很多人都分不清Numpy,Scipy,pandas三个库的区别。
在这里简单分别一下:
- NumPy:数学计算库,以矩阵为基础的数学计算模块,包括基本的四则运行,方程式以及其他方面的计算什么的,纯数学;
- SciPy :科学计算库,有一些高阶抽象和物理模型,在NumPy基础上,封装了一层,没有那么纯数学,提供方法直接计算结果; 比如:
- 做个傅立叶变换,这是纯数学的,用Numpy;
- 做个滤波器,这属于信号处理模型了,用Scipy。
- Pandas:提供名为DataFrame的数据结构,比较契合统计分析中的表结构,做数据分析用的,主要是做表格数据呈现。
目前来说,随着Pandas更新,Numpy大部分功能已经直接和Pandas融合了。
如果想了解Numpy的话,可点击阅读《Python之Numpy的基础及进阶函数(图文)》。
但如果你不是纯数学专业,而且想做数据分析的话,尝试着从 Pandas 入手比较好。
接下来讲Pandas。
1数据结构
- Series:一维数组,与Numpy中的一维array类似。
- Time- Series:以时间为索引的Series。
- DataFrame:二维的表格型数据结构。可以将DataFrame理解为Series的容器。
- Panel :三维的数组,可以理解为DataFrame的容器。
# 导入别名 import pandas as pd pd.Series([1,2,3,4])
2数据读取
2.1 csv文件读取
read_csv(filepath_or_buffer, sep=',', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression='infer', thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0, escapechar=None, comment=None, encoding=None, dialect=None, tupleize_cols=False, error_bad_lines=True, warn_bad_lines=True, skipfooter=0, skip_footer=0, doublequote=True, delim_whitespace=False, as_recarray=False, compact_ints=False, use_unsigned=False, low_memory=True, buffer_lines=None, memory_map=False, float_precision=None)
- filepath_or_buffer:文件路径,建议使用相对路径
- header: 默认自动识别首行为列名(特征名),在数据没有列名的情况下 header = none, 还可以设置为其他行,例如 header = 5 表示索引位置为5的行作为起始列名
- sep: 表示csv文件的分隔符,默认为','
- names: 表示设置的字段名,默认为'infer'
- index_col:表示作为索引的列,默认为0-行数的等差数列。
- engine:表示解析引擎,可以为'c'或者'python'
- encoding:表示文件的编码,默认为'utf-8'。
- nrows:表示读取的行数,默认为全部读取
# 读取csv,参数可删 data = pd.read_csv('./data/test.csv',sep = ',',header = 'infer',names = range(5,18),index_col = [0,2],engine = 'python',encoding = 'gbk',nrows = 100)
# 读取csv,参数可删 data = pd.read_table('./data/test.csv',sep = ',',header = 'infer',names = range(5,18),index_col = [0,2],engine = 'python',encoding = 'gbk',nrows = 100)
2.2Excel 数据读取
read_excel(io, sheetname=0, header=0, skiprows=None, skip_footer=0, index_col=None, names=None, parse_cols=None, parse_dates=False, date_parser=None, na_values=None, thousands=None, convert_float=True, has_index_names=None, converters=None, dtype=None, true_values=None, false_values=None, engine=None, squeeze=False, **kwds)
- io:文件路径+全称,无默认
- sheetname:工作簿的名字,默认为0
- header: 默认自动识别首行为列名(特征名),在数据没有列名的情况下 header = none, 还可以设置为其他行,例如 header = 5 表示索引位置为5的行作为起始列名
- names: 表示设置的字段名,默认为'infer'
- index_col:表示作为索引的列,默认为0-行数的等差数列
- engine:表示解析引擎,可以为'c'或者'python'
data = pd.read_excel('./data/test.xls',sheetname='原始数据',header = 0,index_col = [5,6])
2.3数据库数据读取
- read_sql_query(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, chunksize=None)
- sql:表示抽取数据的SQL语句,例如'select * from 表名'
- con:表示数据库连接的名称
- index_col:表示作为索引的列,默认为0-行数的等差数列
- read_sql_table(table_name, con, schema=None, index_col=None, coerce_float=True, parse_dates=None, columns=None, chunksize=None)
- table_name:表示抽取数据的表名
- con:表示数据库连接的名称
- index_col:表示作为索引的列,默认为0-行数的等差数列
- columns:数据库数据读取后的列名。
- read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
- sql:表示抽取数据的表名或者抽取数据的SQL语句,例如'select * from 表名'
- con:表示数据库连接的名称
- index_col:表示作为索引的列,默认为0-行数的等差数列
- columns:数据库数据读取后的列名。
建议:用前两个
# 读取数据库 from sqlalchemy import create_engine conn = create_engine('mysql+pymysql://root:root@127.0.0.1/test?charset=utf8', encoding='utf-8', echo=True) # data1 = pd.read_sql_query('select * from data', con=conn) # print(data1.head()) data2 = pd.read_sql_table('data', con=conn) print(data2.tail()) print(data2['X'][1])
数据库连接字符串各参数说明
'mysql+pymysql://root:root@127.0.0.1/test?charset=utf8'
连接器://用户名:密码@数据库所在IP/访问的数据库名称?字符集
3数据写出
3.1将数据写出为csv
DataFrame.to_csv(path_or_buf=None, sep=',', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression=None, quoting=None, quotechar='"', line_terminator=' ', chunksize=None, tupleize_cols=False, date_format=None, doublequote=True, escapechar=None, decimal='.')
