在连接/合并类型操作的情况下,pandas提供了各种功能,可以轻松地将Series或DataFrame与各种用于索引和关系代数功能的集合逻辑组合在一起。
此外,pandas还提供实用程序来比较两个Series或DataFrame并总结它们之间的差异。
拼接对象
该concat()函数(在pandas主命名空间中)在执行沿轴的串联操作的所有繁重工作,同时在其他轴上执行索引(如果有)的可选设置逻辑(联合或交集)。请注意,我之所以说“如果有”,是因为Series只有一个可能的串联轴。
在深入探讨其所有细节及其功能之前concat,这里有一个简单的示例:
In [1]: df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
...: 'B': ['B0', 'B1', 'B2', 'B3'],
...: 'C': ['C0', 'C1', 'C2', 'C3'],
...: 'D': ['D0', 'D1', 'D2', 'D3']},
...: index=[0, 1, 2, 3])
...:
In [2]: df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
...: 'B': ['B4', 'B5', 'B6', 'B7'],
...: 'C': ['C4', 'C5', 'C6', 'C7'],
...: 'D': ['D4', 'D5', 'D6', 'D7']},
...: index=[4, 5, 6, 7])
...:
In [3]: df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
...: 'B': ['B8', 'B9', 'B10', 'B11'],
...: 'C': ['C8', 'C9', 'C10', 'C11'],
...: 'D': ['D8', 'D9', 'D10', 'D11']},
...: index=[8, 9, 10, 11])
...:
In [4]: frames = [df1, df2, df3]
In [5]: result = pd.concat(frames)
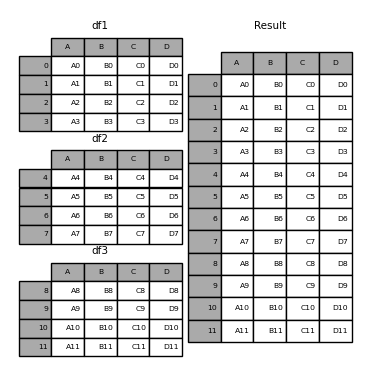
与其在ndarrays上的同级函数一样numpy.concatenate,,pandas.concat 获取同类类型对象的列表或字典,并将它们与“对其他轴的操作”的一些可配置处理进行连接:
pd.concat(objs, axis=0, join='outer', ignore_index=False, keys=None,
levels=None, names=None, verify_integrity=False, copy=True)
-
objs:Series或DataFrame对象的序列或映射。如果传递了dict,则排序的键将用作keys参数,除非传递了dict ,在这种情况下,将选择值(请参见下文)。除非所有对象都为None,否则所有None对象都将被静默删除,在这种情况下将引发ValueError。 -
axis:{0,1,…},默认值为0。要沿其连接的轴。 -
join:{'inner','outer'},默认为'outer'。如何处理其他轴上的索引。外部为联合,内部为交叉。 -
ignore_index:布尔值,默认为False。如果为True,则不要在串联轴上使用索引值。结果轴将标记为0,…,n-1。如果要串联对象时,串联轴没有有意义的索引信息,这将很有用。请注意,联接中仍会考虑其他轴上的索引值。 -
keys:序列,默认为无。使用传递的键作为最外层级别来构造层次结构索引。如果通过了多个级别,则应包含元组。 -
levels:序列列表,默认为无。用于构造MultiIndex的特定级别(唯一值)。否则,将从按键推断出它们。 -
names:列表,默认为无。生成的层次结构索引中的级别的名称。 -
verify_integrity:布尔值,默认为False。检查新的串联轴是否包含重复项。相对于实际数据串联而言,这可能非常昂贵。 -
copy:布尔值,默认为True。如果为False,则不要不必要地复制数据。
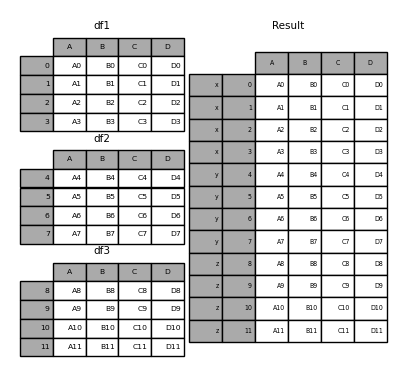
没有一点上下文,这些论点中的许多就没有多大意义。让我们回顾一下上面的例子。假设我们想将特定的键与切碎的DataFrame的每个片段相关联。我们可以使用keys参数来做到这一点 :
In [6]: result = pd.concat(frames, keys=['x', 'y', 'z'])
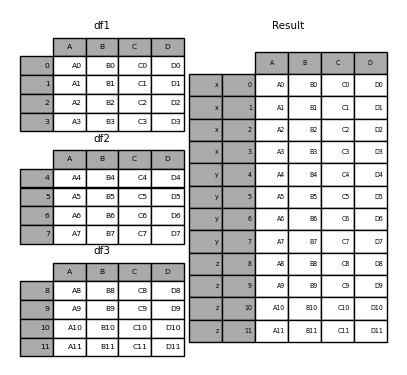
如您所见(如果您已经阅读了文档的其余部分),结果对象的索引具有层次结构索引。这意味着我们现在可以通过键选择每个块:
In [7]: result.loc['y']
Out[7]:
A B C D
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
看到这如何非常有用并不是一件容易的事。有关此功能的更多详细信息,请参见下文。
注意
值得注意的是concat()(并因此 append())制作了数据的完整副本,并且不断地重用此功能可能会严重影响性能。如果需要对多个数据集使用该操作,请使用列表推导。
frames = [ process_your_file(f) for f in files ]
result = pd.concat(frames)
在其他轴组逻辑
将多个DataFrame粘合在一起时,可以选择如何处理其他轴(而不是串联的轴)。这可以通过以下两种方式完成:
-
把它们全部结合起来
join='outer'。这是默认选项,因为它导致零信息丢失。 -
以十字路口为准
join='inner'。
这是每种方法的一个示例。一,默认join='outer' 行为:
In [8]: df4 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'],
...: 'D': ['D2', 'D3', 'D6', 'D7'],
...: 'F': ['F2', 'F3', 'F6', 'F7']},
...: index=[2, 3, 6, 7])
...:
In [9]: result = pd.concat([df1, df4], axis=1, sort=False)
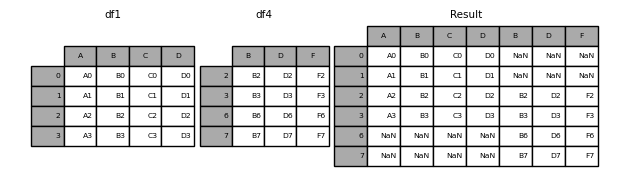
警告
在版本0.23.0中更改。
默认行为join='outer'是对其他轴排序(在这种情况下为列)。在未来版本的熊猫中,默认设置为不排序。我们指定sort=False现在选择加入新行为。
这是同一件事join='inner':
In [10]: result = pd.concat([df1, df4], axis=1, join='inner')

