished (or even started!) at the time when this method returns. In order
to reliably detect errors during synthesis, we recommend setting an utterance
progress listener (see setOnUtteranceProgressListener(UtteranceProgressListener))
and using the Engine#KEY_PARAM_UTTERANCE_ID parameter.
| Parameters | |
|---|---|
durationInMs |
long: The duration of the
silence.
|
queueMode |
int: QUEUE_ADD or QUEUE_FLUSH.
|
params |
HashMap: Parameters for the
request. Can be null. Supported parameter names: Engine#KEY_PARAM_UTTERANCE_ID. Engine specific parameters may be passed in
but the parameter keys must be prefixed by the name of the engine they are
intended for. For example the keys "com.svox.pico_foo" and "com.svox.pico:bar"
will be passed to the engine named "com.svox.pico" if it is being used.
|
playSilentUtterance
public int playSilentUtterance (long durationInMs,
int queueMode,
String utteranceId)
Plays silence for the specified amount of time using the specified queue mode. This method is asynchronous, i.e. the method just adds the request to the queue of TTS requests and then returns. The synthesis might not have finished (or even started!) at the time when this method returns. In order to reliably detect errors during synthesis, we recommend setting an utterance progress listener (see setOnUtteranceProgressListener(UtteranceProgressListener)) and using the Engine#KEY_PARAM_UTTERANCE_ID parameter.
| Parameters | |
|---|---|
durationInMs |
long: The duration of the silence.
|
queueMode |
int: QUEUE_ADD or QUEUE_FLUSH.
|
utteranceId |
String: An unique identifier for this request.
|
setAudioAttributes
public int setAudioAttributes (AudioAttributes audioAttributes)
Sets the audio attributes to be used when speaking text or playing back a file.
| Parameters | |
|---|---|
audioAttributes |
AudioAttributes: Valid AudioAttributes instance.
|
setEngineByPackageName
Deprecated in API level 15
public int setEngineByPackageName (String enginePackageName)
This method was deprecated in API level 15.
This doesn't inform callers when the TTS engine has been
initialized. TextToSpeech(android.content.Context,
android.speech.tts.TextToSpeech.OnInitListener,
java.lang.String) can be used with
the appropriate engine name. Also, there is no guarantee that the engine
specified will be loaded. If it isn't installed or disabled, the user / system
wide defaults will apply.
Sets the TTS engine to use.
| Parameters | |
|---|---|
enginePackageName |
String: The package name for
the synthesis engine (e.g. "com.svox.pico")
|
setLanguage
public int setLanguage (Locale loc)
Sets the text-to-speech language. The TTS engine will try to use the closest match to the specified language as represented by the Locale, but there is no guarantee that the exact same Locale will be used. Use isLanguageAvailable(java.util.Locale) to check the level of support before choosing the language to use for the next utterances. This method sets the current voice to the default one for the given Locale; getVoice() can be used to retrieve it.
| Parameters | |
|---|---|
loc |
Locale: The locale describing the language to be used.
|
| Returns | |
|---|---|
int |
Code indicating the support status for the locale. See LANG_AVAILABLE, LANG_COUNTRY_AVAILABLE, LANG_COUNTRY_VAR_AVAILABLE, LANG_MISSING_DATA and LANG_NOT_SUPPORTED.
|
setOnUtteranceCompletedListener
Deprecated in API level 15
public int setOnUtteranceCompletedListener (TextToSpeech.OnUtteranceCompletedListener listener)
This method was deprecated in API level 15.
Use setOnUtteranceProgressListener(android.speech.tts.UtteranceProgressListener) instead.
