本文介绍一下有关语言模型的基本概念,但是在介绍语言模型之前,先简单回顾一下自然语言处理这个大问题吧。现在自然语言处理的研究绝对是一个非常火热的方向,主要是被当前的互联网发展所带动起来的。在互联网上充斥着大量的信息,主要是文字方面的信息,对这些信息的处理离不开自然语言处理的技术。那么究竟什么是自然语言以及自然语言处理呢?
1. 自然语言处理的基本任务
自然语言(Natural Language)其实就是人类语言,自然语言处理(NLP)就是对人类语言的处理,当然主要是利用计算机。自然语言处理是关于计算机科学和语言学的交叉学科,常见的研究任务包括:
· 分词(Word Segmentation或Word Breaker,WB)
· 信息抽取(Information Extraction,IE)
· 关系抽取(Relation Extraction,RE)
· 命名实体识别(Named Entity Recognition,NER)
· 词性标注(Part Of Speech Tagging,POS)
· 指代消解(Coreference Resolution)
· 句法分析(Parsing)
· 词义消歧(Word Sense Disambiguation,WSD)
· 语音识别(Speech Recognition)
· 语音合成(Text To Speech,TTS)
· 机器翻译(Machine Translation,MT)
· 自动文摘(Automatic Summarization)
· 问答系统(Question Answering)
· 自然语言理解(Natural Language Understanding)
· 光学字符识别(Optical Character Recognition,OCR)
· 信息检索(Information Retrieval,IR)
早期的自然语言处理系统主要是基于人工撰写的规则,这种方法费时费力,且不能覆盖各种语言现象。上个世纪80年代后期,机器学习算法被引入到自然语言处理中,这要归功于不断提高的计算能力。研究主要集中在统计模型上,这种方法采用大规模的训练语料(corpus)对模型的参数进行自动的学习,和之前的基于规则的方法相比,这种方法更具鲁棒性。
2. 统计语言模型
统计语言模型(Statistical Language Model)就是在这样的环境和背景下被提出来的。它广泛应用于各种自然语言处理问题,如语音识别、机器翻译、分词、词性标注,等等。简单地说,语言模型就是用来计算一个句子的概率的模型,即P(W1,W2,...Wk)。利用语言模型,可以确定哪个词序列的可能性更大,或者给定若干个词,可以预测下一个最可能出现的词语。举个音字转换的例子来说,输入拼音串为nixianzaiganshenme,对应的输出可以有多种形式,如你现在干什么、你西安再赶什么、等等,那么到底哪个才是正确的转换结果呢,利用语言模型,我们知道前者的概率大于后者,因此转换成前者在多数情况下比较合理。再举一个机器翻译的例子,给定一个汉语句子为李明正在家里看电视,可以翻译为Li Ming is watching TV at home、Li Ming at home is watching TV、等等,同样根据语言模型,我们知道前者的概率大于后者,所以翻译成前者比较合理。
那么如何计算一个句子的概率呢?给定句子(词语序列)S=W1,W2,...,Wk,它的概率可以表示为:
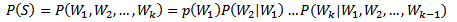 (1)
(1)
由于上式中的参数过多,因此需要近似的计算方法。常见的方法有n-gram模型方法、决策树方法、最大熵模型方法、最大熵马尔科夫模型方法、条件随机域方法、神经网络方法,等等。
3. n-gram语言模型
3.1 n-gram模型的概念
n-gram模型也称为n-1阶马尔科夫模型,它有一个有限历史假设:当前词的出现概率仅仅与前面n-1个词相关。因此(1)式可以近似为:
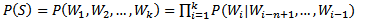 (2)
(2)