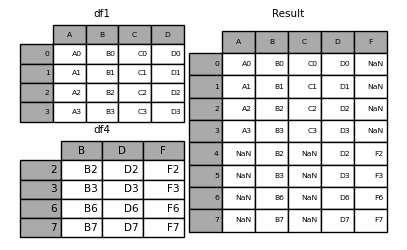
最后,假设我们只是想重用原始DataFrame中的确切索引:
In [11]: result = pd.concat([df1, df4], axis=1).reindex(df1.index)
同样,我们可以在连接之前建立索引:
In [12]: pd.concat([df1, df4.reindex(df1.index)], axis=1)
Out[12]:
A B C D B D F
0 A0 B0 C0 D0 NaN NaN NaN
1 A1 B1 C1 D1 NaN NaN NaN
2 A2 B2 C2 D2 B2 D2 F2
3 A3 B3 C3 D3 B3 D3 F3

使用串联append
一个有用的快捷方式concat()是append() 在实例方法Series和DataFrame。这些方法实际上早于 concat。它们串联在一起axis=0,即索引:
In [13]: result = df1.append(df2)

对于DataFrame,索引必须是不相交的,但列不必是:
In [14]: result = df1.append(df4, sort=False)

append 可能需要多个对象来串联:
In [15]: result = df1.append([df2, df3])

注意
与append()追加到原始列表并返回的方法不同None,append() 这里的方法不会修改 df1并返回带有df2追加内容的副本。
忽略串联轴上的索引
对于DataFrame没有有意义索引的对象,您可能希望追加它们,而忽略它们可能具有重叠索引的事实。为此,请使用ignore_index参数:
In [16]: result = pd.concat([df1, df4], ignore_index=True, sort=False)
这也是有效的参数DataFrame.append():
In [17]: result = df1.append(df4, ignore_index=True, sort=False)

与混合ndim串联
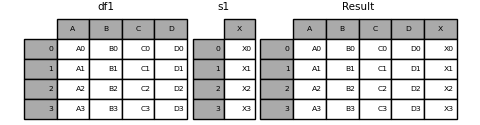
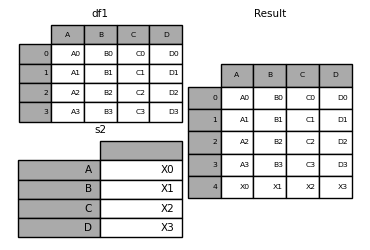
您可以将Series和混合在一起DataFrame。该 Series会转化为DataFrame与列名的名称Series。
In [18]: s1 = pd.Series(['X0', 'X1', 'X2', 'X3'], name='X')
In [19]: result = pd.concat([df1, s1], axis=1)
注意
由于我们将a串联Series到a DataFrame,因此我们可以用达到相同的结果DataFrame.assign()。要串联任意数量的熊猫对象(DataFrame或Series),请使用 concat。
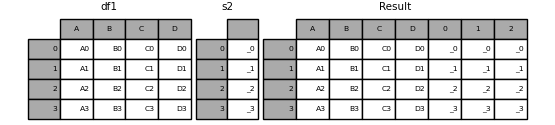
如果未命名Series,则将连续编号。
In [20]: s2 = pd.Series(['_0', '_1', '_2', '_3'])
In [21]: result = pd.concat([df1, s2, s2, s2], axis=1)
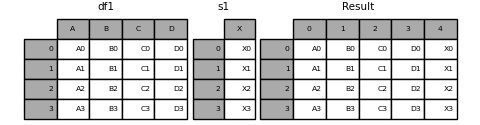
通过ignore_index=True将删除所有名称引用。
In [22]: result = pd.concat([df1, s1], axis=1, ignore_index=True)
与组键更多串联
该keys参数的一个相当普遍的用法是在DataFrame基于现有的创建新参数时覆盖列名称Series。请注意,默认行为是如何使结果(如果存在)DataFrame 继承父Series名称的。
In [23]: s3 = pd.Series([0, 1, 2, 3], name='foo')
In [24]: s4 = pd.Series([0, 1, 2, 3])
In [25]: s5 = pd.Series([0, 1, 4, 5])
In [26]: pd.concat([s3, s4, s5], axis=1)
Out[26]:
foo 0 1
0 0 0 0
1 1 1 1
2 2 2 4
3 3 3 5
通过keys参数,我们可以覆盖现有的列名。
In [27]: pd.concat([s3, s4, s5], axis=1, keys=['red', 'blue', 'yellow'])
Out[27]:
red blue yellow
0 0 0 0
1 1 1 1
2 2 2 4
3 3 3 5
让我们考虑第一个示例的变体:
In [28]: result = pd.concat(frames, keys=['x', 'y', 'z'])