Sets the listener that will be notified when synthesis of an utterance completes.
| Parameters | |
|---|---|
listener |
TextToSpeech.OnUtteranceCompletedListener: The listener to use.
|
setOnUtteranceProgressListener
public int setOnUtteranceProgressListener (UtteranceProgressListener listener)
Sets the listener that will be notified of various events related to the synthesis of a given utterance. See UtteranceProgressListener and TextToSpeech.Engine#KEY_PARAM_UTTERANCE_ID.
| Parameters | |
|---|---|
listener |
UtteranceProgressListener: the listener to use.
|
setPitch
public int setPitch (float pitch)
Sets the speech pitch for the TextToSpeech engine. This has no effect on any pre-recorded speech.
| Parameters | |
|---|---|
pitch |
float: Speech pitch. 1.0 is the normal pitch, lower values lower the tone of the synthesized voice, greater values increase it.
|
setSpeechRate
public int setSpeechRate (float speechRate)
Sets the speech rate. This has no effect on any pre-recorded speech.
| Parameters | |
|---|---|
speechRate |
float: Speech rate. 1.0 is the normal speech rate, lower values slow down the speech (0.5 is half the normal speech rate), greater values accelerate it (2.0 is twice the normal speech rate).
|
setVoice
public int setVoice (Voice voice)
Sets the text-to-speech voice.
| Parameters | |
|---|---|
voice |
Voice: One of objects returned by getVoices().
|
See also:
shutdown
public void shutdown ()
Releases the resources used by the TextToSpeech engine. It is good practice for instance to call this method in the onDestroy() method of an Activity so the TextToSpeech engine can be cleanly stopped.
speak
public int speak (CharSequence text, int queueMode, Bundle params, String utteranceId)
Speaks the text using the specified queuing strategy and speech parameters, the text may be spanned with TtsSpans. This method is asynchronous, i.e. the method just adds the request to the queue of TTS requests and then returns. The synthesis might not have finished (or even started!) at the time when this method returns. In order to reliably detect errors during synthesis, we recommend setting an utterance progress listener (see setOnUtteranceProgressListener(UtteranceProgressListener)) and using the Engine#KEY_PARAM_UTTERANCE_ID parameter.
| Parameters | |
|---|---|
text |
CharSequence: The string of text to be spoken. No longer than getMaxSpeechInputLength() characters.
|
queueMode |
int: The queuing strategy to use, QUEUE_ADD or QUEUE_FLUSH.
|
params |
Bundle: Parameters for the request. Can be null. Supported parameter names: Engine#KEY_PARAM_STREAM, Engine#KEY_PARAM_VOLUME, Engine#KEY_PARAM_PAN. Engine specific parameters may be passed in but the parameter keys must be prefixed by the name of the engine they are intended for. For example the keys "com.svox.pico_foo" and "com.svox.pico:bar" will be passed to the engine named "com.svox.pico" if it is being used.
|
utteranceId |
String: An unique identifier for this request.
|
speak
Deprecated in API level 21
public int speak (String text, int queueMode, HashMap<String, String> params)
This method was deprecated in API level 21.
As of API level 21, replaced by speak(java.lang.CharSequence,
int, android.os.Bundle, java.lang.String).
Speaks the string using the specified queuing strategy and
speech parameters. This method is asynchronous, i.e. the method just adds the
request to the queue of TTS requests and then returns. The synthesis might not
have finished (or even started!) at the time when this method returns. In order
to reliably detect errors during synthesis, we recommend setting an utterance
progress listener (see setOnUtteranceProgressListener(UtteranceProgressListener))
and using the Engine#KEY_PARAM_UTTERANCE_ID parameter.
| Parameters | |
|---|---|
text |
String: The string of text to
be spoken. No longer than getMaxSpeechInputLength() characters.
|
queueMode |
int: The queuing strategy to
use, QUEUE_ADD or QUEUE_FLUSH.
|
params |
HashMap: Parameters for the
request. Can be null. Supported parameter names: Engine#KEY_PARAM_STREAM, Engine#KEY_PARAM_UTTERANCE_ID, Engine#KEY_PARAM_VOLUME, Engine#KEY_PARAM_PAN. Engine
specific parameters may be passed in but the parameter keys must be prefixed by
the name of the engine they are intended for. For example the keys
"com.svox.pico_foo" and "com.svox.pico:bar" will be passed to the engine named
"com.svox.pico" if it is being used.
