首先查看js渲染前的html源码,发现放图片的位置是这样的
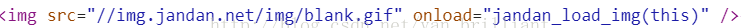
本该放地址的地方赫然放着blank.gif,并且在onload属性上绑定了一个jandan_load_img函数。这个jandan_load_img就成为本次爬虫的突破所在了。继续ctrl+shift+F全局搜索,找到这个函数
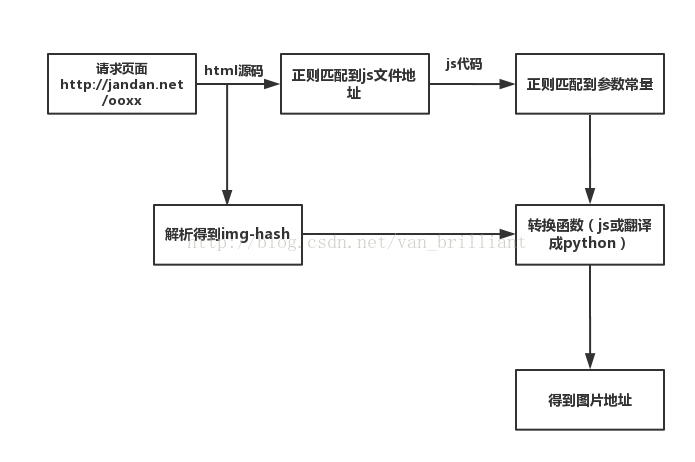
流程图:


import hashlib import base64 from bs4 import BeautifulSoup import requests import re import random import shutil import os import time import queue import threading import math ''' url解码 ''' def parse(imgHash, constant): ''' 以下是原来的解码方式,近日(2018/5/25)已被修改不再生效 q = 4 hashlib.md5() constant = md5(constant) o = md5(constant[0:16]) n = md5(constant[16:32]) l = imgHash[0:q] c = o + md5(o + l) imgHash = imgHash[q:] k = decode_base64(imgHash) h =list(range(256)) b = list(range(256)) for g in range(0,256): b[g] = ord(c[g % len(c)]) f=0 for g in range(0,256): f = (f+h[g]+b[g]) % 256 tmp = h[g] h[g] = h[f] h[f] = tmp result = "" p=0 f=0 for g in range(0,len(k)): p = (p + 1) % 256; f = (f + h[p]) % 256 tmp = h[p] h[p] = h[f] h[f] = tmp result += chr(k[g] ^ (h[(h[p] + h[f]) % 256])) result = result[26:] return result ''' return decode_base64(imgHash).decode('utf8') def md5(src): m = hashlib.md5() m.update(src.encode("utf8")) return m.hexdigest() def decode_base64(data): missing_padding = 4 - len(data) % 4 if missing_padding: data += '=' * missing_padding return base64.b64decode(data) headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36' } ''' 页面抓取类 ''' class Spider(threading.Thread): def __init__(self, pages, proxies, url_manager): threading.Thread.__init__(self) self.pages = pages self.proxies = proxies self.url_manager = url_manager def get_Page(self, page, proxies, url_manager): bs_page = BeautifulSoup(page, "lxml") ''' 获取js文件地址从而得到constant常量 ''' try: model = re.findall(r'.*<scriptssrc="//(cdn.jandan.net/static/min.*?)"></script>.*', page) jsfile_url = "http://" + model[len(model) - 1] # 页面上可能有两个地址,取最后一个匹配的地址 except Exception as e: print(e) jsfile = requests.get(jsfile_url, headers=headers, proxies=proxies, timeout=3).text constant = re.search(r'.*remove();varsc=w+(e,"(w+)".*', jsfile).group(1) ''' 向parse函数传入constant常量和img-hash得到图片地址 ''' for item in bs_page.select('.img-hash'): img_url = 'http:' + parse(item.text, constant) url_manager.addNewUrl(img_url) def run(self): for page in self.pages: self.get_Page(page, self.proxies, self.url_manager) ''' 程序入口 ''' def main(amount): url_manager = UrlManager() proxies = {'http': ''} # 尚未添加ip代理功能,程序已能正常运行 current_url = 'http://jandan.net/ooxx' # 当前页面url ''' 多线程抓取页面地址 ''' pages = [] # 所有待抓取页面 try: for i in range(amount): current_page = requests.get(current_url, headers=headers).text # 当前页面源码 pages.append(current_page) current_url = 'http:' + re.search(r'.*OldersComments"shref="(.*?)"sclass.*', current_page).group( 1) # 提取下个页面url except Exception as e: pass page_threads = [] t_amount = 10 if len(pages) > 10 else len(pages) # 页面抓取线程数 for i in range(t_amount): t = Spider(pages[math.ceil(int((len(pages)) / t_amount) * i):math.ceil(int((len(pages)) / t_amount) * (i + 1))], proxies, url_manager) page_threads.append(t) for t in page_threads: t.start() for t in page_threads: t.join() img_threads = [] for i in range(10): # 固定10个线程用于下载图片 t = Download(url_manager) img_threads.append(t) for t in img_threads: t.start() for t in img_threads: t.join() L = threading.Lock() ''' 图片下载类 ''' class Download(threading.Thread): def __init__(self, url_manager): threading.Thread.__init__(self) self.url_manager = url_manager self.pic_headers = headers self.pic_headers['Host'] = 'wx3.sinaimg.cn' def download_Img(self, url): isGif = re.match(r'(.*.sinaimg.cn/)(w+)(/.+.gif)', url) if isGif: url = isGif.group(1) + 'large' + isGif.group(3) extensionName = re.match(r'.*(.w+)', url).group(1) # 图片扩展名 L.acquire() if not os.path.exists('img'): os.mkdir('img') with open('img/' + str(len(os.listdir('./img'))) + extensionName, 'wb') as f: # headers['Host']='wx3.sinaimg.cn' f.write(requests.get(url, headers=self.pic_headers).content) f.close() L.release() def run(self): while not self.url_manager.isEmpty(): imgUrl = self.url_manager.getNewUrl() self.download_Img(imgUrl) self.url_manager.addOldUrl(imgUrl) ''' url仓库,提供url更新以及记录功能 ''' class UrlManager: def __init__(self): self.url_used = [] self.url_target = queue.Queue() if os.path.exists('url.txt'): with open('url.txt', 'r') as f: for eachline in f.readlines(): self.url_used.append(eachline.strip()) else: open("url.txt", 'w') def getNewUrl(self): return self.url_target.get() def isEmpty(self): return self.url_target.empty() def addNewUrl(self, newUrl): if newUrl in self.url_used: pass else: self.url_target.put(newUrl) def addOldUrl(self, oldUrl): self.url_used.append(oldUrl) with open('url.txt', 'a') as f: f.write(oldUrl + ' ') if __name__ == '__main__': amount = input('请输入抓取页数后按回车开始(小于100),从首页开始计数):') main(int(amount)) # 抓取首页开始的前amount页的图片 爬取代码