1 什么是函数递归
函数递归调用(是一种特殊的嵌套调用):在调用一个函数的过程中,又直接或间接地调用了该函数本身
递归就是一个重复的过程,自己调用自己:
写一个死循环
def bar(): print('from bar') foo() def foo(): print('from foo') bar() bar() #代码报错。超过系统最大深度
写一个简单的递归:
def bar(): print('from bar') foo() def foo(): print('from foo') bar()
递归的应用场景:
只知道最后一个人的年龄,依次推测年龄
def age(n): if n == 1: return 26 return age(n-1) + 2 print(age(5))
写出递归的一个总结:明确递归的概念,递归就是自己调用自己。先写一个基本的循环,然后再明确一个结束的条件。
查看系统默认内递归的最大层数:
import sys print(sys.getrecursionlimit())#大概在998左右
手动指定递归的最大深度:
sys.setrecursionlimit(3000)
手动通过递归函数查看最大深度:
def func1(n): print('from func1',n) func1(n+1) func1(1)
循环打印取出嵌套列表中的值
l = [1,[2,[3,[4,[5,[6,[7,[8,[9,[10,[11,[12,[13,]]]]]]]]]]]]] l1=[] def num(l): for i in l: if type(i) is int: l1.append(i) else: num(i) num(l)
#[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]
两种函数顶替的方式:
1.pas 2....(英文状态下的三个省略号)
def index(): pass index def index(): ... index
总结:
递归必须要有两个明确的阶段:
递推:一层一层递归调用下去,强调每进入下一层递归问题的规模都必须有所减少
回溯:递归必须要有一个明确的结束条件,在满足该条件时结束递推
开始一层一层回溯
递归的精髓在于通过不断地重复逼近一个最终的结果
二、二分查找算法
二分查找算法 必须处理有序的列表
三、三元表达式:就是一个简写形式
三元表达式仅应用于:
1、条件成立返回 一个值
2、条件不成立返回 一个值
res=x if x > y else y
print(res)
三元表达式前的引导:
def max(x,y): if x>y: return x else: return y res=max(10,20) print(res)
三元表达式为:res= x if x>y else y
def max2(x,y): return x if x>y else y print(max2(10,11))
四、列表生成式
和三元表达式一样都是个简写的过程
首先,给一个列表中的每个值加上‘_sb’的字样
看看无列表生成式的样子:方法1
l=['wuxi','sll','zdq','abc'] a=[] for i in l: a.append('%s_sb'%i) print(a)
先定义一个空列表。然后循环取值,将通用格式:i_sb用格式化输入的方式写入新的列表
方法2:
a.append(i+'_sb')
列表生成式是如何简写的
l=['wuxi','sll','zdq','abc'] res=['%s_DSB'%name for name in l ] print(res)
#把循环出来的每一个值赋值给前面的name
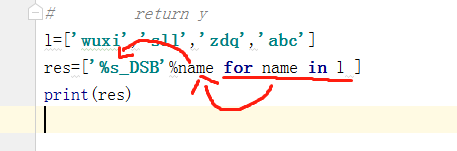
列表生成器挑选后缀是_NB的人。注意for后面的name和赋值的name是同一个。
l = ['tank_sb', 'nick_sb', 'oscar_sb', 'sean_sb','jason_NB'] res=[name for name in l if name.endswith('_sb')] print(res)

注意,加IF判断的列表生成式不支持加else的情况
五、字典生成式
l1 = ['name','password','hobby'] l2 = ['jason','123','DBJ','egon']
顾名思义就是生成字典。在案例中将两个列表的值一一对应放入字典中。
思路:将两个列表中的值取出来,再存入字典。
for循环取值l1的值,然而还需取l2的值,想到enumerate的作用是for循环取值的同时可以打印对应的索引,而该索引也可以用在l2上,最后通过d[k]=value的形式为字典赋值
d={} for j,k in enumerate(l1): d[k]=l2[i] print(d)
字典生成式
res={i,j for i,j in enumerate(l1)}
print(res)
字典生成式排除列表的某一项
res={i:j for i,j in enumerate(l1) if j !='name'}
print(res)
但此时的字典和以前不一样。
![]()
六、匿名函数
没有名字的函数。用于临时使用,用完就清除
一般函数形式:(写一个相加函数)
def sum(x,y): return x+y
用匿名函数来写:
与列表、字典生成式相同,都需要一个变量来接收返回值 lamdba函数的写法是写成一行 res=(lamdba x,y :x+y) print(res) 匿名函数的执行代码 执行lamdba函数只需在后面加括号以及参数即可 res=(lamdba x,y :x+y)(10,20)#别忘了lamdba也是函数,加括号就可以调用 print(res)
也就是说,平时函数怎么写,匿名写法也是一样,知识写成一行,调用写在后面即可
注意:匿名函数需要和内置函数一同使用。
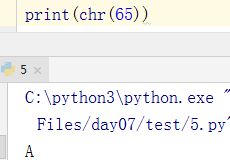
补充一个知识点:A—Z(65,90),A的arsic码最小
a—z(97,122)a的arsic码最小。通过如下方法可以查询
下面就是一些内置函数。
七、内置函数
map映射
l = [1,2,3,4,5,6] # print(list('hello')) print(list(map(lambda x:x+5,l))) # 基于for循环
zip拉链

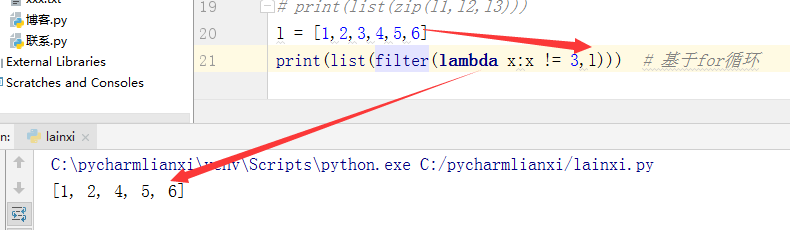
filter过滤。从列表中获取值,再过滤
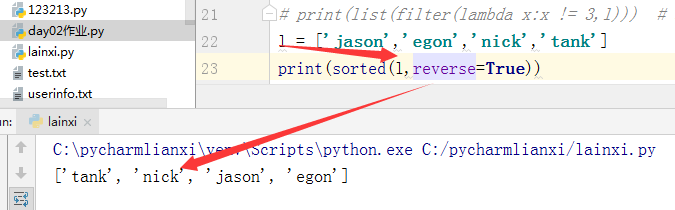
sorted排序。
reduce