|
stop
public int stop ()
Interrupts the current utterance (whether played or rendered to file) and discards other utterances in the queue.
synthesizeToFile
public int synthesizeToFile (CharSequence text, Bundle params, ParcelFileDescriptor fileDescriptor, String utteranceId)
Synthesizes the given text to a ParcelFileDescriptor using the specified parameters. This method is asynchronous, i.e. the method just adds the request to the queue of TTS requests and then returns. The synthesis might not have finished (or even started!) at the time when this method returns. In order to reliably detect errors during synthesis, we recommend setting an utterance progress listener (see setOnUtteranceProgressListener(UtteranceProgressListener)).
| Parameters | |
|---|---|
text |
CharSequence: The text that should be synthesized. No longer than getMaxSpeechInputLength() characters. This value cannot be null.
|
params |
Bundle: Parameters for the request. Engine specific parameters may be passed in but the parameter keys must be prefixed by the name of the engine they are intended for. For example the keys "com.svox.pico_foo" and "com.svox.pico:bar" will be passed to the engine named "com.svox.pico" if it is being used. This value cannot be null.
|
fileDescriptor |
ParcelFileDescriptor: ParcelFileDescriptor to write the generated audio data to. This value cannot be null.
|
utteranceId |
String: An unique identifier for this request. This value cannot be null.
|
synthesizeToFile
public int synthesizeToFile (CharSequence text, Bundle params, File file, String utteranceId)
Synthesizes the given text to a file using the specified parameters. This method is asynchronous, i.e. the method just adds the request to the queue of TTS requests and then returns. The synthesis might not have finished (or even started!) at the time when this method returns. In order to reliably detect errors during synthesis, we recommend setting an utterance progress listener (see setOnUtteranceProgressListener(UtteranceProgressListener)).
| Parameters | |
|---|---|
text |
CharSequence: The text that should be synthesized. No longer than getMaxSpeechInputLength() characters.
|
params |
Bundle: Parameters for the request. Cannot be null. Engine specific parameters may be passed in but the parameter keys must be prefixed by the name of the engine they are intended for. For example the keys "com.svox.pico_foo" and "com.svox.pico:bar" will be passed to the engine named "com.svox.pico" if it is being used.
|
file |
File: File to write the generated audio data to.
|
utteranceId |
String: An unique identifier for this request.
|
synthesizeToFile
Deprecated in API level 21
public int synthesizeToFile (String text, HashMap<String, String> params, String filename)
This method was deprecated in API level 21.
As of API level 21, replaced by synthesizeToFile(java.lang.CharSequence,
android.os.Bundle, java.io.File, java.lang.String).
Synthesizes the given text to a file using the specified
parameters. This method is asynchronous, i.e. the method just adds the request
to the queue of TTS requests and then returns. The synthesis might not have
finished (or even started!) at the time when this method returns. In order to
reliably detect errors during synthesis, we recommend setting an utterance
progress listener (see setOnUtteranceProgressListener(UtteranceProgressListener))
and using the Engine#KEY_PARAM_UTTERANCE_ID parameter.
| Parameters | |
|---|---|
text |
String: The text that should
be synthesized. No longer than getMaxSpeechInputLength() characters.
|
params |
HashMap: Parameters for the
request. Cannot be null. Supported parameter names: Engine#KEY_PARAM_UTTERANCE_ID. Engine specific parameters may be passed in
but the parameter keys must be prefixed by the name of the engine they are
intended for. For example the keys "com.svox.pico_foo" and "com.svox.pico:bar"
will be passed to the engine named "com.svox.pico" if it is being used.
|
filename |
String: Absolute file
filename to write the generated audio data to.It should be something like
"/sdcard/myappsounds/mysound.wav".
|