您还可以将dict传递给,concat在这种情况下,dict键将用作keys参数(除非指定了其他键):
In [29]: pieces = {'x': df1, 'y': df2, 'z': df3}
In [30]: result = pd.concat(pieces)
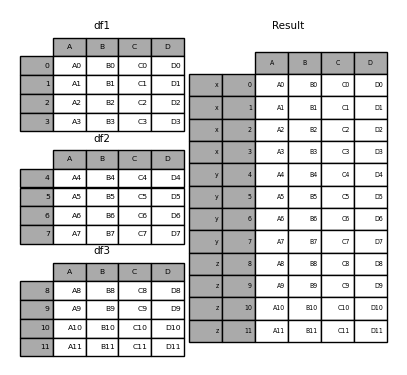
In [31]: result = pd.concat(pieces, keys=['z', 'y'])
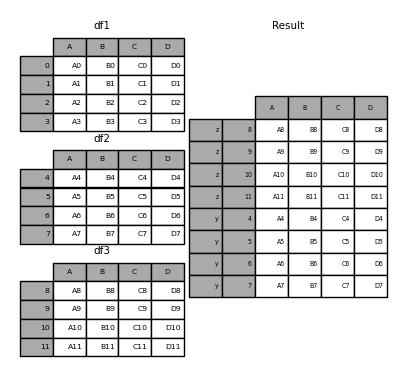
创建的MultiIndex具有从传递的键和DataFrame片段的索引构成的级别:
In [32]: result.index.levels
Out[32]: FrozenList([['z', 'y'], [4, 5, 6, 7, 8, 9, 10, 11]])
如果您希望指定其他级别(有时会这样),则可以使用以下levels参数:
In [33]: result = pd.concat(pieces, keys=['x', 'y', 'z'],
....: levels=[['z', 'y', 'x', 'w']],
....: names=['group_key'])
....:
In [34]: result.index.levels
Out[34]: FrozenList([['z', 'y', 'x', 'w'], [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]])
这是相当深奥的,但是实际上对于实现GroupBy之类的东西(分类变量的顺序有意义)是必要的。
行追加到数据帧
尽管效率不是特别高(因为必须创建一个新对象),但您可以DataFrame通过向传递一个Series或dict来将单个行附加到上 append,这将DataFrame如上所述返回一个新值。
In [35]: s2 = pd.Series(['X0', 'X1', 'X2', 'X3'], index=['A', 'B', 'C', 'D'])
In [36]: result = df1.append(s2, ignore_index=True)
您应该使用ignore_index此方法来指示DataFrame放弃其索引。如果希望保留索引,则应构造一个索引适当的DataFrame并附加或连接这些对象。
您还可以传递字典或系列的列表:
In [37]: dicts = [{'A': 1, 'B': 2, 'C': 3, 'X': 4},
....: {'A': 5, 'B': 6, 'C': 7, 'Y': 8}]
....:
In [38]: result = df1.append(dicts, ignore_index=True, sort=False)

数据库样式的DataFrame或命名的Series加入/合并
pandas具有功能全面的,高性能的内存中连接操作,这在逻辑上与SQL等关系数据库非常相似。与其他开放源代码实现(如base::merge.data.frame R中)相比,这些方法的性能明显更好(在某些情况下要好一个数量级)。这样做的原因是仔细的算法设计和.NET中数据的内部布局DataFrame。
有关某些高级策略,请参见本食谱。
熟悉SQL但对熊猫不熟悉的用户可能会对与SQL的比较感兴趣 。
pandas提供了一个功能,merge()作为DataFrame或命名Series对象之间所有标准数据库联接操作的入口点:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)
-
left:一个DataFrame或命名为Series的对象。 -
right:另一个DataFrame或命名为Series的对象。 -
on:要加入的列或索引级别名称。必须在左右DataFrame和/或Series对象中找到。如果没有通过,left_index并且right_index是False在DataFrames和/或系列列的交叉点会被推断为联接键。 -
left_on:左侧DataFrame或Series中的列或索引级别用作键。可以是列名称,索引级别名称,也可以是长度等于DataFrame或Series长度的数组。 -
right_on:右侧DataFrame或Series中的列或索引级别用作键。可以是列名称,索引级别名称,也可以是长度等于DataFrame或Series长度的数组。 -
left_index:如果为True,则使用左侧DataFrame或Series中的索引(行标签)作为其连接键。对于具有MultiIndex(分层结构)的DataFrame或Series,级别数必须与正确的DataFrame或Series中的联接键数匹配。 -
right_index:与left_index正确的DataFrame或Series的用法相同 -
how:其一'left','right','outer','inner'。默认为inner。有关每种方法的详细说明,请参见下文。 -
sort:按字典顺序按连接键对结果DataFrame进行排序。默认为True,设置为False可以在许多情况下显着提高性能。 -
suffixes:适用于重叠列的字符串后缀元组。默认为。('_x', '_y') -
copy注意:始终True从传递的DataFrame或命名的Series对象复制数据(默认),即使不需要重新索引也是如此。在很多情况下都无法避免,但是可以提高性能/内存使用率。可以避免复制的情况有些病态,但是仍然提供了此选项。 -
indicator:将一列添加到输出DataFrame中_merge,并在每一行的源上提供信息。_merge是分类类型的,left_only对于其合并键仅出现在'left'DataFrame或Series中right_only的观察值,对于仅其合并键仅出现在'right'DataFrame或Series中both的观察值以及在两个视图中均找到观察值的合并键,则取值为。 -
validate:字符串,默认为无。如果指定,则检查合并是否为指定的类型。-
“ one_to_one”或“ 1:1”:检查合并键在左右数据集中是否唯一。
-
“ one_to_many”或“ 1:m”:检查合并键在左数据集中是否唯一。
-
“ many_to_one”或“ m:1”:检查合并键在正确的数据集中是否唯一。
-
“ many_to_many”或“ m:m”:允许,但不进行检查。
-
注意
用于指定索引水平支撑on,left_on以及 right_on在0.23.0版加入参数。Series在版本0.24.0中添加了对合并命名对象的支持。
返回类型将与相同left。如果left是DataFrame或的名称,Series 并且right是的子类DataFrame,则返回类型仍为DataFrame。
merge是pandas命名空间中的一个函数,它也可以作为 DataFrame实例方法merge()使用,调用 DataFrame被隐式视为联接中的左侧对象。
相关join()方法在merge内部用于索引索引连接(默认情况下)和索引列连接。如果仅在索引上加入,则可能希望使用DataFrame.join来节省一些输入。
合并方法简要入门(关系代数)
诸如SQL之类的关系数据库的经验丰富的用户将熟悉用于描述两个类似于SQL表的结构(DataFrame对象)之间的联接操作的术语。需要考虑的几种情况非常重要:
-
一对一联接:例如,在两个
DataFrame对象的索引上联接时(必须包含唯一值)。 -
多对一联接:例如,将索引(唯一)联接到different中的一个或多个列时
DataFrame。 -
多对多联接:在列上联接列。
注意
在列上连接列时(可能是多对多连接),传递的DataFrame对象上的任何索引都将被丢弃。
值得花一些时间来理解多对多 连接案例的结果。在SQL /标准关系代数中,如果两个表中的键组合都出现多次,则结果表将具有关联数据的笛卡尔积。这是一个具有一个唯一键组合的非常基本的示例:
In [39]: left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
....: 'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3']})
....:
In [40]: right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
....: 'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']})
....:
In [41]: result = pd.merge(left, right, on='key')
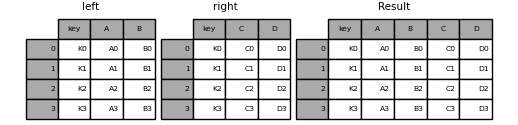
这是带有多个联接键的更复杂的示例。由于默认情况下,只有出现left和出现的关键right点(相交) how='inner'。
In [42]: left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
....: 'key2': ['K0', 'K1', 'K0', 'K1'],
....: 'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3']})
....:
In [43]: right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
....: 'key2': ['K0', 'K0', 'K0', 'K0'],
....: 'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']})
....:
In [44]: result = pd.merge(left, right, on=['key1', 'key2'])

