写这篇文章,主要是因为最近有个课题设计,里面用的字符串匹配。
学习后缀树之前,先了解一下Trie这个数据结构
Trie是一种
搜索树,可用于存储并查找字符串。Trie每一条边都对应一个字符。在Trie中查找字符串S时,只要按顺序枚举S的各个字符,从Trie的根节点开始选
择相应的边走,如果枚举完的同时恰好走到Trie树的叶子节点,说明S存在于Trie中。如果未到达叶子节点,或者枚举中未发现相应的边,则S没有被包含
在Trie中。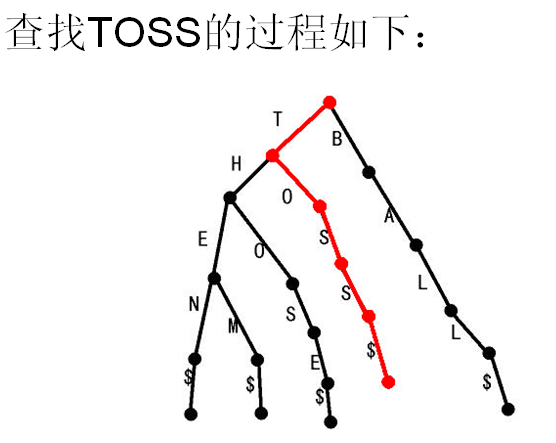
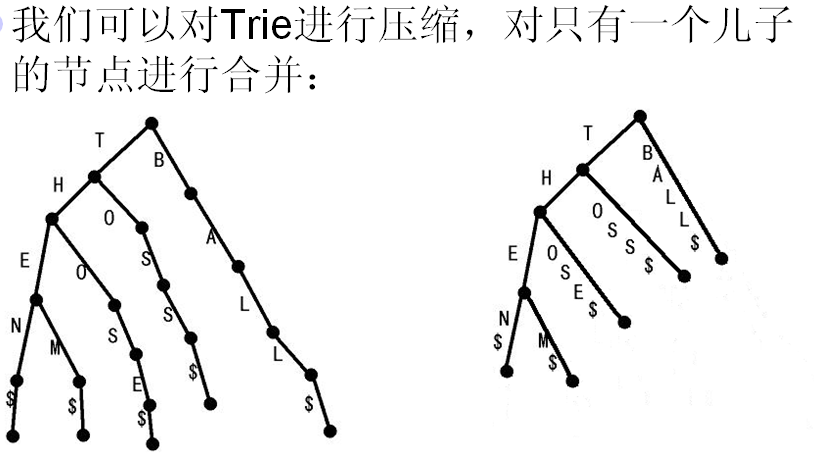
后缀树就是一种压缩后的Trie树。
比如 S:banana,对S建立后缀树。
首先给出S的后缀们
0:banana
1:anana
2:nana
3:ana
4:na
5:a
6:空
为了更清楚的表示后缀,我们在后缀的后面加上$
0:banana$
1:anana$
2:nana$
3:ana$
4:na$
5:a$
6:$
然后对其进行分类:
5: a$
3: ana$
1: anana$
0: banana$
4: na$
2: nana$
6: $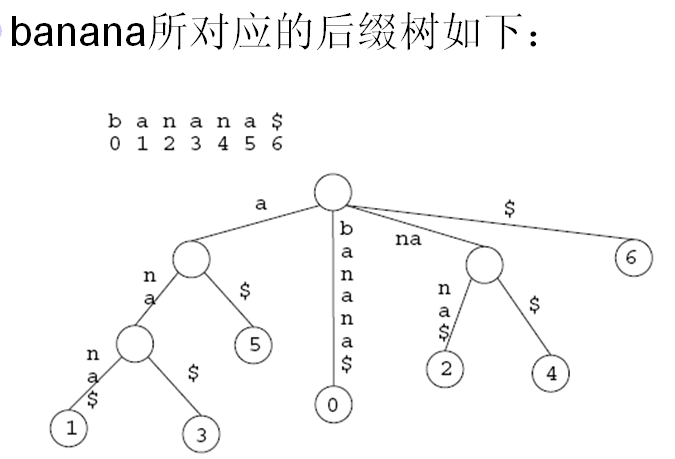
后缀树的应用:
example 1:在树中查找an(查找子字符串)
example 2:统计S中出现字符串T的个数
没出现一次T,都对应着一个不同的后缀,而这些后缀们又对应着同一个前缀T,因此这些后缀必定都属于同一棵子树,这棵子树的分支数就是T在S中出现的次数。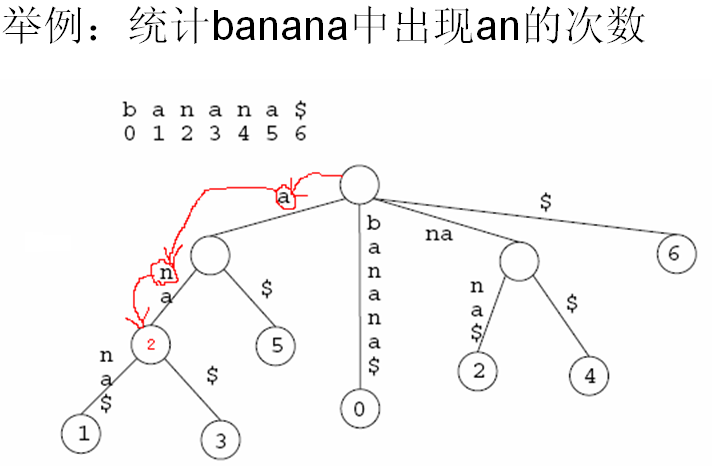
example 3:找出S中最长的重复子串,所谓重复子串,是指出现了两次以上
