zookeeper是什么?
zookeeper是大数据hadoop生态圈中的一个框架,是一种用于分布式应用程序的高性能协调服务。注册中心是zookeeper的别名。
zookeeper是一个致力于开发和维护的开源服务器,作用于项目中的协调和控制功能。
zookeeper最早是hadoop生态圈中的一员,hadoop生态圈的框架都是动物,而zookeeper就是管理这些动物的,字面意思就是动物管理员,它负责监听各个框架的健康状况,服务器的调用方和生产方。在以往的项目中都是通过直接客户端直接访问服务器来进行交互式访问,而使用zookeeper后,客户端的请求发送到zookeeper,然后根据zookeeper的反馈再找服务器端。
zookeeper中存放了大量的数据,服务器端再zookeeper中注册服务,然后zookeeper就会定期向这些注册过的服务索要心跳,根据观察者模式,一旦检测到状态发生变化,就要向zookeeper注册过的服务器(观察者)应对处理的措施。
观察者模式:
观察者模式是一种设计模式,当对象间存在一对多关系时,则使用观察者模式(Observer Pattern)。比如,当一个对象被修改时,则会自动通知它的依赖对象。观察者模式属于行为型模式。再zookeeper中,zookeeper是被观察者,再zookeeper中注册的服务都是观察者。
zookeeper的使用场景?
zookeeper在之前只适用于hadoop,但是随着web项目越来越大,发展越来越快,zookeeper已经完全适应了web项目,在web项目中仍然起着协调和控制的作用。
zookeeper是以集群的形式存在,也就是三台服务器做同一件事,官方文档说明,zookeeper以奇数台为稳定,并且中间的一台为leader,也就是说至少需要三台(一台称之为单节点,不能称为集群)
为什么说奇数台最稳定?
与zookeeper的选举机制有关,zookeeper集群会选举一台服务器为leader,其他的都是follower,也就是一个领导者带领一群小弟做一件事。
配置zookeeper
1.官网下载zookeeper.tar.gz压缩包
2.新建三台虚拟机,并修改HOSTNAME,hosts,关闭防火墙,防火墙开机自启动,重启虚拟机
3.zookeeper集群之间要能够通信,因此需要配置免密钥登录(免密钥登录在前面有介绍: ssh-keygen -t rsa ssh-copy-id ip地址 )
4.下载jdk.tar.gz(因为zookeepre是apache公司的,apache的项目于必须运行在jdk环境中,因此需要配置jdk)
5.配置完免密钥登录后,测试是否各服务器之间是否联通,然后将jdk解压,并安装jdk,配置环境变量,测试环境变量是否配置成功(javac)
6.解压zookeeper压缩包,修改conf文件夹下的zoo_simple.cfg文件名称为zoo.cfg: mv zoo_simple.cfg zoo.cfg
7.在zookeeper的主目录中创建data文件夹
7.修改zoo.cfg文件,将 dataDir后的路径修改为刚创建的data文件夹的路径,并在末尾添加
server.1=zookeeper01:2888:3888 server.2=zookeeper02:2888:3888 server.3=zookeeper03:2888:3888
server.1:表示zookeeper集群中服务器的id,id是服务器的唯一标识,
zookeeper01:是服务器修改的HOSTNAME,也可以是IP地址
2888:是集群之间通讯所用的端口号
3888:是选举leader使用的端口号
8.在data文件夹下创建myid文件 touch myid ,并编辑文件,文件中存的是当前zookeeer的id,文件中只输入1保存退出。
在上一步中,server.1 1就是一个zookeeper服务器的id,这一步就是表明id为1的服务器是哪儿一台,myid中存放的就是本台服务器的id 1
9.使用scp命令将第一台服务器上的jdk以及环境变量配置文件/etc/profile,以及zookeeper文件传输到其他的服务器:
scp -r /home/apps zookeeper02:/home/ (我的jdk以及zookeeper文件都在apps文件夹下,因此直接传文件夹过去)
scp -r /etc/profile zookeeper02:/etc/ 传递配置文件,也可以手动一个一个配,都需要重新加载文件 source /etc/profile
10.进入其他的服务器,测试jdk是否配置成功:javac
11.进入zookeeper目录下的bin目录,分别启动三台zookeeper cd /home/apps/zookeeperxxx/bin ./zkServer.sh start
 表示启动成功
表示启动成功