的how到参数merge指定如何确定哪些键要被包括在所得到的表。如果左表或右表中都没有按键组合,则联接表中的值将为 NA。以下是how选项及其SQL等效名称的摘要:
|
合并方式 |
SQL连接名称 |
描述 |
|---|---|---|
|
|
|
仅使用左框中的关键点 |
|
|
|
仅从右框使用按键 |
|
|
|
使用两个框架中的键并集 |
|
|
|
使用两个帧的关键点交集 |
In [45]: result = pd.merge(left, right, how='left', on=['key1', 'key2'])
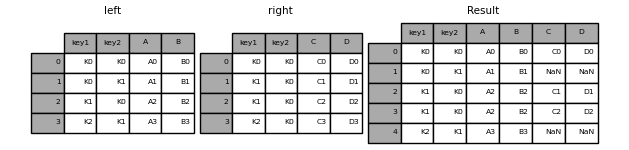
In [46]: result = pd.merge(left, right, how='right', on=['key1', 'key2'])

In [47]: result = pd.merge(left, right, how='outer', on=['key1', 'key2'])
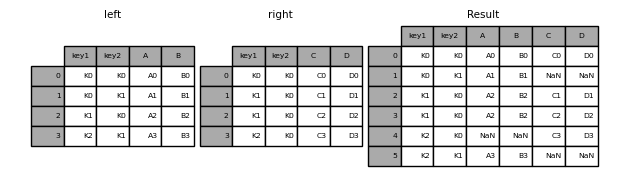
In [48]: result = pd.merge(left, right, how='inner', on=['key1', 'key2'])