- path_or_buf:数据存储路径,含文件全名例如'./data.csv'
- sep:表示数据存储时使用的分隔符
- header:是否导出列名,True导出,False不导出
- index: 是否导出索引,True导出,False不导出
- mode:数据导出模式,'w'为写
- encoding:数据导出的编码
import pandas as pd data.to_csv('data.csv',index = False)
3.2将数据写出为excel
DataFrame.to_excel(excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None)
- excel_writer:数据存储路径,含文件全名例如'./data.xlsx'
- sheet_name:表示数据存储的工作簿名称
- header:是否导出列名,True导出,False不导出
- index: 是否导出索引,True导出,False不导出
- encoding:数据导出的编码
data.to_excel('data.xlsx',index=False)
3.3将数据写入数据库
DataFrame.to_sql(name, con, flavor=None, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None)
- name:数据存储表名
- con:表示数据连接
- if_exists:判断是否已经存在该表,'fail'表示存在就报错;'replace'表示存在就覆盖;'append'表示在尾部追加
- index: 是否导出索引,True导出,False不导出
from sqlalchemy import create_engine conn =create_engine('mysql+pymysql://root:root@127.0.0.1/data?charset=utf8', encoding='utf-8', echo=True) data.to_sql('data',con = conn)
4数据处理
4.1数据查看
# 查看前5行,5为数目,不是索引,默认为5 data.head() # 查看最后6行,6为数目,不是索引,默认为5 data.tail(6) # 查看数据的形状 data.shape # 查看数据的列数,0为行1位列 data.shape[1] # 查看所有的列名 data.columns # 查看索引 data.index # 查看每一列数据的类型 data.dtypes # 查看数据的维度 data.ndim
## 查看数据基本情况 data.describe() ''' count:非空值的数目 mean:数值型数据的均值 std:数值型数据的标准差 min:数值型数据的最小值 25%:数值型数据的下四分位数 50%:数值型数据的中位数 75%:数值型数据的上四分位数 max:数值型数据的最大值 '''
4.2数据索引
# 取出单独某一列 X = data['X'] # 取出多列 XY = data[['X','Y']] # 取出某列的某一行 data['X'][1] # 取出某列的某几行 data['X'][:10] # 取出某几列的某几行 data[['X','Y']][:10]
# loc方法索引 ''' DataFrame.loc[行名,列名] ''' # 取出某几列的某一行 data.loc[1,['X','月份']] # 取出某几列的某几行(连续) data.loc[1:5,['X','月份']] # 取出某几列的某几行(连续) data.loc[[1,3,5],['X','月份']] # 取出 x ,FFMC ,DC的0-20行所有索引名称为偶数的数据 data.loc[range(0,21,2),['X','FFMC','DC']]
# iloc方法索引 ''' DataFrame.iloc[行位置,列位置] ''' # 取出某几列的某一行 data.iloc[1,[1,4]] # 取出列位置为偶数,行位置为0-20的偶数的数据 data.iloc[0:21:2,0:data.shape[1]:2]
# ix方法索引 ''' DataFrame.ix[行位置/行名,列位置/列名] ''' ## 取出某几列的某一行 data.ix[1:4,[1,4]] data.ix[1:4,1:4]
loc,iloc,ix的区别