首先定义节点的 ”字符深度“ = 从后缀树根节点到每个节点所经过的字符串总长。找出有最大字符深度的非叶节点。则从根节点到该非叶节点所经过的字符串即为所求。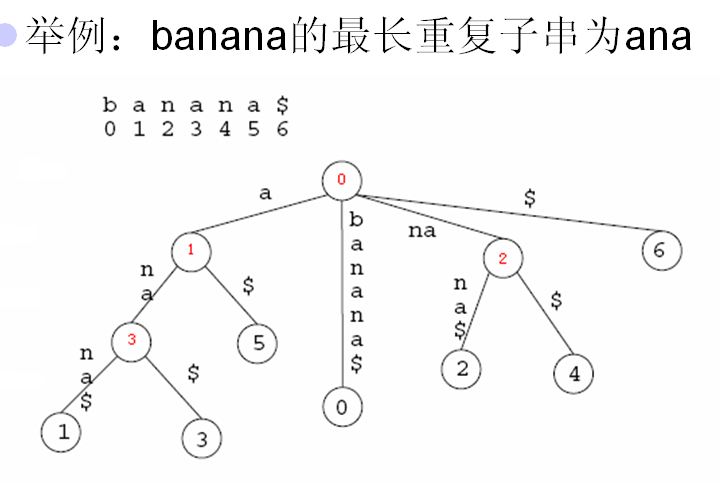
后缀树的存储:
为了节省空间,我们不在边上存储字符串,而是存储该字符串在原串中的起止位置。空间复杂度O(n)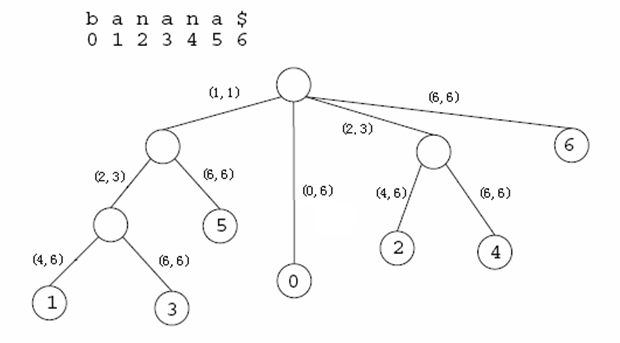
后缀树的构造:
最简单的方法,使用Trie的构造方法,时间复杂度为O(n^2)
后缀树也可以在O(n)的时间复杂度内构造,但比较复杂
如
基本思路:先向后缀树中插入最长的后缀串(S本身),其次插入次长的后缀串,以此类推,最后插入空串。
定义后缀链接(Suffix Link)=从节点A指向节点B的指针,B所表示的子串是A所表示的子串的最长后缀。既,根节点到A所经过的字符串s=aw,则从根节点到B所经过的字符串为w。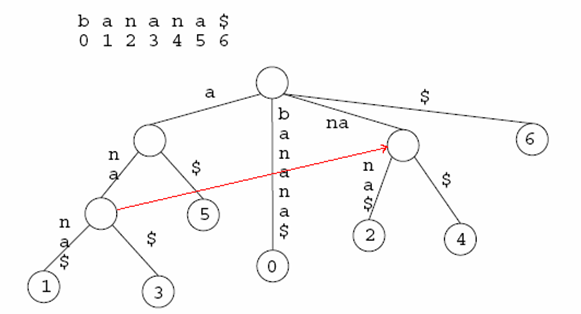
算法所用符号描述:
后缀树的构造,算法流程:
1)定义SL(root)=root,首先插入S,此时后缀树仅有两个节点。
2)设已经插入了S(i),现在要插入S(i+1),分两种情况讨论:
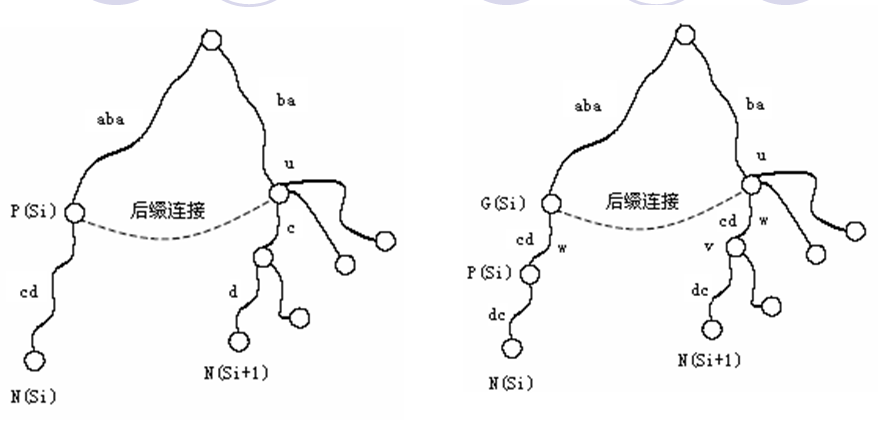
1:P(S(i))在插入之前已经存在,(如,na,ana,a是na的parent),则P(S(i))有后缀链接,令u=SL(P(S(i))),从u开始沿着树往下查找,在合适的地方插入
2:P(S(i))
是插入S(i)过程中产生的,此时G(S(i))必定存在并有后缀链接,比如(na,ana,bana),令
u=SL(G(S(i))),w=W(G(S(i)),P(S(i))).从u开始,对w进行快速定位,并找到节点v(v可能需要分割边来得到)。令
SL(G(S(i)))指向v,从v开始沿着树往下查找,在合适的地方插入新的节点
不断重复以上步骤,即可完成后缀树的构造。