如果MultiIndex的名称与DataFrame中的列相对应,则可以合并多索引的Series和DataFrame。Series.reset_index()合并之前,使用系列将Series转换为DataFrame ,如以下示例所示。
In [49]: df = pd.DataFrame({"Let": ["A", "B", "C"], "Num": [1, 2, 3]})
In [50]: df
Out[50]:
Let Num
0 A 1
1 B 2
2 C 3
In [51]: ser = pd.Series(
....: ["a", "b", "c", "d", "e", "f"],
....: index=pd.MultiIndex.from_arrays(
....: [["A", "B", "C"] * 2, [1, 2, 3, 4, 5, 6]], names=["Let", "Num"]
....: ),
....: )
....:
In [52]: ser
Out[52]:
Let Num
A 1 a
B 2 b
C 3 c
A 4 d
B 5 e
C 6 f
dtype: object
In [53]: pd.merge(df, ser.reset_index(), on=['Let', 'Num'])
Out[53]:
Let Num 0
0 A 1 a
1 B 2 b
2 C 3 c
这是另一个在DataFrames中具有重复联接键的示例:
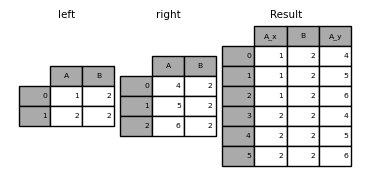
In [54]: left = pd.DataFrame({'A': [1, 2], 'B': [2, 2]})
In [55]: right = pd.DataFrame({'A': [4, 5, 6], 'B': [2, 2, 2]})
In [56]: result = pd.merge(left, right, on='B', how='outer')
警告
在重复键上进行联接/合并会导致返回的帧是行尺寸的乘积,这可能导致内存溢出。在加入大型DataFrame之前,用户有责任管理键中的重复值。
检查重复键
用户可以使用该validate参数自动检查其合并键中是否有意外的重复项。在合并操作之前检查键的唯一性,因此应防止内存溢出。检查密钥唯一性也是确保用户数据结构符合预期的好方法。
在以下示例中,Bright中 存在重复的值DataFrame。由于这不是validate参数中指定的一对一合并,因此 将引发异常。
In [57]: left = pd.DataFrame({'A' : [1,2], 'B' : [1, 2]})
In [58]: right = pd.DataFrame({'A' : [4,5,6], 'B': [2, 2, 2]})
In [53]: result = pd.merge(left, right, on='B', how='outer', validate="one_to_one")
...
MergeError: Merge keys are not unique in right dataset; not a one-to-one merge
如果用户知道右边的重复项,DataFrame但要确保左边的DataFrame中没有重复项,则可以改用该 validate='one_to_many'参数,这不会引发异常。
In [59]: pd.merge(left, right, on='B', how='outer', validate="one_to_many")
Out[59]:
A_x B A_y
0 1 1 NaN
1 2 2 4.0
2 2 2 5.0
3 2 2 6.0
该合并指标
merge()接受论点indicator。如果为True,_merge则将将一个名为Categorical-type的列添加到采用值的输出对象:
观察原点
_merge值仅在
'left'框架中合并关键点
left_only仅在
'right'框架中合并关键点
right_only在两个框架中合并关键点
both
In [60]: df1 = pd.DataFrame({'col1': [0, 1], 'col_left': ['a', 'b']})
In [61]: df2 = pd.DataFrame({'col1': [1, 2, 2], 'col_right': [2, 2, 2]})
In [62]: pd.merge(df1, df2, on='col1', how='outer', indicator=True)
Out[62]:
col1 col_left col_right _merge
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only
该indicator参数还将接受字符串参数,在这种情况下,指标函数将使用传递的字符串的值作为指标列的名称。
In [63]: pd.merge(df1, df2, on='col1', how='outer', indicator='indicator_column')
Out[63]:
col1 col_left col_right indicator_column
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only
合并dtypes
合并将保留联接键的dtype。
In [64]: left = pd.DataFrame({'key': [1], 'v1': [10]})
In [65]: left
Out[65]:
key v1
0 1 10
In [66]: right = pd.DataFrame({'key': [1, 2], 'v1': [20, 30]})
In [67]: right
Out[67]:
key v1
0 1 20
1 2 30
我们能够保留联接键:
In [68]: pd.merge(left, right, how='outer')
Out[68]:
key v1
0 1 10
1 1 20
2 2 30
In [69]: pd.merge(left, right, how='outer').dtypes
Out[69]:
key int64
v1 int64
dtype: object
当然,如果您缺少引入的值,那么生成的dtype将被转换。
In [70]: pd.merge(left, right, how='outer', on='key')
Out[70]:
key v1_x v1_y
0 1 10.0 20
1 2 NaN 30
In [71]: pd.merge(left, right, how='outer', on='key').dtypes
Out[71]:
key int64
v1_x float64
v1_y int64
dtype: object
合并将保留category人种的dtypes。另请参阅“类别”部分。
左框架。
In [72]: from pandas.api.types import CategoricalDtype
In [73]: X = pd.Series(np.random.choice(['foo', 'bar'], size=(10,)))
In [74]: X = X.astype(CategoricalDtype(categories=['foo', 'bar']))
In [75]: left = pd.DataFrame({'X': X,
....: 'Y': np.random.choice(['one', 'two', 'three'],
....: size=(10,))})
....:
In [76]: left
Out[76]:
X Y
0 bar one
1 foo one
2 foo three
3 bar three
4 foo one
5 bar one
6 bar three
7 bar three
8 bar three
9 foo three
In [77]: left.dtypes
Out[77]:
X category
Y object
dtype: object
正确的框架。
In [78]: right = pd.DataFrame({'X': pd.Series(['foo', 'bar'],
....: dtype=CategoricalDtype(['foo', 'bar'])),
....: 'Z': [1, 2]})
....:
In [79]: right
Out[79]:
X Z
0 foo 1
1 bar 2
In [80]: right.dtypes
Out[80]:
X category
Z int64
dtype: object
合并结果:
In [81]: result = pd.merge(left, right, how='outer')
In [82]: result
Out[82]:
X Y Z
0 bar one 2
1 bar three 2
2 bar one 2
3 bar three 2
4 bar three 2
5 bar three 2
6 foo one 1
7 foo three 1
8 foo one 1
9 foo three 1
In [83]: result.dtypes
Out[83]:
X category
Y object
Z int64
dtype: object
注意
类别dtype必须完全相同,这意味着相同的类别和有序属性。否则结果将强制为类别的dtype。
注意
与categorydtype合并相比,在相同的dtype上合并可能会表现出色object。
加入索引
DataFrame.join()是一种将两个可能具有不同索引的列DataFrames合并为单个结果 的便捷方法DataFrame。这是一个非常基本的示例:
In [84]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
....: 'B': ['B0', 'B1', 'B2']},
....: index=['K0', 'K1', 'K2'])
....:
In [85]: right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
....: 'D': ['D0', 'D2', 'D3']},
....: index=['K0', 'K2', 'K3'])
....:
In [86]: result = left.join(right)
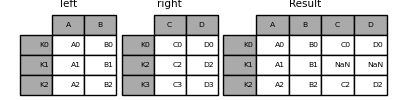
In [87]: result = left.join(right, how='outer')
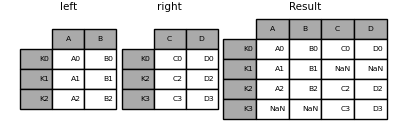
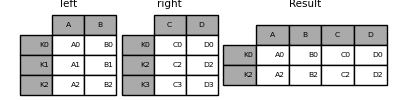
与上述相同,但带有how='inner'。
In [88]: result = left.join(right, how='inner')
此处的数据对齐在索引(行标签)上。使用merge指示其使用索引的附加参数可以实现相同的行为:
In [89]: result = pd.merge(left, right, left_index=True, right_index=True, how='outer')

In [90]: result = pd.merge(left, right, left_index=True, right_index=True, how='inner');