- loc使用名称索引,闭区间
- iloc使用位置索引,前闭后开区间
- ix使用名称或位置索引,且优先识别名称,其区间根据名称/位置来改变
综合上述所言,不建议使用ix,容易发生混淆的情况,并且运行效率低于loc和iloc,pandas考虑在后期会移除这一索引方法
4.3数据修改
# 修改列名 list1 = list(data.columns) list1[0] = '第一列' data.columns = list1 data['新增列'] = True data.loc['新增一行',:] = True data.drop('新增列',axis=1,inplace=True) data.drop('新增一行',axis=0,inplace=True)
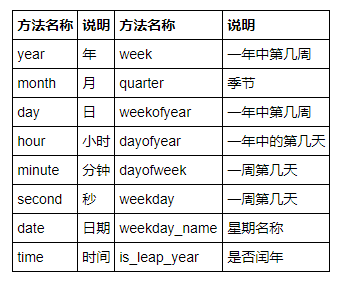
import pandas as pd data = pd.read_excel('./data/test.xls') # 时间类型数据转换 data['发生时间'] = pd.to_datetime(data['发生时间'],format='%Y%m%d%H%M%S') # 提取day data.loc[1,'发生时间'].day # 提取日期信息新建一列 data['日期'] = [i.day for i in data['发生时间']] year_data = [i.is_leap_year for i in data['发生时间']]
4.4分组聚合
4.4.1分组
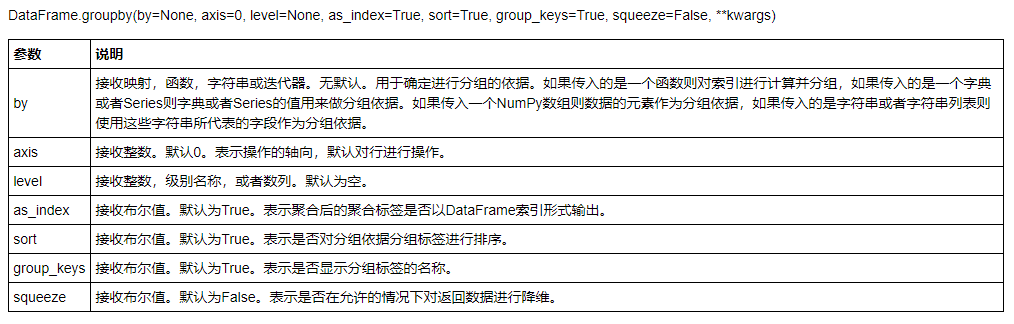
# 分组 group1 = data.groupby('性别') group2 = data.groupby(['入职时间','性别']) # 查看有多少组 group1.size()
笔记:
用groupby方法分组后的结果并不能直接查看,而是被存在内存中,输出的是内存地址。实际上分组后的数据对 象GroupBy类似Series与DataFrame,是pandas提供的一种对象。
4.4.2Groupby对象常见方法
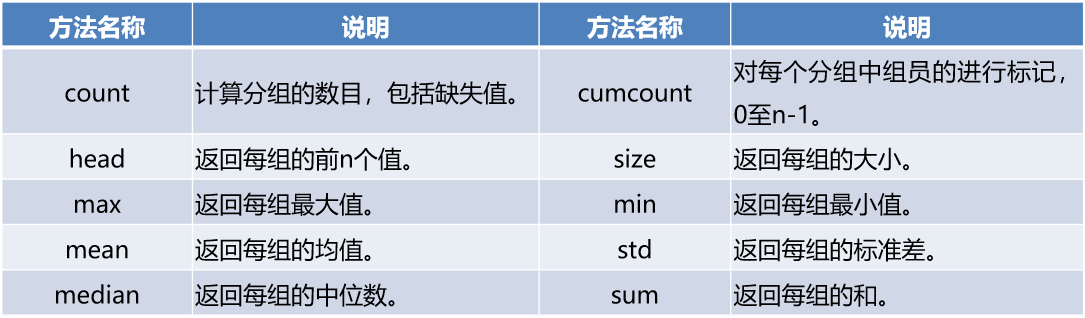
4.4.3Grouped对象的agg方法
Grouped.agg(函数或包含了字段名和函数的字典)
# 第一种情况 group[['年龄','工资']].agg(min) # 对不同的列进行不同的聚合操作 group.agg({'年龄':max,'工资':sum}) # 上述过程中使用的函数均为系统math库所带的函数,若需要使用pandas的函数则需要做如下操作 group.agg({'年龄':lambda x:x.max(),'工资':lambda x:x.sum()})
4.4.4Grouped对象的apply聚合方法
Grouped.apply(函数操作)
只能对所有列执行同一种操作
group.apply(lambda x:x.max())
4.4.5Grouped对象的transform方法
grouped.transform(函数操作)
transform操作时的对象不再是每一组,而是每一个元素
# 每一空添加字符 group['年龄'].transform(lambda x: x.astype(str)+'岁').head() # 组内标准化 group1['工资'].transform(lambda x:(x.mean()-x.min())/(x.max()-x.min())).head()