12.查看当前zookeeper的状态, ./zkServer.sh status

zookeeper集群启动成功后, 通过查看状态可以看到有一台为leader,其他的都为follower,而且leader为中间的一台。
zookeeper的选举机制:
zookeeper采用的是Paxos算法实现的选举机制,换句话说是半数选举机制
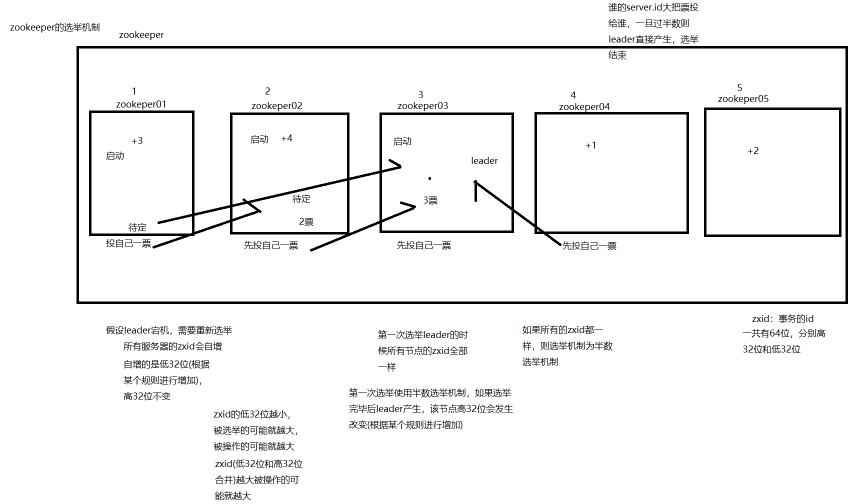
zookeeper在选举leader的时候是处于瘫痪状态的,如果当前zookeeper集群的leader宕机了,那么,就会重新选举leader,这次选举使用的并不在是半数选举,会通过zxid来选举leader,zxid是事务的id,有64位,高32位是一样的,低32位越小,被操作的可能性就越高。
假设现在启动三台zookeeper,然后中间的2号机为leader,如果2号突然宕机,那么根据半数选举的话,应该是3号成为leader的可能新大,但是实际上leader却是1号。
zookeper的CP特性:
数据一致性(集群上的每一个节点上的数据都要保持一致)
当服务消费者去zookeeper中查询服务生产者的时候,只会从leader服务器中查询数据;
当服务生产者到zookeeper中注册自己的时候,同样只会在leader中注册自己,那么就会有一个问题,只有leader中有数据,如果leader宕机,那么所有的数据都会丢失?
解决办法:leader会定期的将自己的数据(元数据)发送给follower(这种行为成为数据的同步);
leader会定期接受follower的心跳,follower也会定期向leader发送心跳。
如果follower1向leader中发送心跳,但是没有发送成功,这时follower1并不能确定leader是否已经宕机(单一的节点不能确定leader是否宕机,当所有的follower都无法发送心跳时,才可以确定宕机,需要通过选举机制重新选举)。
如果只有follower1发送心跳失败,但是follower3发送数据成功---->这时,leader就会默认等待30秒,如果30秒后,还是没有接收到follower1的心跳,就会宣布follower1宕机---->生成日志信息,通知程序员follower1宕机----->程序员抢修follower1,然后重启follower1----->leader将自己的数据同步给follower1。
问题:当leader宕机后,服务生产者是否还能在zookeeper中注册自己?
(leader宕机后,follower会重新选举leader(官方给的时间30~120s),选举leader过程中,zookeeper处于瘫痪状态)
可以继续注册,当leader宕机后,在重新选举期间,如果有服务注册进来,所有的服务都注册在leader上,但是leader宕机,这时还没有leader,那么zookeeper就会让服务注册在zxid低32位较小的那个节点上(因为低32位越小,成为leader的可能性就越高),这样选举结束后,发现注册服务的节点并没有成为leader,那么就同步数据给其他的follower,如果没有成为leader,就将自己的数据共享给leader。
问题:当leader宕机后,如果服务消费者到zookeeper中查询数据时,是否能查询到数据?
可以查询到,但是zookeeper因为机制问题,会让服务消费者一直处于等待状态,等待leader选举完成
服务消费者进到zookeeper后会到leader中获取数据,但是这时leader宕机,没有leader,这是zookeeper就会拉住不让消费者走,它会让zxid低32位小的那个节点来接待消费者(因为该节点成为leader的可能性大),消费者会从这个节点中获取数据,服务注册时,也是注册在这个节点上,因此获取到的数据是比较新的数据,但是获取到数据后,并不让消费者走,而是要等待leader选举成功后,才会放消费者走(leader选举成功后,这时的消费者已经获取到数据了),这就会造成脏数据,这是zookeeper的缺陷。
问题:zookeeper机制的缺陷
接着上面的问题解决思路,如果在leader选举的过程中,消费者到leader中查询数据了,查询的同时,有很多的服务注册了进来,那么此时消费者获取到的是新的数据,当leader选举成功后,消费者看到的是新的数据,这时消费者刷新页面,再次到zookeeper中获取数据,这时已经有了leader,但是follower中的数据共享到leader也是需要时间的,假设此时follower中的数据还没有完全共享到leader中,这时消费者到eader中查询到的数据就是旧的数据(脏数据),消费者再次刷新,再次查询数据时,数据共享已经完成,leader返回的是新数据,这样就会出现 新数据----->旧数据-------->新数据,这是zookeeper所面临的问题。