在索引上关键列
join()接受一个可选on参数,该参数可以是一列或多个列名,它指定传递的DataFrame内容将与中的该列对齐DataFrame。这两个函数调用是完全等效的:
left.join(right, on=key_or_keys)
pd.merge(left, right, left_on=key_or_keys, right_index=True,
how='left', sort=False)
显然,您可以选择任何一种更方便的形式。对于多对一连接(其中的一个DataFrame已通过连接键索引),使用join可能会更方便。这是一个简单的示例:
In [91]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3'],
....: 'key': ['K0', 'K1', 'K0', 'K1']})
....:
In [92]: right = pd.DataFrame({'C': ['C0', 'C1'],
....: 'D': ['D0', 'D1']},
....: index=['K0', 'K1'])
....:
In [93]: result = left.join(right, on='key')
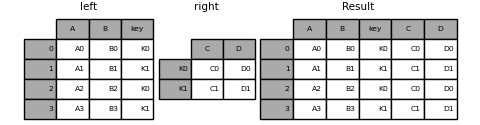
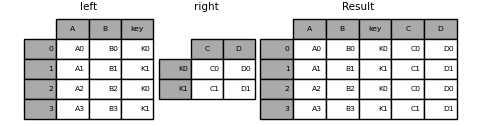
In [94]: result = pd.merge(left, right, left_on='key', right_index=True,
....: how='left', sort=False);
....:
要加入多个键,传递的DataFrame必须具有MultiIndex:
In [95]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3'],
....: 'key1': ['K0', 'K0', 'K1', 'K2'],
....: 'key2': ['K0', 'K1', 'K0', 'K1']})
....:
In [96]: index = pd.MultiIndex.from_tuples([('K0', 'K0'), ('K1', 'K0'),
....: ('K2', 'K0'), ('K2', 'K1')])
....:
In [97]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']},
....: index=index)
....:
现在,可以通过传递两个关键列名称来进行连接:
In [98]: result = left.join(right, on=['key1', 'key2'])
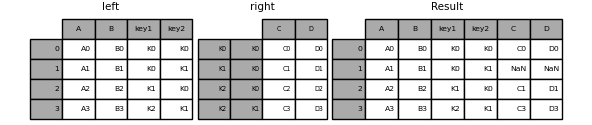
默认的DataFrame.join是执行左联接(对于Excel用户,本质上是“ VLOOKUP”操作),该联接仅使用在调用DataFrame中找到的键。其他联接类型(例如内部联接)也可以轻松执行:
In [99]: result = left.join(right, on=['key1', 'key2'], how='inner')
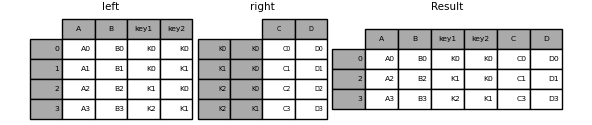
如您所见,这将删除所有不匹配的行。
加入单一指数为多指标
您可以将一个索引DataFrame与一个MultiIndexed级别连接DataFrame。级别将在单索引帧的索引名称与MultiIndexed帧的级别名称上匹配。
In [100]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
.....: 'B': ['B0', 'B1', 'B2']},
.....: index=pd.Index(['K0', 'K1', 'K2'], name='key'))
.....:
In [101]: index = pd.MultiIndex.from_tuples([('K0', 'Y0'), ('K1', 'Y1'),
.....: ('K2', 'Y2'), ('K2', 'Y3')],
.....: names=['key', 'Y'])
.....:
In [102]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
.....: 'D': ['D0', 'D1', 'D2', 'D3']},
.....: index=index)
.....:
In [103]: result = left.join(right, how='inner')
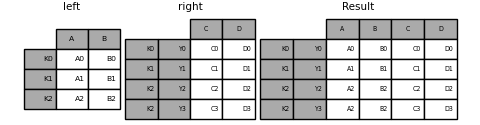
这是等效的,但是比它更冗长,存储效率更高/更快。
In [104]: result = pd.merge(left.reset_index(), right.reset_index(),
.....: on=['key'], how='inner').set_index(['key','Y'])
.....:

有两个MultiIndexes加入
只要在连接中完全使用了右参数的索引,并且该参数是左参数中索引的子集,就可以用有限的方式来支持它,如下例所示:
In [105]: leftindex = pd.MultiIndex.from_product([list('abc'), list('xy'), [1, 2]],
.....: names=['abc', 'xy', 'num'])
.....:
In [106]: left = pd.DataFrame({'v1': range(12)}, index=leftindex)
In [107]: left
Out[107]:
v1
abc xy num
a x 1 0
2 1
y 1 2
2 3
b x 1 4
2 5
y 1 6
2 7
c x 1 8
2 9
y 1 10
2 11
In [108]: rightindex = pd.MultiIndex.from_product([list('abc'), list('xy')],
.....: names=['abc', 'xy'])
.....:
In [109]: right = pd.DataFrame({'v2': [100 * i for i in range(1, 7)]}, index=rightindex)
In [110]: right
Out[110]:
v2
abc xy
a x 100
y 200
b x 300
y 400
c x 500
y 600
In [111]: left.join(right, on=['abc', 'xy'], how='inner')
Out[111]:
v1 v2
abc xy num
a x 1 0 100
2 1 100
y 1 2 200
2 3 200
b x 1 4 300
2 5 300
y 1 6 400
2 7 400
c x 1 8 500
2 9 500
y 1 10 600
2 11 600
如果不满足该条件,则可以使用以下代码完成具有两个多索引的联接。
In [112]: leftindex = pd.MultiIndex.from_tuples([('K0', 'X0'), ('K0', 'X1'),
.....: ('K1', 'X2')],
.....: names=['key', 'X'])
.....:
In [113]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
.....: 'B': ['B0', 'B1', 'B2']},
.....: index=leftindex)
.....:
In [114]: rightindex = pd.MultiIndex.from_tuples([('K0', 'Y0'), ('K1', 'Y1'),
.....: ('K2', 'Y2'), ('K2', 'Y3')],
.....: names=['key', 'Y'])
.....:
In [115]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
.....: 'D': ['D0', 'D1', 'D2', 'D3']},
.....: index=rightindex)
.....:
In [116]: result = pd.merge(left.reset_index(), right.reset_index(),
.....: on=['key'], how='inner').set_index(['key', 'X', 'Y'])
.....:
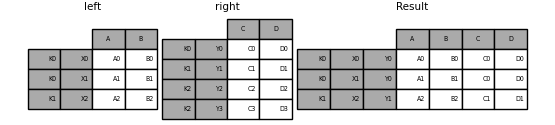
合并列和索引级别的组合
0.23版中的新功能。
字符串作为传递on,left_on和right_on参数可以指列名或索引级别名称。这样就可以DataFrame在索引级别和列的组合上合并 实例,而无需重置索引。
In [117]: left_index = pd.Index(['K0', 'K0', 'K1', 'K2'], name='key1')
In [118]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
.....: 'B': ['B0', 'B1', 'B2', 'B3'],
.....: 'key2': ['K0', 'K1', 'K0', 'K1']},
.....: index=left_index)
.....:
In [119]: right_index = pd.Index(['K0', 'K1', 'K2', 'K2'], name='key1')
In [120]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
.....: 'D': ['D0', 'D1', 'D2', 'D3'],
.....: 'key2': ['K0', 'K0', 'K0', 'K1']},
.....: index=right_index)
.....:
In [121]: result = left.merge(right, on=['key1', 'key2'])
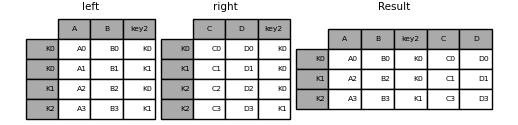
注意
当将DataFrame合并到与两个框架中的索引级别都匹配的字符串上时,索引级别将保留为结果DataFrame中的索引级别。
注意
当仅使用MultiIndex的某些级别合并DataFrame时,多余的级别将从结果合并中删除。为了保留这些级别,请reset_index在执行合并之前将这些级别名称用于将这些级别移动到列。
注意
如果字符串与列名和索引级名称都匹配,则会发出警告,并且列优先。这将在将来的版本中导致歧义错误。
值列重叠
mergesuffixes参数将字符串列表的元组附加到输入DataFrames中重叠的列名称上,以消除结果列的歧义:
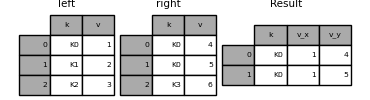
In [122]: left = pd.DataFrame({'k': ['K0', 'K1', 'K2'], 'v': [1, 2, 3]})
In [123]: right = pd.DataFrame({'k': ['K0', 'K0', 'K3'], 'v': [4, 5, 6]})
In [124]: result = pd.merge(left, right, on='k')
In [125]: result = pd.merge(left, right, on='k', suffixes=('_l', '_r'))
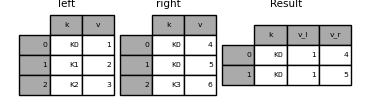
DataFrame.join()具有lsuffix和rsuffix行为相似的参数。
In [126]: left = left.set_index('k')
In [127]: right = right.set_index('k')
In [128]: result = left.join(right, lsuffix='_l', rsuffix='_r')