当n取1、2、3时,n-gram模型分别称为unigram、bigram和trigram语言模型。n-gram模型的参数就是条件概率P(Wi|Wi-n+1,...,Wi-1)。假设词表的大小为100,000,那么n-gram模型的参数数量为100,000n。n越大,模型越准确,也越复杂,需要的计算量越大。最常用的是bigram,其次是unigram和trigram,n取≥4的情况较少。
3.2 n-gram模型的参数估计
模型的参数估计也称为模型的训练,一般采用最大似然估计(Maximum Likelihood Estimation,MLE)的方法对模型的参数进行估计:
 (3)
(3)
C(X)表示X在训练语料中出现的次数,训练语料的规模越大,参数估计的结果越可靠。但即使训练数据的规模很大,如若干GB,还是会有很多语言现象在训练语料中没有出现过,这就会导致很多参数(某n元对的概率)为0。举个例子来说明一下,IBM Brown利用366M英语语料训练trigram,结果在测试语料中,有14.7%的trigram和2.2%的bigram在训练中没有出现;根据博士期间所在的实验室统计结果,利用500万字人民日报训练bigram模型,用150万字人民日报作为测试语料,结果有23.12%的bigram没有出现。
这种问题也被称为数据稀疏(Data Sparseness),解决数据稀疏问题可以通过数据平滑(Data Smoothing)技术来解决。
3.3 n-gram模型的数据平滑
数据平滑是对频率为0的n元对进行估计,典型的平滑算法有加法平滑、Good-Turing平滑、Katz平滑、插值平滑,等等。
· 加法平滑
基本思想是为避免零概率问题,将每个n元对得出现次数加上一个常数δ(0<δ≤1):
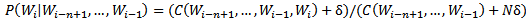 (4)
(4)
· Good-Turing平滑
利用频率的类别信息来对频率进行平滑:
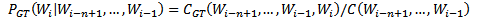 (5)
(5)

其中,N(c)表示频率为c的n-gram的数量。
· 线性插值平滑
该数据平滑技术主要利用低元n-gram模型对高元n-gram模型进行线性插值。因为在没有足够的数据对高元n-gram模型进行概率估计时,低元n-gram模型通常可以提供有用的信息。
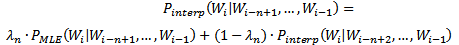 (6)
(6)
λn可以通过EM算法来估计。
· Katz平滑
也称为回退(back-off)平滑,其基本思想是当一个n元对的出现次数足够大时,用最大似然估计方法估计其概率;当n元对的出现次数不够大时,采用Good-Turing估计对其平滑,将其部分概率折扣给未出现的n元对;当n元对的出现次数为0时,模型回退到低元模型。
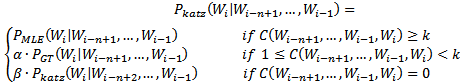 (7)
(7)
参数α和β保证模型参数概率的归一化约束条件,即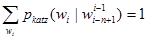 。
。
3.4 n-gram模型的解码算法
为什么n-gram模型需要解码算法呢?举个例子来说,对于音字转换问题,输入拼音nixianzaiganshenme,可能对应着很多转换结果,对于这个例子,可能的转换结果如下图所示(只画出部分的词语节点),各节点之间构成了复杂的网络结构,从开始到结束的任意一条路径都是可能的转换结果,从诸多转换结果中选择最合适的结果的过程就需要解码算法。
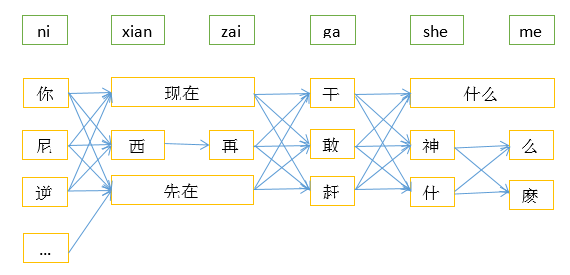
常用的解码算法是viterbi算法,它采用动态规划的原理能够很快地确定最合适的路径。这里就不详细介绍该算法了。
3.5 n-gram模型的应用
n-gram语言模型的应用非常广泛,最早期的应用是语音识别、机器翻译等问题。哈尔滨工业大学王晓龙教授最早将其应用到音字转换问题,提出了“语句级拼音输入法”,后来该技术转让给微软,也就是后来的微软拼音输入法。从windows95开始,系统就会自动安装该输入法,并在以后更高版本的windows中和Office办公软件都会集成最新的微软拼音输入法。n年之后,各个输入法的新秀(如搜狗和谷歌)也都采用了n-gram技术。