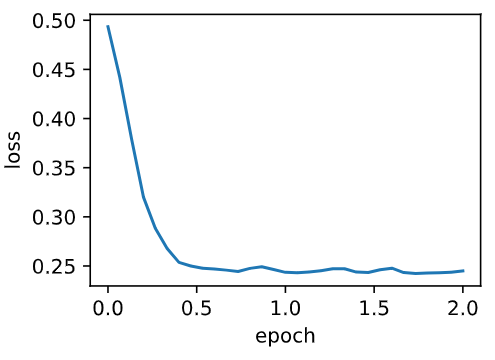
%matplotlib inline from mxnet import nd import numpy as np from mxnet import autograd,gluon,init,nd from mxnet.gluon import nn,data as gdata,loss as gloss import time def get_data(): data = np.genfromtxt('./data/airfoil_self_noise.dat', delimiter=' ') data = (data - data.mean(axis=0)) / data.std(axis=0) return nd.array(data[:1500, :-1]), nd.array(data[:1500, -1]) features, labels = get_data() features[0] labels[0] # 定义网络 def linreg(X,w,b): return nd.dot(X,w) + b # 平方损失 def squared_loss(y_hat,y): return (y_hat - y.reshape(y_hat.shape))**2/2 # 初始化参数 def init_momentum_states(): v_w = nd.zeros((features.shape[1], 1)) v_b = nd.zeros(1) return (v_w, v_b) # params [w,b] # states [v_w,v_b] 初始化状态 # hyperparams {'lr':0.02,'momentum':0.5} def sgd_momentum(params, states, hyperparams): for p, v in zip(params, states): v[:] = hyperparams['momentum'] * v + hyperparams['lr'] * p.grad p[:] -= v def train(trainer_fn, states, hyperparams, features, labels, batch_size=10, num_epochs=2): # 初始化模型。 net, loss = gb.linreg, gb.squared_loss w = nd.random.normal(scale=0.01, shape=(features.shape[1], 1)) b = nd.zeros(1) w.attach_grad() b.attach_grad() def eval_loss(): return loss(net(features, w, b), labels).mean().asscalar() ls = [eval_loss()] data_iter = gdata.DataLoader( gdata.ArrayDataset(features, labels), batch_size, shuffle=True) for _ in range(num_epochs): start = time.time() for batch_i, (X, y) in enumerate(data_iter): with autograd.record(): l = loss(net(X, w, b), y).mean() # 使用平均损失。 l.backward() trainer_fn([w, b], states, hyperparams) # 迭代模型参数。 if (batch_i + 1) * batch_size % 100 == 0: ls.append(eval_loss()) # 每 100 个样本记录下当前训练误差。 # 打印结果和作图。 print('loss: %f, %f sec per epoch' % (ls[-1], time.time() - start)) gb.set_figsize() gb.plt.plot(np.linspace(0, num_epochs, len(ls)), ls) gb.plt.xlabel('epoch') gb.plt.ylabel('loss') train(trainer_fn=sgd_momentum,states= init_momentum_states(),hyperparams={'lr': 0.02, 'momentum': 0.5}, features=features, labels=labels) train(sgd_momentum,init_momentum_states(),{'lr':0.02,'momentum':0.9},features,labels) train(sgd_momentum,init_momentum_states(),{'lr':0.004,'momentum':0.9},features,labels)


gluon 版:
def train_gluon(trainer_name,trainer_hyperparams,features,labels,batch_size=10,num_epochs=2): # 初始化模型 net = nn.Sequential() net.add(nn.Dense(1)) net.initialize(init.Normal(sigma=0.01)) loss = gloss.L2Loss() def eval_loss(): return loss(net(features),labels).mean().asscalar() ls = [eval_loss()] data_iter = gdata.DataLoader(gdata.ArrayDataset(features,labels),batch_size,shuffle=True) # 创建 Trainer 实例迭代模型参数 trainer = gluon.Trainer(net.collect_params(),trainer_name,trainer_hyperparams) for _ in range(num_epochs): start = time.time() for batch_i, (X,y) in enumerate(data_iter): with autograd.record(): l = loss(net(X),y) l.backward() trainer.step(batch_size) if (batch_i + 1) * batch_size % 100 ==0: ls.append(eval_loss()) # 打印结果和作图。 print('loss: %f, %f sec per epoch' % (ls[-1], time.time() - start)) gb.set_figsize() gb.plt.plot(np.linspace(0, num_epochs, len(ls)), ls) gb.plt.xlabel('epoch') gb.plt.ylabel('loss') train_gluon('sgd',{'learning_rate':0.004,'momentum':0.9},features,labels)