连接多个DataFrames
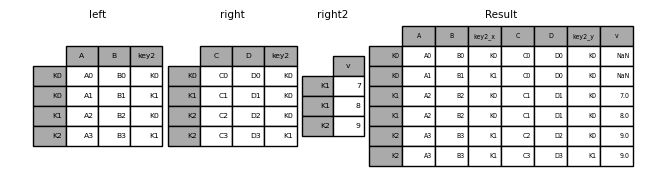
DataFrames也可以传递一个列表或元组以join() 将它们连接到它们的索引上。
In [129]: right2 = pd.DataFrame({'v': [7, 8, 9]}, index=['K1', 'K1', 'K2'])
In [130]: result = left.join([right, right2])
将Series或DataFrame列中的值合并在一起
另一个相当常见的情况是有两个像索引(或类似索引)Series或DataFrame对象和从值想“补丁”值在一个对象匹配的其他指数。这是一个例子:
In [131]: df1 = pd.DataFrame([[np.nan, 3., 5.], [-4.6, np.nan, np.nan],
.....: [np.nan, 7., np.nan]])
.....:
In [132]: df2 = pd.DataFrame([[-42.6, np.nan, -8.2], [-5., 1.6, 4]],
.....: index=[1, 2])
.....:
为此,请使用以下combine_first()方法:
In [133]: result = df1.combine_first(df2)
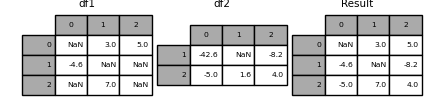
请注意,DataFrame如果左侧缺少这些值,则此方法仅采用右侧的值DataFrame。相关方法update()更改了非NA值:
In [134]: df1.update(df2)

