add by zhj:
TCP的心跳包默认是2小时发一次,频次这么低,我理解是因为TCP是一个传输层协议,比较底层,上层很多应用层协议都用到它。如果TCP心跳间隔很短,那对系统性能可能产生比较大的影响。
如果应用层协议感觉这个间隔太长,那可以自己发心跳包。比如服务注册中心与服务之间就是长连接,通过发送间隔比较短的心跳包(一般是秒级)来及时感知对方的状态,根据状态采取相应的动作。
原文:http://hengyunabc.github.io/why-we-need-heartbeat/
作者:横云断岭
TCP keep-alive的三个参数
用man命令,可以查看linux的tcp的参数:
1
|
man 7 tcp
|
其中keep-alive相关的参数有三个:
1
|
tcp_keepalive_intvl (integer; default: 75; since Linux 2.4)
|
这些的默认配置值在/proc/sys/net/ipv4 目录下可以找到。
可以直接用cat来查看文件的内容,就可以知道配置的值了。
也可以通过sysctl命令来查看和修改:
1
|
# 查询
|
上面三个是系统级的配置,在编程时有三个参数对应,可以覆盖掉系统的配置:
1
|
TCP_KEEPCNT 覆盖 tcp_keepalive_probes,默认9(次)
|
tcp keep-alive的本质
TCP keep-alive probe
上面了解了tcp keep-alive的一些参数,下面来探究下其本质。
在远程机器192.168.66.123上,用nc启动一个TCP服务器:
1
|
nc -l 9999
|
在本地机器上,用python创建一个socket去连接,并且用wireshark抓包分析
1
|
import socket
|
上面的程序,设置了TCP_KEEPIDLE为20,TCP_KEEPINTVL为1,系统默认的tcp_keepalive_probes是9。
当网络正常,不做干扰时,wireshark抓包的数据是这样的(注意看第二列Time):
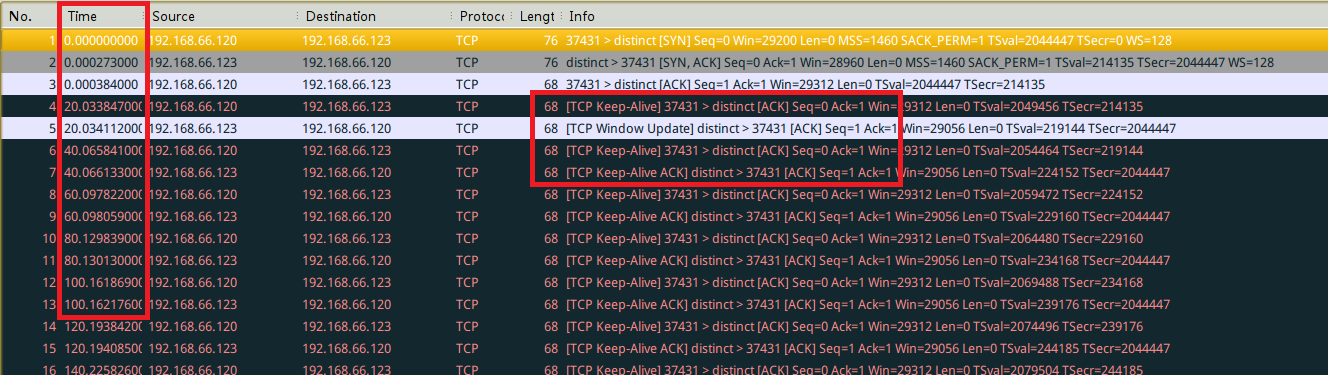
可以看到,当3次握手完成之后,每隔20秒之后66.120发送了一个TCP Keep-Alive的数据包,然后66.123回应了一个TCP Keep-Alive ACK包。这个就是TCP keep-alive的实现原理了。
当发送了第一个TCP Keep-Alive包之后,拨掉192.168.66.123的网线,然后数据包是这样子的: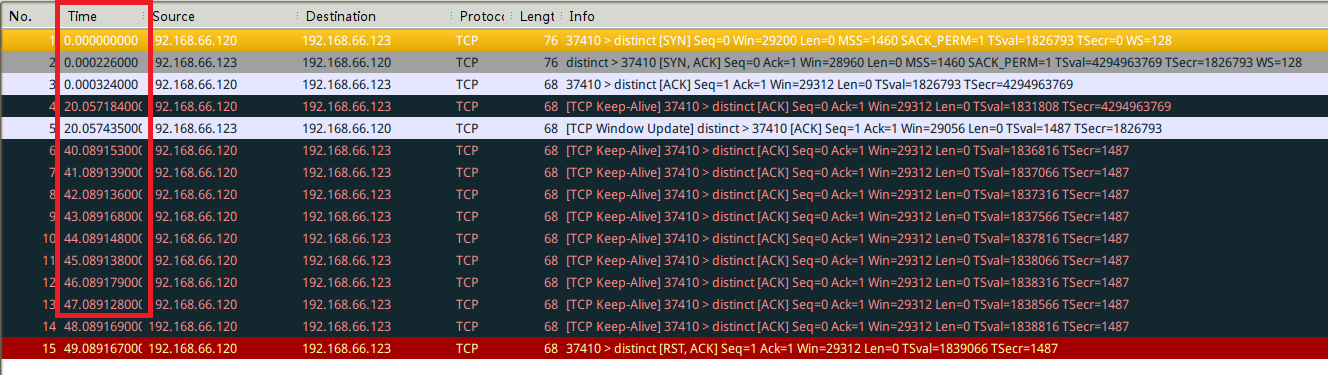
可以看到,当远程服务器192.168.66.123网络失去连接之后,本地机器(192.168.66.120)每隔一秒重发了9次tcp keep-alive probe,最终认为这个TCP连接已经失效,发了一个RST包给192.168.66.123。
三个参数的具体意义
TCP_KEEPIDLE :这个参数是多久没有发送数据时,开始发送Keep-Alive包的时间,也就是链路空闲时间。
TCP_KEEPINTVL:这个参数是指发送Keep-Alive probe后,对方多久没有回应,然后重新再发送keep alive probe的时间间隔
TCP_KEEPCNT:这个参数指,连续发送多少次keep alive probe,对方没有回应,认为连接已经失效的重试次数
如果不能理解或者有混淆,仔细对照下上面的两张图片就可以明白了。
为什么应用层需要heart beat/心跳包?
默认的tcp keep-alive超时时间太长
默认是7200秒,也就是2个小时。
socks proxy会让tcp keep-alive失效
socks协议只管转发TCP层具体的数据包,而不会转发TCP协议内的实现细节的包(也做不到),参考socks_proxy。
所以,一个应用如果使用了socks代理,那么tcp keep-alive机制就失效了,所以应用要自己有心跳包。
socks proxy只是一个例子,真实的网络很复杂,可能会有各种原因让tcp keep-alive失效。
移动网络需要信令保活
前两年,微信信令事件很火,搜索下“微信 信令”或者“移动网络 信令”可以查到很多相关文章。
这里附上一个链接:微信的大规模使用真的会过多占用信令,影响通讯稳定吗?
总结
-
TCP keep-alive是通过在空闲时发送TCP Keep-Alive数据包,然后对方回应TCP Keep-Alive ACK来实现的。
-
为什么需要heart beat/心跳包?因为tcp keep-alive不能满足人们的实时性的要求,就是这么简单。