时间序列友好合并
合并排序的数据
一个merge_ordered()功能允许组合时间序列和其他有序数据。特别是,它具有一个可选fill_method关键字来填充/内插丢失的数据:
In [135]: left = pd.DataFrame({'k': ['K0', 'K1', 'K1', 'K2'],
.....: 'lv': [1, 2, 3, 4],
.....: 's': ['a', 'b', 'c', 'd']})
.....:
In [136]: right = pd.DataFrame({'k': ['K1', 'K2', 'K4'],
.....: 'rv': [1, 2, 3]})
.....:
In [137]: pd.merge_ordered(left, right, fill_method='ffill', left_by='s')
Out[137]:
k lv s rv
0 K0 1.0 a NaN
1 K1 1.0 a 1.0
2 K2 1.0 a 2.0
3 K4 1.0 a 3.0
4 K1 2.0 b 1.0
5 K2 2.0 b 2.0
6 K4 2.0 b 3.0
7 K1 3.0 c 1.0
8 K2 3.0 c 2.0
9 K4 3.0 c 3.0
10 K1 NaN d 1.0
11 K2 4.0 d 2.0
12 K4 4.0 d 3.0
合并ASOF
Amerge_asof()与有序左联接相似,不同之处在于我们在最接近的键而不是相等的键上进行匹配。对于中的每一行left DataFrame,我们选择right DataFrame其on键小于左键的最后一行。两个DataFrame都必须按键排序。
可选地,asof合并可以执行逐组合并。by除了键上最接近的匹配之外,此 键均等地匹配on键。
例如; 我们可能有trades,quotes我们想asof 将它们合并。
In [138]: trades = pd.DataFrame({
.....: 'time': pd.to_datetime(['20160525 13:30:00.023',
.....: '20160525 13:30:00.038',
.....: '20160525 13:30:00.048',
.....: '20160525 13:30:00.048',
.....: '20160525 13:30:00.048']),
.....: 'ticker': ['MSFT', 'MSFT',
.....: 'GOOG', 'GOOG', 'AAPL'],
.....: 'price': [51.95, 51.95,
.....: 720.77, 720.92, 98.00],
.....: 'quantity': [75, 155,
.....: 100, 100, 100]},
.....: columns=['time', 'ticker', 'price', 'quantity'])
.....:
In [139]: quotes = pd.DataFrame({
.....: 'time': pd.to_datetime(['20160525 13:30:00.023',
.....: '20160525 13:30:00.023',
.....: '20160525 13:30:00.030',
.....: '20160525 13:30:00.041',
.....: '20160525 13:30:00.048',
.....: '20160525 13:30:00.049',
.....: '20160525 13:30:00.072',
.....: '20160525 13:30:00.075']),
.....: 'ticker': ['GOOG', 'MSFT', 'MSFT',
.....: 'MSFT', 'GOOG', 'AAPL', 'GOOG',
.....: 'MSFT'],
.....: 'bid': [720.50, 51.95, 51.97, 51.99,
.....: 720.50, 97.99, 720.50, 52.01],
.....: 'ask': [720.93, 51.96, 51.98, 52.00,
.....: 720.93, 98.01, 720.88, 52.03]},
.....: columns=['time', 'ticker', 'bid', 'ask'])
.....:
In [140]: trades
Out[140]:
time ticker price quantity
0 2016-05-25 13:30:00.023 MSFT 51.95 75
1 2016-05-25 13:30:00.038 MSFT 51.95 155
2 2016-05-25 13:30:00.048 GOOG 720.77 100
3 2016-05-25 13:30:00.048 GOOG 720.92 100
4 2016-05-25 13:30:00.048 AAPL 98.00 100
In [141]: quotes
Out[141]:
time ticker bid ask
0 2016-05-25 13:30:00.023 GOOG 720.50 720.93
1 2016-05-25 13:30:00.023 MSFT 51.95 51.96
2 2016-05-25 13:30:00.030 MSFT 51.97 51.98
3 2016-05-25 13:30:00.041 MSFT 51.99 52.00
4 2016-05-25 13:30:00.048 GOOG 720.50 720.93
5 2016-05-25 13:30:00.049 AAPL 97.99 98.01
6 2016-05-25 13:30:00.072 GOOG 720.50 720.88
7 2016-05-25 13:30:00.075 MSFT 52.01 52.03
默认情况下,我们采用引号的形式。
In [142]: pd.merge_asof(trades, quotes,
.....: on='time',
.....: by='ticker')
.....:
Out[142]:
time ticker price quantity bid ask
0 2016-05-25 13:30:00.023 MSFT 51.95 75 51.95 51.96
1 2016-05-25 13:30:00.038 MSFT 51.95 155 51.97 51.98
2 2016-05-25 13:30:00.048 GOOG 720.77 100 720.50 720.93
3 2016-05-25 13:30:00.048 GOOG 720.92 100 720.50 720.93
4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN
我们只在2ms报价时间和交易时间之间进行交易。
In [143]: pd.merge_asof(trades, quotes,
.....: on='time',
.....: by='ticker',
.....: tolerance=pd.Timedelta('2ms'))
.....:
Out[143]:
time ticker price quantity bid ask
0 2016-05-25 13:30:00.023 MSFT 51.95 75 51.95 51.96
1 2016-05-25 13:30:00.038 MSFT 51.95 155 NaN NaN
2 2016-05-25 13:30:00.048 GOOG 720.77 100 720.50 720.93
3 2016-05-25 13:30:00.048 GOOG 720.92 100 720.50 720.93
4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN
我们仅在10ms报价时间和交易时间之间进行结算,并且不包括准时匹配。请注意,尽管我们排除了(引号)的完全匹配项,但先前的引号确实会传播到该时间点。
In [144]: pd.merge_asof(trades, quotes,
.....: on='time',
.....: by='ticker',
.....: tolerance=pd.Timedelta('10ms'),
.....: allow_exact_matches=False)
.....:
Out[144]:
time ticker price quantity bid ask
0 2016-05-25 13:30:00.023 MSFT 51.95 75 NaN NaN
1 2016-05-25 13:30:00.038 MSFT 51.95 155 51.97 51.98
2 2016-05-25 13:30:00.048 GOOG 720.77 100 NaN NaN
3 2016-05-25 13:30:00.048 GOOG 720.92 100 NaN NaN
4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN
比较对象
使用compare()和compare()方法,您可以分别比较两个DataFrame或Series,并总结它们之间的差异。
V1.1.0中添加了此功能。
例如,您可能想要比较两个DataFrame并并排堆叠它们的差异。
In [145]: df = pd.DataFrame(
.....: {
.....: "col1": ["a", "a", "b", "b", "a"],
.....: "col2": [1.0, 2.0, 3.0, np.nan, 5.0],
.....: "col3": [1.0, 2.0, 3.0, 4.0, 5.0]
.....: },
.....: columns=["col1", "col2", "col3"],
.....: )
.....:
In [146]: df
Out[146]:
col1 col2 col3
0 a 1.0 1.0
1 a 2.0 2.0
2 b 3.0 3.0
3 b NaN 4.0
4 a 5.0 5.0
In [147]: df2 = df.copy()
In [148]: df2.loc[0, 'col1'] = 'c'
In [149]: df2.loc[2, 'col3'] = 4.0
In [150]: df2
Out[150]:
col1 col2 col3
0 c 1.0 1.0
1 a 2.0 2.0
2 b 3.0 4.0
3 b NaN 4.0
4 a 5.0 5.0
In [151]: df.compare(df2)
Out[151]:
col1 col3
self other self other
0 a c NaN NaN
2 NaN NaN 3.0 4.0
默认情况下,如果两个对应的值相等,它们将显示为NaN。此外,如果整个行/列中的所有值都将从结果中省略。其余差异将在列上对齐。
如果需要,可以选择将差异堆叠在行上。
In [152]: df.compare(df2, align_axis=0)
Out[152]:
col1 col3
0 self a NaN
other c NaN
2 self NaN 3.0
other NaN 4.0
如果您希望保留所有原始行和列,请将keep_shape参数设置为True。
In [153]: df.compare(df2, keep_shape=True)
Out[153]:
col1 col2 col3
self other self other self other
0 a c NaN NaN NaN NaN
1 NaN NaN NaN NaN NaN NaN
2 NaN NaN NaN NaN 3.0 4.0
3 NaN NaN NaN NaN NaN NaN
4 NaN NaN NaN NaN NaN NaN
您也可以保留所有原始值,即使它们相等。